Funkcja Sigmoidalna? Tangens hiperboliczny? Funkcja reLU? SoftPlus? A może SoftMax? Co można powiedzieć o tych funkcjach i które z nich są najlepsze?

Było już mówione o tym, że bez funkcji aktywacji w sieciach neuronowych to tak jakby odkręcić tubkę z pastą do zębów, ale jej nie wycisnąć - a przecież idziemy myć zęby. Wiedząc o jej znaczeniu i znając już najprostszą funkcję skokową, przyglądnijmy się również innym najczęściej używanym funkcjom, które aktywują wyjście neuronu.
Na pierwszy ogień idzie funkcja sigmoidalna (sigmoidalna unipolarna).
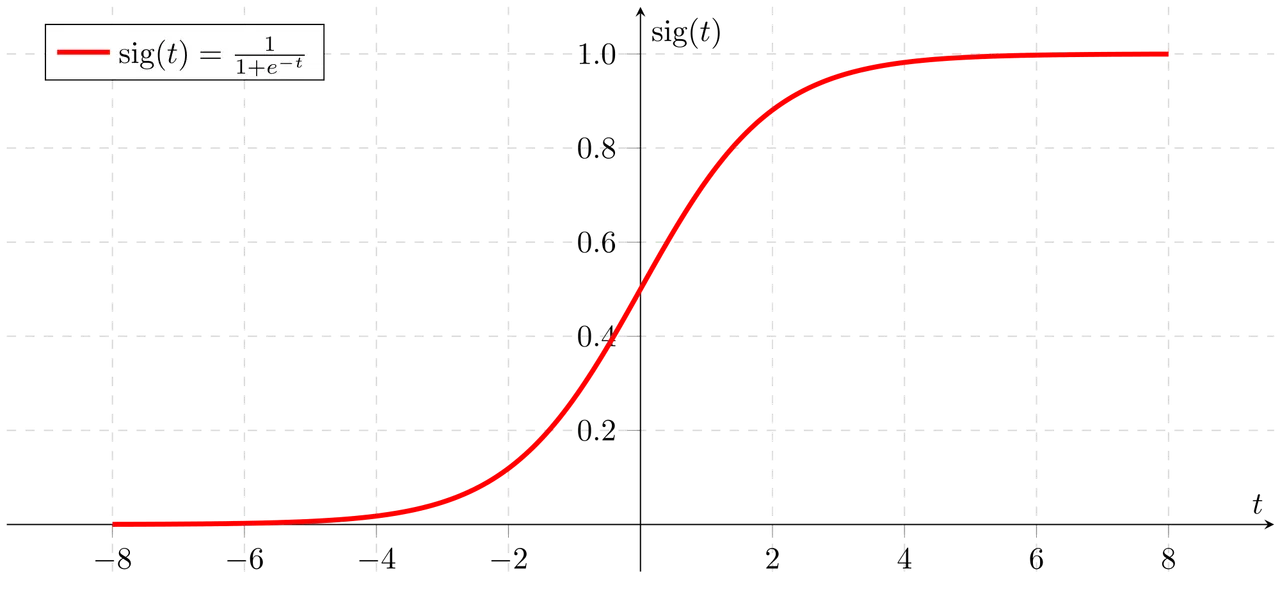
Prawda, że wygląda jak super-gładka funkcja skokowa? To właśnie jej płynna zmiana (między innymi) przyświecała powszechnemu używaniu tej funkcji. W jej bezkrytycznym używaniu chodziło również, a nawet przede wszystkim o łatwość obliczenia jej różniczki do propagacji wstecznej (ale o tym opowiemy sobie innym razem). Standardową funkcję sigmoidalną, czyli taką jak na powyższej reprezentacji graficznej, można opisać wzorem:

