I remember, I learned to read and write way before entering my elementary school, so someone could maybe think that I had enough time so far to learn to write legibly and neatly.
Allow me to disappointingly answer you: LOL.
Maybe that’s somehow related with the fact that my mum works as a medical worker and we all know that all people in medicine have awful handwriting – something that you can see as a meaningless, curve line, a doctor can read as a ‘‘two weeks, three pills per day’’, so there’s nothing else left to do for you except to swallow those pills and pray to God that it was really written on that prescription.
As you can see, an ability to read someone’s handwriting is pretty important and that was interesting challenge for machine learning in past years. There is bunch of software on the market and I’m sure that they made solid amount of money to their authors. Also there are numerous reasons to know to recognize written numbers and that’s all part of one big area called pattern recognition.
On my last article about AI, I’ve received one interesting comment by @alexander.alexis that made me laugh:
But, that also made me thinking and gave me an idea to maybe make some program that can mess around a little bit with pictures. Of course, I can’t make conscious images and program them to be self-made - if I would know that, I would probably be a millionaire so far.
Instead of that, what if I could write a program that can recognize handwritten digits? Does it sound like a science fiction to you?
This is how it works
Pattern recognition is actually one big tool for making decisions – for example, based on symptoms, your doctor has to decide are you sick or not and just to show you how it’s important, imagine two types of error:
If you are healthy and doctor made mistake and considered you as a sick person – it’s still not a big deal, you’ll use your medications for some time to ‘‘cure yourself’’ and that’s it.
But take a look at a different side of a story – if you are sick and doctor made mistake and considered you as a healthy person, it can be much more serious case with catastrophic consequences.
So what is actually making one doctor good?
It’s an ability to notice right symptoms and based on that and his knowledge, to recognize your ‘‘state’’ and make the best possible decision.
Looking through eyes of patter recognition, those symptoms are actually descriptors or features – I talked about them in my post about neural networks. They are the best possible characteristics for some class and it’s hugely important to choose right features. Basically, choosing right features is almost half job done. To accomplish that, it’s a good practice to talk with someone who is expert in area for which you want to make classifier.
Pattern recognition is widely useful, for example in fingerprint recognition (say hello to Apple servers which are collecting your data through iPhone), or face recognition (say hello to Facebook servers which are collecting your data from your pictures) or in analyzing sentiments in your text (say hello to Google servers which are collecting your data from your mail) and so on.
To show you how it works in practice, I’ve used one data base of handwritten digits, which my class on college made for machine learning exercises. Fun fact – computer has the most difficulties to make the difference between digits 6, 8 and 9. So I’ve used exactly those three digits to show you this principle.
This is how my data base looks like:

And here are some of the representatives:

To work easier we should do a little preparation of our data set. You can imagine every picture as a net of pixels and every pixel has some values of red, green and blue color, right? First of all, we will make binarization of pictures – simply said, we’ll turn them to be black and white (you’ll see later why).
Again, I’m turning on Matlab and we can set one treshold and say that if every pixel value (between 0 and 255) is above that treshold then it’s white pixel and if it’s below then it’s black pixel. You can see the code below how it' done for one image:

The result is black and white image:

Next step is to crop that extra white space around the digits, so we could easily extract features and the result should look like this:

When we finish this for all pictures in our data set, then the preparation is finished and we can search for features and further manipulations with this data.
What can we use as features?
This is why we had to turn our pictures to be black and white – we will use number of black pixels in areas like upper right and lower left corner of the picture as a first and second feature! Basically – we are trying to see is something written in those areas, because it’s supposed for number 6 to have more white pixels in upper right corner and more black pixels in lower left corner. For nines it should be literally the opposite case and for eights it should have black pixels on both areas.
Now, we are going to read all pictures that we will use as a training set:
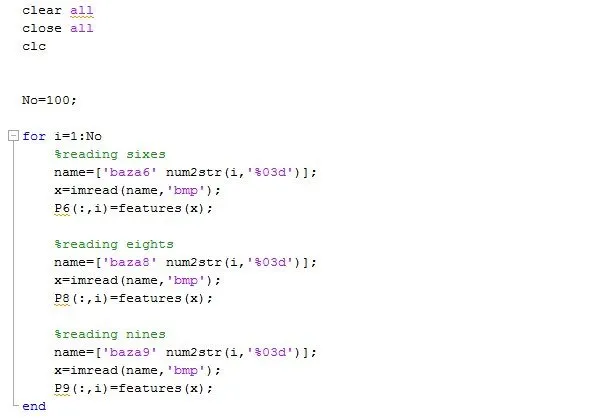
Function ‘feature’ is a function which I wrote for preparation of the pictures and feature extraction, which I explained above.
Now I’m going to plot those classes.

