지난시간에 R을 켜는 방법만 배우고 과제 풀이를 했습니다.
두번째 과제를 풀려고 하니 처음부터 막힙니다.
R이 통계프로그램이다보니 통계를 아예 공부않고 지나갈 수는 없습니다.
이쪽으로 백지이다 보니...스스로를 가르친다는 생각으로 문제를 풀어봅니다.
수업시간에 그냥 그런가보다..하고 지나간 것들도 과제를 풀다보면 그게 이 말이었구나..싶어서
과제는 스스로에게 어떤 친해지기(?)에 좋은 도구 같습니다.

지난 과제를 어떻게 했는지 생각이 안납니다. 어쩌라고. DAX를 치면 뭐가 나오려나?
그래서 무작정 DAX를 입력합니다. 에러 메시지가 뜹니다.
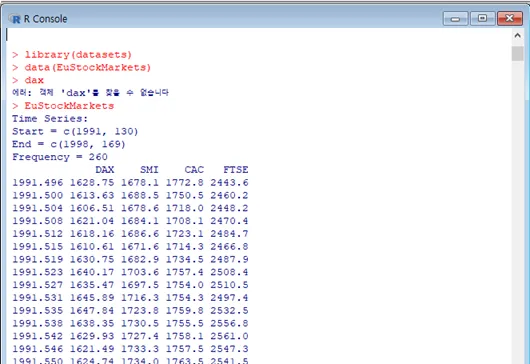
다시, 이번에는 EuStockMarkets을 입력합니다. 데이터의 내용이 주르륵 나옵니다.
...
1993년도부터 1998년까지의 DAX, SMI, CAC, FTSE 가 나와있는 데이터네요.
apply 명령어를 이용하여 DAX, SMI, CAC, FTSE의 중앙값과 평균을 구하라고 합니다.
Apply가 뭐였는지 찾아보니 R_intro.pdf의 117페이지에 나와있습니다.

이 내용을 보면 X라는 행렬을 만들고,
apply(X,1,mean)을 입력하면
-> ‘데이터집합 X’의 ‘행’의 ‘mean(평균)’을 ‘구하라’
-> 각 행들의 평균값 출력
apply(X,2,mean)을 입력하면
-> ‘데이터집합 X’의 ‘열’의 ‘mean(평균)’을 ‘구하라’
-> 각 열들의 평균값 출력
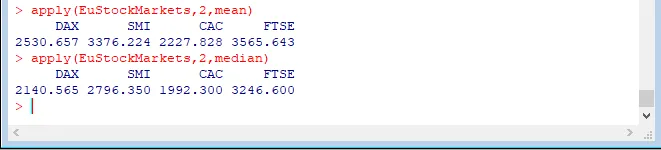
그래서 EuStockMarkets 내 DAX, SMI, CAC, FTSE의 평균값을 구하기 위해서는
apply(EuStockMarkets,2,mean)을 입력
EuStockMarkets 내 DAX, SMI, CAC, FTSE의 중앙값을 구하기 위해서는
apply(EuStockMarkets,2,median)을 입력하면 됩니다.
R콘솔에서는 다음과 같이 표시됩니다.
이 지수들의 대략적인 분포는 어떻게 될까요.
평균값이 중앙값의 차이가 주는 의미에 주목할 수 있습니다.
평균값이 중앙값과 같으면 지수가 선형으로 균등한 분포를 보인다는 이야기가 되며,
평균값이 중앙값보다 낮으면 평균을 끌어내리는 아랫쪽 특이값(outlier)이 존재한다는 분포가 됩니다.
(Ex. 95kg ~ 105kg 씩 거의 균등하게 말 10마리 몸무게가 100kg인 집단에 50kg 2마리가 들어오게
되면 중앙값은 크게 영향을 받지 않으나(100->99), 평균은 크게 영향을 받게됩니다.(100->91.7))
DAX, SMI, CAC, FTSE 지수들은 평균값이 중간값보다 높으므로, 대략적으로 윗쪽 특이값(outlier)이
존재하는 분포를 보인다고 할 수 있습니다.
(지수들을 plot으로 시각화시켜보면 실제 분포를 확인할 수 있습니다.