gdzie:
x - argument (wejście) funkcji
exp() - eksponenta, funkcja ekspotencjalna, funkcja wykładnicza o liczbie Eulera w podstawie - nazw nosi z pewnością wiele (zupełnie jak Mithrandir Gandalf z “Władcy Pierścieni”) - faktem jest jednak, że to po prostu “odwrotność” logarytmu naturalnego
Warto zauważyć, że “gładkość” funkcji sigmoidalnej pozwala jej przyjąć oprócz wartości 1 lub 0 - w przeciwieństwie do funkcji skokowej - dowolną liczbę z przedziału między nimi (logika rozmyta, pamiętasz?).
Sprawą konieczną o której trzeba wspomnieć jest fakt, że niestety jest ona “kosztowna” w obliczeniach i z reguły zbiega wolniej do żądanego wyniku niż funkcja reLU (o której za chwilę), co w przypadku większych sieci neuronowych znacznie wydłuża proces uczenia - sam czas wymienienia nazw eksponenty exp() umieszczonej w mianowniku (pod kreską ułamkową) funkcji sigmoidalnej zajmuje trochę czasu i mimo że wymienianie nazw nie ma żadnego związku z matematyką niech to będzie dla nas metaforyczna wskazówka, gdybyśmy tworzyli wielowarstwowe sieci by nie przesadzać z nadużywaniem tej funkcji :-)
Funkcją podobną do sigmoidalnej jest tangens hiperboliczny, o którym powiemy bardzo krótko bo praktycznie rzecz biorąc jest on analogią do sigmoidy.

Tangens hiperboliczny wyraża się wzorem:
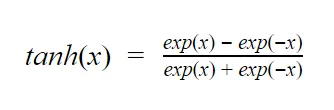
Łatwo zauważyć jego podobieństwo do funkcji sigmoidalnej - jedyne różnice to oczywiście punkt przecięcia w punkcie 0, oraz jej inna “pochyłość”.
Kolejną, popularną funkcją aktywacji jest reLU (rectifier Linear Unit). Od swojego kształtu w mowie potocznej często nazywana jest funkcją rampy (bo i rzeczywiście - wygląda jak rampa).

