In this article I am going to explain an entire concept that I have spelled out in pieces. This is something that I think is evident of the times were are in and where we are going.
Generative AI is the buzz and it is valid. While this technology is not the Holy Grail for humanity, it is some powerful stuff. On its own, it is not likely to take us to superintelligence. By the same token, it will not destroy humanity.
For the moment, we are confined to language models. This is evolving into the generation of images, audio, and video. When you consider the impact of that on society, it is powerful stuff.
At the core of this is data. This is taking on even more meaning as this technology evolves. We know digital platforms have accumulated data for decades. There was value in it, mostly by tying it to advertising.
As they say, you ain't seen nothing yet.
For this reason, the focus has changed completely. monetization is still the key but the process is altered.
This is where the data feedback loop enters.
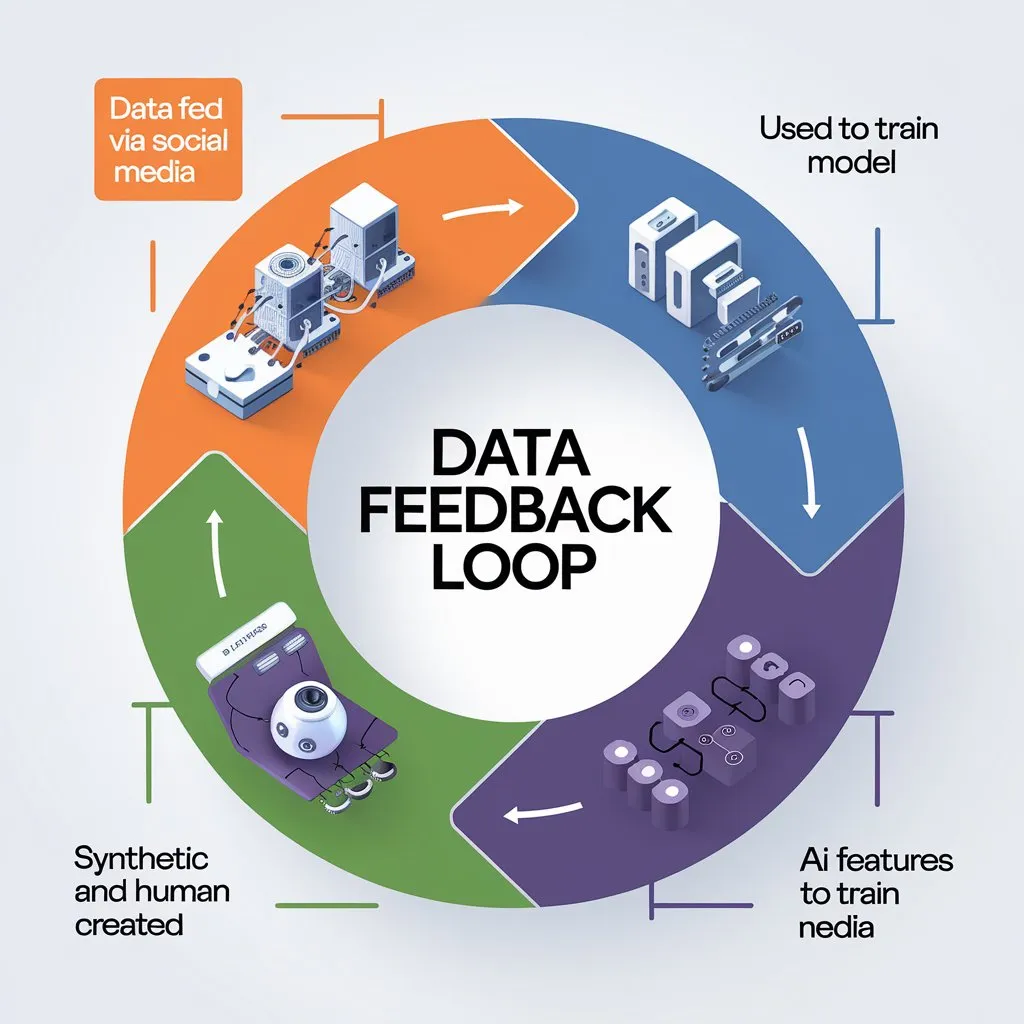
image generated by Ideogram
The Data Feedback Loop
Everything is data.
Read that again. Everything is data.
In this era, that is all that matters. It is the goal. The ones with the most data are going to win.
This means it is vital to focus in this area. We are not only dealing with the goal, it is also the starting point. Therefore, we have to be dealing with a loop.
Social media is no longer anything more than a data generation tool. These platforms nOW exist to have users generate more data.
It is the onset of the feedback loop.
Here is how it works:
- data is generated by users on a platform
- said data is fed into a neural network to train the model
- from this model, features are created which users can utilize
- when utilized, these feature generate more data
- the additional data is fed into the training of the next generation of models
Rinse and repeat.
Any features added to these platforms is done so with the intention of generating more data. No longer is it primarily about utility. Instead, we are looking at data generate the currency sought.
The New Oil
We heard he saying "data is the new oil". Why is this the case?
https://inleo.io/threads/view/taskmaster4450le/re-leothreads-2tdmx7wxt?referral=taskmaster4450le
Who do you think stands to benefit from the new "oil"? Just like those with the commodity, such as Saudi Arabia, saw enormous wealth from this resources, those with data are going to find themselves in the same position.
The key here is we keep producing more data on a daily basis. We do have some control over the amount we create and, in part, where it is directed.
Social media companies are in a powerful position; more so than before. They are the ones who have users filling their servers each day. People simply show up to give them more "oil".
Of course, these companies are well aware of the data feedback loop. It is why YouTube is implementing a Discord style community chat for content creators to utilize. Consider the amount of data people will give to Google through that.
The New Focus
Platform owners have a different view of this entire situation. Social media is nothing more than data.
This is a mindset which has to be adopted within Web 3.0.
If data is the starting point, how are we doing with it? The answer, sadly, is rather obvious. We see most people who are supposedly in Web 3.0 sitting on Web 2.0 application feeding them even more data.
This is compounded by the lack of AI tools. Synthetic data is enormously powerful when it is combined with human feedback. This is what happens with social media platforms. People can post synthetic data and others can interact with it.
Here is where we see huge improvements in the knowledge graphs that are designed.
This provides a foundation for better models from which more features can be created. However, features must roll out that generate more data.
Consider the evolution of OpenAi.
When it was formed, what did it have? Pretty much nothing. Where was the starting point?
While team of software and data engineers might have been required, the first step is to get some data. It is impossible to have any type of AI without out.
This was an organization that started in 2015. I believe they rolled out their first product for public use in 2019. This was not user friendly but it was more advanced than what was out there (I think it was GPT 2).
My point is they were scraping the Internet for data. Naturally, we know the result of this is getting sued by everyone under the sun who published anything online. Nevertheless, OpenAI got the data.
This shows the importance. The company is also cutting deals, spending tens of millions to gain access to more.
As I said, this is a data game. The problem for OpenAI is that the lack of a feeder system. XAI, Google, and Meta all have this.
When watching the larger platforms, notice how they are positioning things. Look beyond the marketing pitches and press releases to ask yourself one question: how much data is this going to provide them?
From this perspective, things become a lot clearer.