그럼 boxplot을 만들어봅니다.
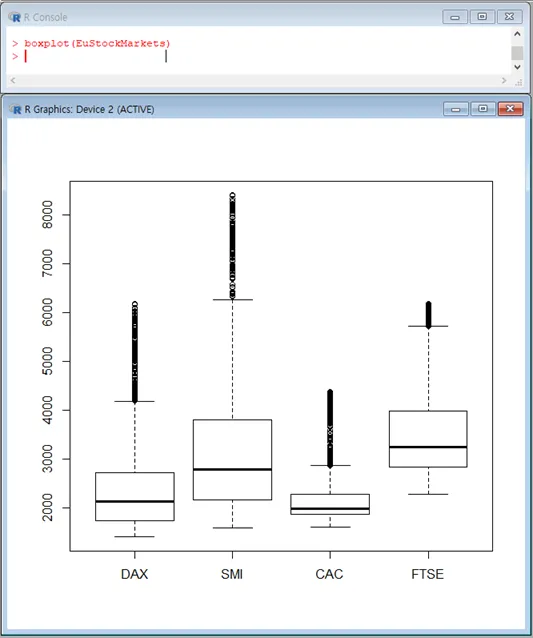
4가지 지수 모두 윗쪽 꼬리가 길게 달렸습니다.즉, 자료상 윗쪽 특이값이 많다고 볼 수 있습니다.
군집정도가 넓었던 FTSE는 다른 지수들에 비해 윗쪽 꼬리가 짧습니다.
그래도 특이값이 너무 많은 데 특이값이라고 할 수 있나, 이러면 반영이 되야 하지 않나, 어떤 기준을 두고 반영을 하고 반영을 않는 것인가 하는 의문이 생깁니다.
정윤서 교수님께 여쭈었더니, Boxplot 명령어는 기본 셋팅에서 interquatile range (IQR,4분위 범위,Q3-Q1, 중앙값 기준 데이터의 절반이 모여있음, 그림상의 네모) 의 1.5배가 넘는 자료들을 특이값으로 처리합니다. 그리고 이러한 특이값을 모두 수용하여 boxplot을 구성하고 싶을 때는 IQR의 배수 range를 1.5보다 큰 수치를 입력하면 됩니다.
명령어는 다음과 같습니다.1.5대신 10을 입력한다고 가정해보겠습니다.
boxplot(EuStockMarkets,range=10)
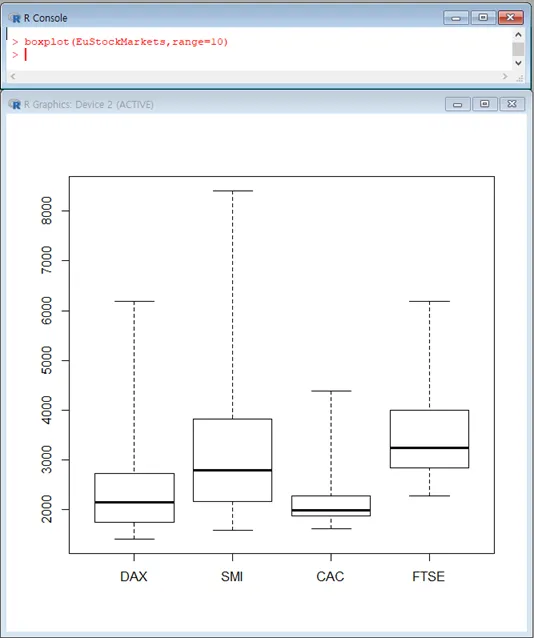
이렇게 조정한 boxplot에서는 각 지수는 IQR(3사분기점-1사분기점, 네모박스, 데이터의 절반 군집)의 위치로 보아 4분기점을 구성하는 데이터들의 군집도가 매우 낮음을 알 수 있습니다.
그렇다면 range를 Default로 쓰는 것과 넉넉하게 늘리는 것 둘 중 어느 것이 좋을까요?
결국 둘다 [중위 50%는 최소값 대비 최대값과의 거리가 크다]를 의미하나,
Default range로 박스플롯을 그리면 특이값의 갯수가 적은지 많은지를 알 수 있기에
Default range(x1.5)의 박스플롯이 더 많은 자료를 담고 있다고 볼 수 있는 거죠.
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
제가 이해하려고 길게 풀어썼지만, 내용은 간단합니다.
각 지수의 평균과 중앙값 구하기
각 지수들의 대략적인 분포
DAX, SMI, CAC, FTSE 지수들의 평균값이 중간값보다 높으므로,
윗쪽 특이값(outlier)이 존재하는 분포를 보인다고 할 수 있습니다.
각각 지수에 대한 boxplot을 만들기
(이 부분은 Range를 조정해서 사용하셔도 됩니다. 박스플롯 자체가 '중간 50%데이터'가 전체에서 어떤 분포를 보이는지에 대한 시각화입니다. 특이값이 많다는 것이 시사점일 수도 있어서 레인지를 디폴트로 두었습니다.)
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ

[IQR은 기초금융통계1.pdf의 20페이지에 나와있습니다.]

IQR 명령어와 변동계수 명령어를 이용합니다.
Boxplot(EuStockMarket)에서와 달리, IQR(EuStockMarket)은 모든 데이터의 IQR을 구하기 때문에, 컬럼을 각각 지정해주셔야 합니다.
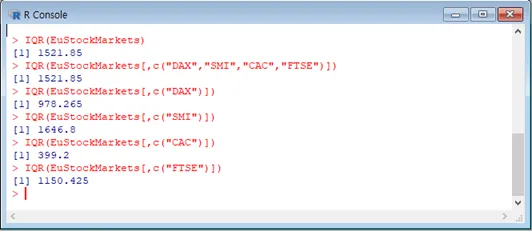
그리고 변동계수를 이용해서 어느 것이 가장 변동성이 큰 지 알 수 있습니다.

지수 DAX SMI CAC FTSE
IQR 978.265 1646.8 399.2 1150.425
변동계수 42.86605 49.257 26.04842 27.39241

즉, SMI의 변동성이 가장 큽니다.

[분산은 기초금융통계1.pdf의 33페이지에 나와 있습니다.]

𝑉𝑎𝑟(3𝑋 − 2𝑌 − 𝑍)
강의 노트에 나와있진 않지만 변수가 3개인경우에는

그래서
V(3X-2Y-Z)
=9V(X)+4V(Y)+V(Z)+2×3×(-2)cov(X,Y)+2×(-2)×(-1)cov(Y,Z)+2×(-1)×3cov(Z,X)
=9×2+4×3+4-12cov(X,Y)+4cov(Y,Z)-6cov(Z,X)
=[34-공분산 덩어리]가 됩니다.
그런데 서로 독립인 확률변수이므로 공분산은 0이되고
답은 34가 됩니다.

위에서 공분산에 0이 아닌 각 값을 입력해주면
= 34-12Cov(X,Y)+4Cov(Y,Z)-6Cov(Z,X)
= 34-12×1+4×2-6×1 = 34-12+8-6 = 24
답은 24가 됩니다.

[기초금융통계1.pdf의 40페이지를 따라하면 구할 수 있습니다.]
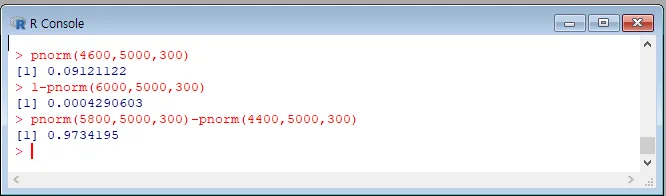
P(X<4600)
pnorm(4600,5000,300)
-> 0.09121122
P(X>6000) = 1-P(X<6000)
1-pnorm(6000,5000,300
-> 0.0004290603
P(4400<X<5800) = P(X<5800)-P(X<4400)
pnorm(5800,5000,300)-pnorm(4400,5000,300)
-> 0.9734195

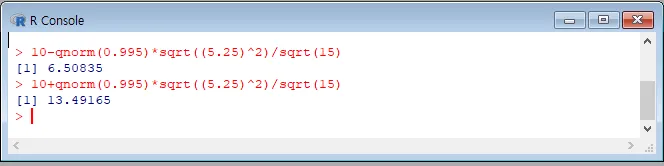
[기초금융통계1.pdf의 57페이지를 따라하면 구할 수 있습니다.]
10-qnorm(0.995)sqrt((5.25)^2)/sqrt(15)
--> 6.50835
10+qnorm(0.995)sqrt((5.25)^2)/sqrt(15)
--> 13.49165