Powyższą reprezentację można wyrazić wzorem
SUMA_SYGNAŁÓW > 0 y = SUMA_SYGNAŁÓW
SUMA_SYGNAŁÓW ≤ 0 y = 0
lub prościej jako:
MAX(0, SUMA_SYGNAŁÓW)
Gdzie ten drugi zapis jest wykorzystywany w implementacjach w różnych językach programowania i oczywiście znaczy, że wyjście przyjmuje wartość 0 jeśli SUMA_SYGNAŁÓW jest mniejsza bądź równa 0, lub przyjmuje wartość SUMY_SYGNAŁÓW jeśli wartość jest większa od 0.
Funkcja reLU jako aktywacja sieci neuronowych została użyta po raz pierwszy w 2012 roku w konkursowej implementacji nowoczesnego modelu sieci neuronowej - AlexNet - gdzie autorzy uzyskali o wiele lepsze wyniki niż pozostali uczestnicy, opierający swoje sieci o aktywację funkcją sigmoidalną i tanh. Trzeba powiedzieć że autorzy tej sieci - Panowie Alex Krizhevsky, Geoffrey Hinton, and Ilya Sutskever - wywarli ogromny wpływ na współczesną metodykę programowania sieci neuronowych, a ich jeden prosty trik znacznie zwiększył wydajność uczenia maszynowego, względem wcześniejszych rozwiązań.
Na zakończenie wypada jeszcze wspomnieć o funkcji SoftPlus. Soft znaczy oczywiście “miękki” i rzeczywiście funkcja SoftPlus jest tym czym sigmoida dla funkcji skokowej - czyli super-miękką i super-gładką funkcją reLU.
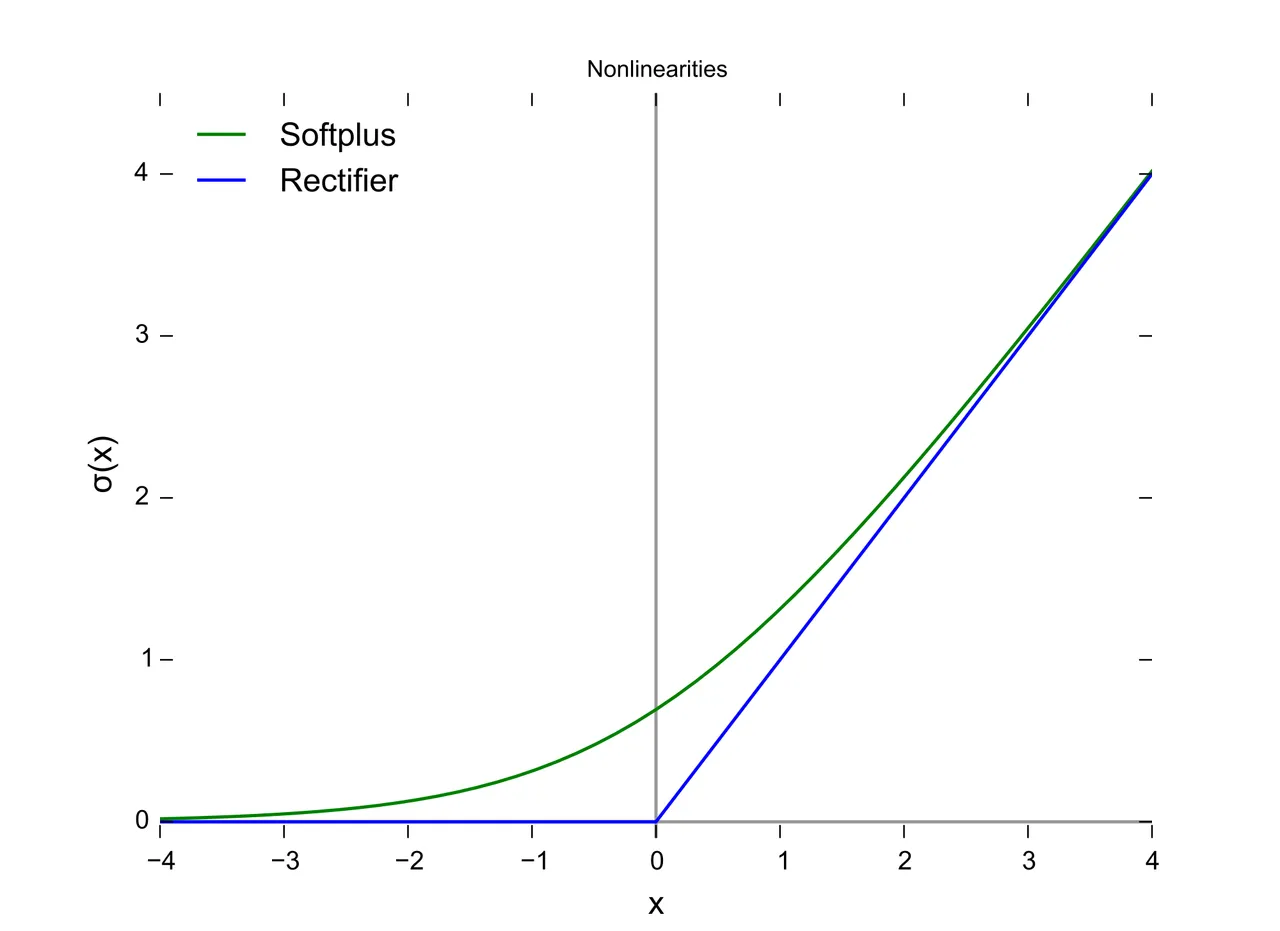
Wyrażamy ją poniższym wzorem:
SoftPlus(x) = log(1 + exp(x))
gdzie:
log() - logarytm naturalny
Z kolei inną funkcją z moglibyśmy rzec “tej samej stajni”, również będącą analogią do reLU jest funkcja SoftMax, która normalizuje wynik wyjściowy podając go jako pewne określone prawdopodobieństwo (tzw. forma probabilistyczna) - co sprawiło, że jest chętnie wybieraną funkcją aktywacji ostatniej warstwy współczesnych sieci neuronowych.

Podsumowując - istnieje wiele różnych aktywatorów wyjścia sieci neuronowych, które kiedyś znajdowały lub wciąż znajdują zastosowanie. Obecnie niezaprzeczalnie dominuje stosowanie funkcji reLU w połączeniu z SoftMax, których użycie zapewnia szybszą zbieżność algorytmu w większości przedstawianych sieci neuronowej, problemów.
Dziękuję za uwagę!
Grafika:
Potwierdzam że użyłem Zaawansowanego szukania grafik Google z zaznaczoną opcją prawa użytkowania treści: "Do swobodnego użytku, udostępniania lub modyfikowania, również komercyjnego"

Bibliografia
- R. Tadeusiewicz "Sieci neuronowe" Akademicka Oficyna Wydaw. RM, Warszawa 1993. Seria: Problemy Współczesnej Nauki i Techniki. Informatyka.