R은 툴이니 그냥 쓰면 되는 건데, R을 쓰기위한 과제의 해석/수식의 이해는 통계를 공부해야만 알 수 있네요.
그리고 입문과정이다 보니 유의성과 P-Value가 항상 헷갈립니다. 이번에는 T검정까지..
이번에도 과제를 풀면서 조금 더 익혀보겠습니다.

ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ내가 이해하기 위한 쓸데없이 긴 설명ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
문제를 조금 더 이해하기 위해 도식화를 해봅니다.
펀드 A는 연평균수익률이 12%에 표준편차 2%의 분포를 보이고 있습니다.
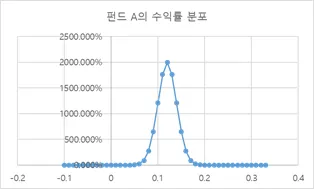
펀드 B는 연평균수익률 8%에 표준편차 3%의 분포를 보이고 있습니다.

서로 겹치면 이렇습니다.
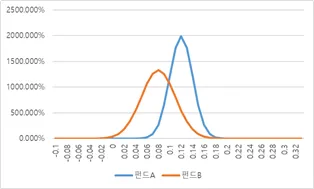
위 두 펀드의 수익률에 차이가 있는 것인지, 통계적으로 검정하라는 문제입니다.
[기초금융통계2 36P에 참조내용이 있습니다.]
이 문제를 푸는 절차는 다음과 같습니다.
1 ) 가설설정
2 ) 검정통계량 t값을 확인
3 ) 이를 이용하여 p-value 계산
4 ) P-value와 유의수준을 비교하여 결론 도출
가설설정 : 펀드의 연평균 수익률을 μ라고 할 때
귀무가설. 두 펀드의 연평균 수익률은 차이가 없다. vs 대립가설. 두 펀드의 연평균 수익률은 차이가 있다.
H_O: μ_A=μ_B vs H_a: μ_A≠μ_B
(크다, 작다가 아닌 차이가 있다이므로 양측검정을 해야합니다.)
검정통계량 t값을 확인

이며...이를 R콘솔에서 구하면
> (12-8)/sqrt(2^2/8+3^2/10)
[1] 3.380617

으로 나옵니다.
검정통계량t값은 3.380617입니다.
여기서 t분포의 자유도를 min(n_1-1, n_2-1)을 사용할 수 있으므로 자유도는 8-1이고 R콘솔에서 구하면
> pt(3.380617,df=8-1)
[1] 0.9941256

입니다.
여기서 주의하셔야 할게 지금 판단하려는 것은 양측검정입니다.
그래프의 가운데 기준 양쪽 끝값이라는 거죠.
지금 P값은 가상의 그래프로 표현하면 다음과 같습니다.
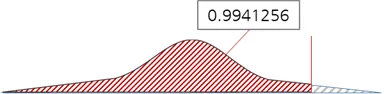
뭔가 이상하죠?
양측검정값은 여기에 ×2를 해야 하는데? P-value가 너무 큽니다?
그렇습니다. 여기서 적용해야할 값은

입니다. 즉 1에서 pt(3.380617,df=8-1)를 빼야하는 것이죠.
문제를 돌아보면 '차이'를 판단하는 문제였습니다.
순서대로 ‘12-8’로 했지만 ‘8-12’로 해도 같은 해석이 나와야 하는 거죠.
실제 계산해보면 다음과 같습니다
> (8-12)/sqrt(2^2/8+3^2/10)
[1] -3.380617

검정통계량t값은 -3.380617 이고
앞과 같이
> pt(3.380617,df=8-1)
[1] 0.005874401

위에서 구한 값이랑 같습니다.
이는 아까 그래프의 끝단 값이 됩니다.
다시, 양측검정이므로 양끝단의 값을 더해줍니다.

> 2*pt(-3.380617,df=8-1)
[1] 0.011748802
P-value는 0.012로 유의수준 0.05보다 작습니다.
따라서 귀무가설을 기각하므로, 연평균 수익률은 차이가 없다고 볼 수 없다.
즉 연평균 수익률은 차이가 있습니다.
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ 긴설명 끝ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
1 ) 가설설정
2 ) 검정통계량 t값을 확인
3 ) 이를 이용하여 p-value 계산
4 ) P-value와 유의수준을 비교하여 결론 도출
1 )가설설정 : 펀드의 연평균 수익률을 μ라고 할 때
귀무가설. 두 펀드의 연평균 수익률은 차이가 없다. vs 대립가설. 두 펀드의 연평균 수익률은 차이가 있다.
H_O: μ_A=μ_B vs H_a: μ_A≠μ_B
2 )검정통계량 t값을 확인
3 )p-value 계산
(1에서 위를 빼면 아래, 1에서 아래를 빼면 위)
4 ) P-value와 유의수준을 비교하여 결론 도출
차이를 판단하는 양측 검정이므로 p-value는 0.5 이하의 값을 선택,
0.005874401에 2를 곱하면 0.011748802이고, 유의수준 0.05보다 작으므로 귀무가설을 기각한다.
두 펀드의 연평균 수익률은 차이가 없다고 볼수 없다. 즉 차이가 있다.