[기초금융통계1.pdf의 56,55페이지를 따라하면 구할 수 있습니다.]
8-qt(0.975,14)sqrt(30.25)/sqrt(15)
--> 4.954202
8-qt(0.975,14)sqrt(30.25)/sqrt(15)
--> 11.0458
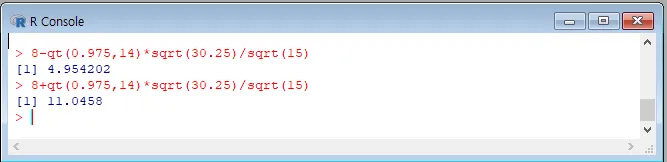

[기초금융통계1.pdf의 61페이지를 따라하면 구할 수 있습니다.]
'A) 표본의 크기가 충분히 크므로(30개 기준) 정규분포로 수렴한다고 보아
이익을 낸 투자자의 표본비율 23/125 = 0.18이므로
모집단(전체 투자자에서 이익을 낸 투자자)의 비율은
18.4%로 추정되며
'B)125×0.184 ≥ 10, 125×(1-0.184) ≥ 10임을 확인하고
23/125-qnorm(0.975)sqrt((23/125)(102/125)/125)
--> 0.1160723
23/125-qnorm(0.975)sqrt((23/125)(102/125)/125)
--> 0.2519277
신뢰구간은 [0.1160723,0.2519277]입니다.


이거 꽤 어렵습니다. 시간도 오래걸리구요. 혹시나 오답일 수 도 있어서 계속 검증 중입니다.
[기초금융통계2.pdf의 9페이지와 23~26페이지를 참조하면 구할 수 있습니다.]
-------------정정합니다. 지난주 함수 입력시 오타로 인해 내용에 큰 영향을 끼쳤습니다. (feat. 박순영님)---
먼저 이해해야할 개념이 있습니다.
P-value가 뭐야.
샘플링의 으로 모분포를
자 예를 들어보겠습니다.
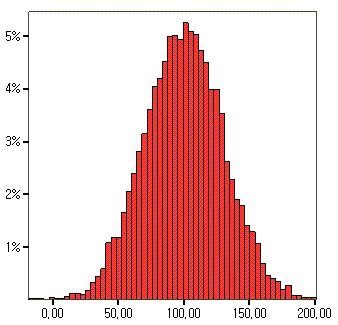
모분포가 10,000개의 값으로 된 데이터가 있습니다.(평균이 100.3023입니다.)
그런데 이 데이터를 활용한 어떤 가설검증을 위해, 모든 데이터를 전부 검증하기는 어렵습니다.
그래서 이중 몇 개를 뽑아서(sampling) 검증하는 것이죠.
그런데 이 샘플링의 평균이 모분포의 평균과 유사할까요?
예를 들어
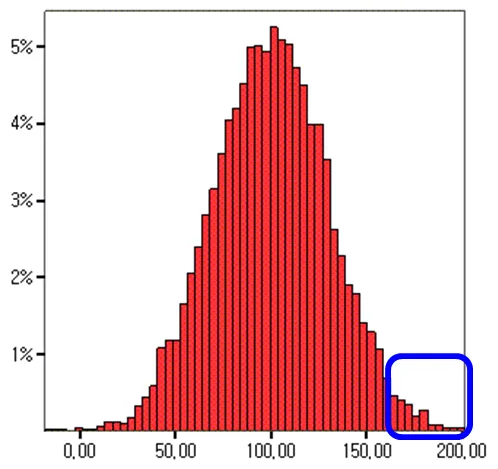
이런 식으로 파란 네모를 샘플링하게 되면 모분포의 평균과 많이 다르게 됩니다.
즉, 내가 추출한 데이터의 평균이 모분포의 평균에 얼마나 유사한가 가 관건인 것이죠.
정리를 하면, 가설검증이라는 것은 전체 데이터의 일부만을 추출하여 평균을 내고, 그 평균이 전체 데이터의 평균을 잘 반영한다는 가정 하에 전체 데이터의 평균을 구하는 작업인데, 랜덤 추출된 데이터의 평균은 가끔 전체 데이터의 평균에서 멀어질 수 있게 됩니다.
따라서, 내가 추출한 이 데이터의 평균이 원래의 전체 데이터의 평균과 얼마나 다른 값인지를 알 수 있는 방법이 필요하게 됩니다. 이와 같은 문제 때문에 나온 값이 p-value 인 것이죠.
P-value의 정의를 살펴보자면,
p-value는 귀무가설이 맞다는 전제 하에, 관측된 통계값 혹은 그 값보다 큰 값이 나올 확률이다.입니다.
따라서 P-value가 너무 낮으면, 그렇게 낮은 확률의 사건이 실제로 일어났다고 생각하기 보다는 귀무가설이 틀렸다고 생각하게 됩니다. 그래서 귀무가설을 기각하고 대립가설을 채택하게 됩니다.
다음을 보시죠.
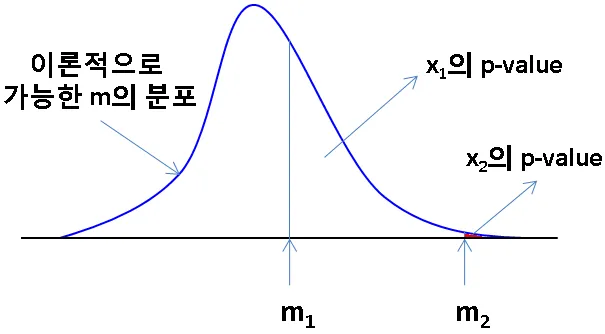
예를 들어 X2라는 샘플링을 추출합니다.
평균이 m2가 되는 것이죠. P-value는 매우 작습니다. 이럴 경우, 그렇게 희박한 일이 실제로 일어났다고 하기 보다는 저 이론적 분포를 가져온 귀무가설이 잘못되었다고 생각합니다.
반대로 X1이라는 샘플링에서는 평균이 m1이 됩니다. P-value가 매우 큽니다.
이런 경우는 귀무가설이 맞을것입니다. (통계적 용어로는 기각하지 못한다)
(http://adnoctum.tistory.com/332 링크를 참고했습니다)