And it looks like this:
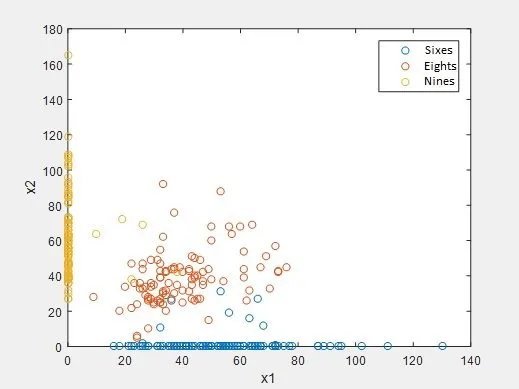
As you can see, x1 and x2 are our features (number of black pixels in those two areas) and we can clearly see the difference between our numbers 6, 8 and 9 in this space.
After making the training set, we should build a classifier which we will train to recognize numbers on our test set.
First we will do the same procedure like on the training set – making the test set and extracting the features:
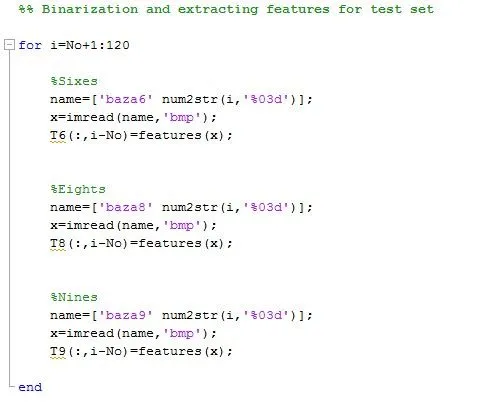
Now, if you are not the type who is everyday surrounded with numbers and formulas , prepare yourself to see one of the ugliest things in your life:
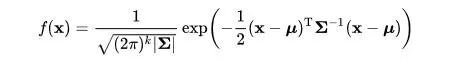
This is the formula which we will use to make our classifier – It’s called probability density function for vectors with normal distributed variables. The principle is to calculate density functions for every sample of our classes and to compare them. In order to calculate this, we must first determine covariance matrices and mean values of our training classes:

When it’s finished, we are building now ‘the thing’ which will recognize our numbers, using the formula from above and we will test it immediately:
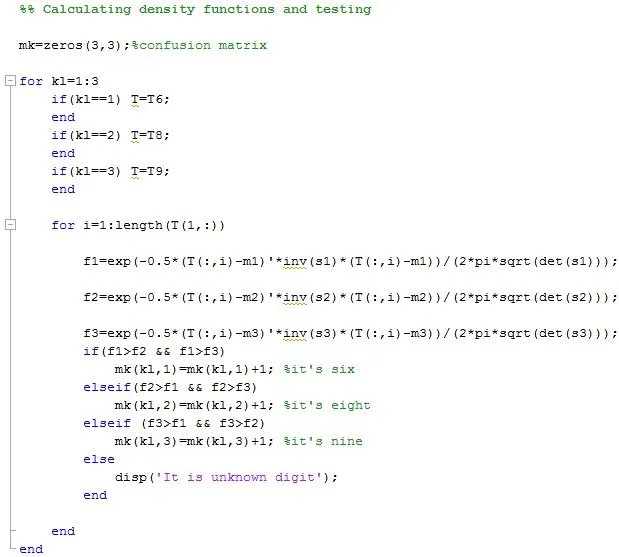
In order to see our results, we will use something about which I talked last time in my neural networks article – a confusion matrix! This is that mk variable from the part of the code above – it’s actually a matrix and if we display it’s values, it looks like this:

This means that out of 60 samples of written sixes, eights and nines, our program wrongly classified only three samples!!!
It recognized one six as an eight and two eights as nines.
And that’s the small, nerdy peek into how those things work behind today’s “buzz technology”.
Impressive, isn’t it?
I hope that you enjoyed,
I have to thank my mentor @scienceangel for her strong support during writing this article and for staying curious and patient to read everything what I write for STEM community.
Sources:
Introduction to statistical pattern recognition, Keinosuke Fukunaga
Good part of this article is written relying on my experience.
All images are screenshots, taken from my computer and are free for further use.