[기초금융통계2 48P에 참조 내용이 있습니다.]
가설
귀무가설. 두 회사의 투자성공률은 차이가 없다. vs 대립가설. 두 회사의 투자성공률은 차이가 있다.
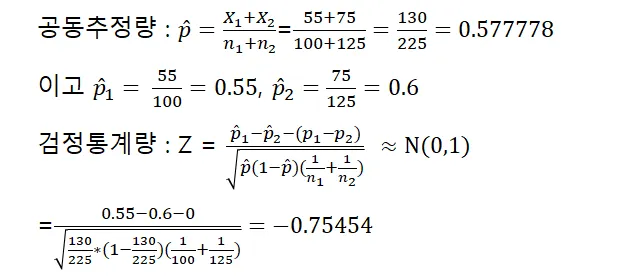
Pnorm()를 이용하여 p-value를 구하면 0.2252622
양측검정이므로 2*pnorm()의 값은 0.4505245
R콘솔을 이용하면 다음과 같이 풀이됩니다.

p-value는 0.45 수준으로 유의수준 0.01보다 크므로 귀무가설을 채택합니다. 즉, 두 투자회사의 성공률은 차이가 없습니다.

[기초금융통계2 66,67,68P에 참조 내용이 있습니다.]
문제의 데이터를 강의자료에서처럼 확률로 변환하면

와 같이 됩니다.
질문은 이러한 분포에서 직장의 종류와 성별에 연관이 있느냐 없느냐에 대한 내용입니다.
자. 카이제곱이라는 말이 나왔습니다. 무슨말인가요?
(구글링을 해보면 자세하고 많은 자료가 나오지만 저에게 필요한 것만 담아보면 이렇습니다.)
카이제곱은 관측값이 기대값(예를 들어 평균)에서 얼마나 떨어져 있는가를 의미합니다.
기대값에서 떨어진 정도는 (관측값-기대값)으로 구할 수 있습니다.
그리고 이 값을 제곱하면 (관측값-기대값)2이 됩니다.
왜 제곱이냐, 각각의 관측값은 기대값을 중심으로
[편차의 합은 0] → [제곱값을 통해 떨어져있는 정도 파악가능]하기 때문입니다.
그런데 결국 기대값에 대해서 얼마나 크게 벗어난 것인지를 파악해야 하기 때문에
위 값을 다시 기대값으로 한번 나누어 줍니다.
이를 식으로 표현하면 다음과 같습니다.

이 x^2을 카이제곱으로 읽습니다.(예전 019 광고에서 x를 그리스어로 카이라고 불렀던 기억이 납니다.)
자 그럼 다시 문제로 돌아가서, 먼저 위의 표를 R에서 행렬로 만들어야 합니다.
변수명을 Job직장으로 잡고 행렬을 입력합니다.
> job<-matrix(c(435,375,147,134),ncol=2,nrow=2)
1 ) 이제 이 행렬의 기대빈도를 구합니다.
기대빈도는 변수 사이에 연관성이 없다는 가정하에 예상되는 빈도로

의 산식을 사용할 수 있으나, R의 카이제곱 검정을 통해 쉽게 구할 수 있습니다.
> chisq.test(job)$expected

문제와 같은 칸으로 표현하자면,
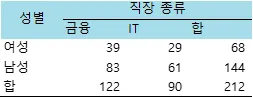
이 됩니다.
2 )카이제곱 검정을 이용, 연속성 수정하지 말고 관련이 있는지 유의수준 5%에서 검정하기
위에서 만든 행렬을 카이제곱검정합니다.
> chisq.test(job,correct=FALSE)
(연속성을 수정하는 경우에는 correct=FALSE를 넣지 않습니다.)

p-value가 0.1473으로 유의수준 5%보다 크므로 귀무가설을 지지합니다.
즉 직업과 성별은 연관이 없습니다.
참고로...
강의노트에서 수업시간에 연속수정 부분에서 다음을 수정해주셨습니다.
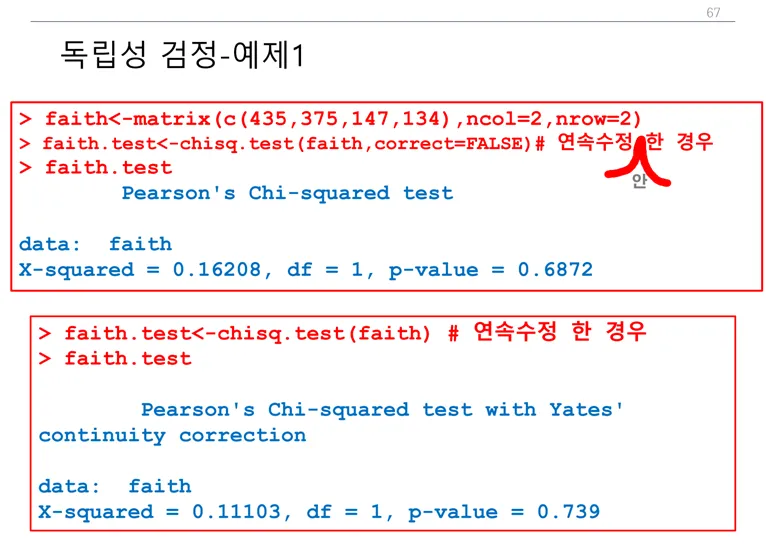
또한, 수업시간에 가르쳐 주신대로 하면
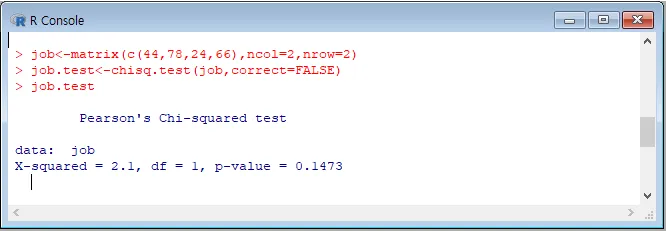
(변수의 치환 반복)을 사용하셔도 됩니다.
오늘은 여기까지 복습했습니다.
혹시 수정할 부분을 말씀해주시면 바로 피드백하겠습니다.