(기초금융통계2.pdf의 8페이지입니다.)
자. 그럼 9번 문제를 풀어보겠습니다.
'1) 가설설정
'2) 유의수준(α)결정
'3) 검정통계량 계산
'4) P-value 계산
'5) 검정통계량 > t분포표의 임계값
p-value< 유의수준
이면 귀무가설기각, 대립가설 채택
아니면, 귀무가설 기각 하지 못함
입니다. 물론 R을 쓰기때문에 훨씬 편하게 계산합니다만, 일단 정석으로 해보겠습니다.
'1) 가설을 세웁니다.
가설 : 평균 투자 이익의 모평균을 µ라고 했을 때,
귀무가설. 평균 투자이익은 0%보다 크지 않다. vs 대립가설. 평균 투자이익이 0%보다 크다.
H_0: µ≤0% vs H_1: µ >0% (단측검정)
귀무가설을 내가 주장하는 가설(즉, 투자이익이 0보다 크다)로 착각하시면 안됩니다.
저도 헷갈렸습니다만, 귀무가설은 歸無가설입니다. Null값입니다.
대립가설이 검증해야하는 주장입니다. 여기서는 평균 투자 이익이 0%보다 큰지 검정해야합니다.
'2) 유의수준 α = 5%입니다.
'3) 검정통계량을 계산해야합니다.
검정통계량 구하는 공식
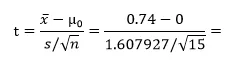
(여기에 편차와 평균은 R을 이용하여 구했습니다.)
(실은 이럴 필요는 없어요...그냥 t.test 면 끝나는..;;)

