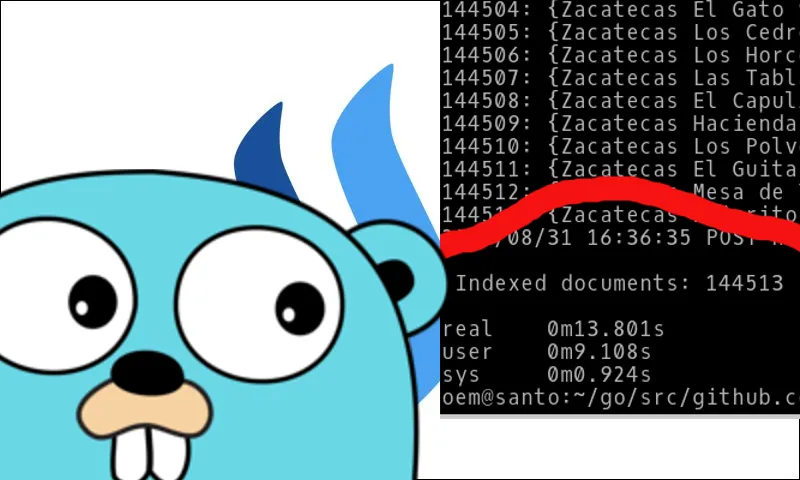
In this post im going to show you how to load 144513 documents in ElasticSearch Server in a few seconds.
For this example i used the Elasticsearch client for Go:
https://olivere.github.io/elastic/
and the BulkIndex:
https://github.com/olivere/elastic/wiki/BulkIndex
The BulkIndex help us to perform a many index operations in a sigle request.
Let's start
I will use the MX.zip (MX.txt csv file) file from the Geonames site.
To read the file I will use the package: encoding/csv
In this post I explain how to read a file in csv format, a part of that example I'm going to use for this new example.
A line in the MX.txt file looks like this:
MX 20010 San Cayetano Aguascalientes AGU Aguascalientes 001 Aguascalientes 01 21.9644 -102.3192 1
A part of these data I need to put in a structure, that structure is as follows:
type (
Document struct {
Ciudad string `json:"ciudad"`
Colonia string `json:"colonia"`
Cp string `json:"cp"`
Delegacion string `json:"delegacion"`
Location `json:"location"`
}
Location struct {
Lat float64 `json:"lat"`
Lon float64 `json:"lon"`
}
)
With the init function I'm going to create a new cliet like this:
func init() {
var err error
client, err = elastic.NewClient(
elastic.SetURL(os.Getenv("ELASTICSEARCH_ENTRYPOINT")),
elastic.SetBasicAuth(os.Getenv("ELASTICSEARCH_USERNAME"), os.Getenv("ELASTICSEARCH_PASSWORD")),
elastic.SetErrorLog(log.New(os.Stderr, "ELASTIC ", log.LstdFlags)),
elastic.SetInfoLog(log.New(os.Stdout, "", log.LstdFlags)),
)
printError(err)
}
In the next code, i load the cols of the csv file in the Document struct:
document := Document{
Ciudad: col[3],
Colonia: col[2],
Cp: col[1],
Delegacion: col[5],
Location: Location{
Lat: lat,
Lon: lon,
},
}
An this is the important part:
req := elastic.NewBulkIndexRequest().Index(os.Getenv("ELASTICSEARCH_INDEX")).Type(os.Getenv("ELASTICSEARCH_TYPE")).Id(id).Doc(document)
bulkRequest = bulkRequest.Add(req)
fmt.Printf("%v: %v\n", n, document)
This is where the Bulk request is created.
And finally the bulk request is executed as follows:
bulkResponse, err := bulkRequest.Do(ctx)
The complete version of the code is:
/*
twitter@hector_gool
https://github.com/olivere/elastic/wiki/BulkIndex
*/
package main
import (
"fmt"
elastic "gopkg.in/olivere/elastic.v5"
"encoding/csv"
"github.com/satori/go.uuid"
"context"
"os"
"log"
"strconv"
)
type (
Document struct {
Ciudad string `json:"ciudad"`
Colonia string `json:"colonia"`
Cp string `json:"cp"`
Delegacion string `json:"delegacion"`
Location `json:"location"`
}
Location struct {
Lat float64 `json:"lat"`
Lon float64 `json:"lon"`
}
)
const (
FILE ="./MX.txt"
TOTAL_ROWS = 1000000
)
var (
client *elastic.Client
)
func init() {
var err error
client, err = elastic.NewClient(
elastic.SetURL(os.Getenv("ELASTICSEARCH_ENTRYPOINT")),
elastic.SetBasicAuth(os.Getenv("ELASTICSEARCH_USERNAME"), os.Getenv("ELASTICSEARCH_PASSWORD")),
elastic.SetErrorLog(log.New(os.Stderr, "ELASTIC ", log.LstdFlags)),
elastic.SetInfoLog(log.New(os.Stdout, "", log.LstdFlags)),
)
printError(err)
}
func main() {
ctx := context.Background()
file, err := os.Open(FILE)
printError(err)
defer file.Close()
reader := csv.NewReader(file)
reader.Comma = '\t'
rows, err := reader.ReadAll()
printError(err)
bulkRequest := client.Bulk()
for n, col := range rows {
n++
id := uuid.NewV4().String()
if n <= TOTAL_ROWS {
lat, err := strconv.ParseFloat(col[9], 64)
printError(err)
lon, err := strconv.ParseFloat(col[10], 64)
printError(err)
document := Document{
Ciudad: col[3],
Colonia: col[2],
Cp: col[1],
Delegacion: col[5],
Location: Location{
Lat: lat,
Lon: lon,
},
}
req := elastic.NewBulkIndexRequest().Index(os.Getenv("ELASTICSEARCH_INDEX")).Type(os.Getenv("ELASTICSEARCH_TYPE")).Id(id).Doc(document)
bulkRequest = bulkRequest.Add(req)
fmt.Printf("%v: %v\n", n, document)
}
}
bulkResponse, err := bulkRequest.Do(ctx)
printError(err)
indexed := bulkResponse.Indexed()
if len(indexed) != 1 {
fmt.Printf("\n Indexed documents: %v \n", len(indexed))
}
}
func printError(err error) {
if err != nil {
fmt.Fprintf(os.Stderr, "Fatal error: %s", err.Error())
os.Exit(1)
}
}
To have an approximate runtime use the following instruction:
time go run elasticserach_bulk.go
And I get the following result:
Indexed documents: 144513
real 0m13.801s
user 0m9.108s
sys 0m0.924s
Conclusion:
I have to confess that the first solution that I thought was to generate 144513 curl commands like this:
curl -u elastic:changeme -X PUT "http://localhost:9200/mx/postal_code/1" -d "
{
\"cp\" : 20000,
\"colonia\" : \"Zona Centro\",
\"ciudad\" : \"Aguascalientes\",
\"delegacion\" : \"Aguascalientes\",
\"location\": {
\"lat\": 21.8734,
\"lon\": -102.2806
}
}"
And it worked but it took little more than 3 hours to load the 144513 registers
But with the example that shows them only takes on average 13 seconds! :)
What do you think?