잠깐, 여기에서 궁금한 점이 생깁니다. 샘플자료에서 -1.5%, 2.3%...으로 되어있는데 이를
R에서 (-1.5, 2.3,...)으로 표현해야하는지, (-0.015,0.023,...)으로 표현해야하는지,
%단위로 인한 표현방식때문에 P-value가 얼마나 달라지는지 궁금해집니다.
답은 하고싶은대로 하세요 입니다. P-value가 달라지지 않습니다. 뒤에서 한번 더 설명하겠습니다.
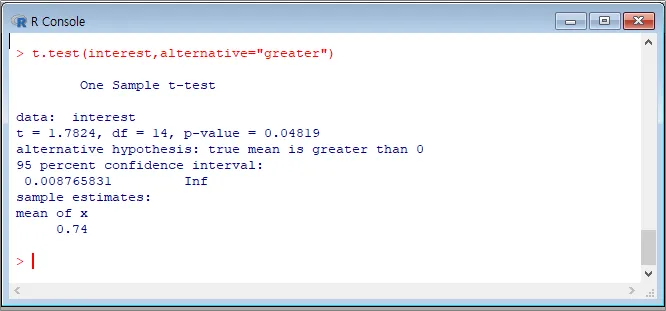
R에서위 자료의 검정통계량을 구해봅니다.
(t값과 p-value가 함께 도출됩니다.)
단위를 달리 표현해보겠습니다.
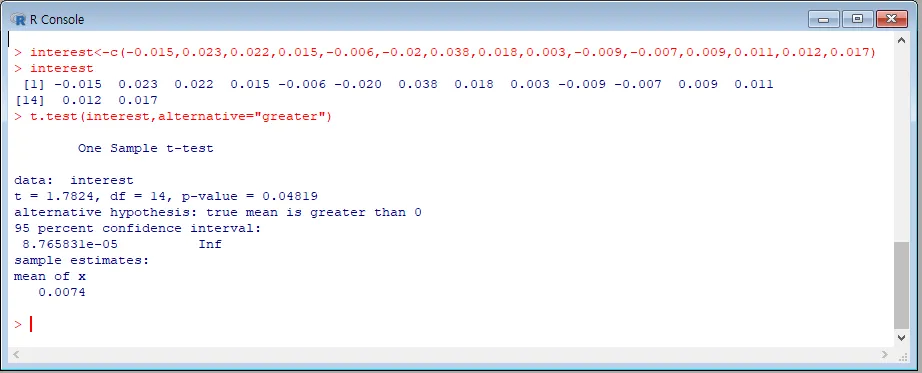
(단위를 다르게 해도 t와 P-value는 같습니다.)
검정통계량t = 1.7824입니다.
출처: http://pubdata.tistory.com/42 [Practical Understanding of Big Data & Front-end Dev.]

'4)P-value= 0.04819입니다.
'5) t-분포표의 자유도 14, α = 5%의 값인 1.761보다 t값이 크기 때문에
통계적으로 유의하며 귀무가설을 기각하고 대립가설을 채택합니다.
P-value가 0.04819로 a(=0.05)보다 작습니다.
귀무가설인 [평균 투자이익이 0%보다 크지않다.]를 기각합니다.
즉, 평균 투자이익이 0%보다 큰 것을 검정했습니다.
이번엔, 정규성을 체크해보겠습니다.
정규성 검정은
- 귀무가설 : 데이터가 정규분포를 따른다 vs 대립가설 : 데이터가 정규분포를 따르지 않는다.
- p-value 가 크기 때문에 귀무가설 기각하지 않고, 정규성 가정에 별 문제가 없다고 판단함
이 충족되어야 합니다.
qqnorm(interest)
qqline(interest)

Q-Q plot 해석 방법은, 경험분포(empirical distribution)와 이론적 분포(theoretical distribution)가 서로 근접하게 분포하고 있으면 정규성을 띤다고 평가하며, 반대로 경험분포와 이론적 분포가 서로 멀어질 수록 정규분포를 띠지 않는다고 평가합니다. 다시말하면, 정규확률 산점도 그림에서 대각선(qqline())을 기준으로 산점도 점들이 가깝게 선형을 이루며 붙어 있으면 정규성을 띤다고 평가하고, 그렇지 않으면 정규성을 띠지 않는다고 보는 것입니다.
다음으로 nortest 패키지를 설치해봅니다.
(첫 수업때처럼 미국 텍사스로 고르시는 게 오류를 막을 수 있습니다.)
다음으로는 일사천리입니다.
27,28P의 명령어를 사용합니다.

P-value가 0.5보다 크기 때문에 귀무가설을 기각하지 않고, 정규성 가정에 별 문제가 없다고 판단합니다.
이것도 길게 설명했지만, 이해를 돕기 위해서 그런것이고...요약해보자면
'A) 평균 투자이익이 0%보다 큰지 검정
'B) 정규성을 만족하는지 체크 입니다
'A)투자이익 0보다 큰지 검정
'1) 귀무가설 : 0% 보다 크지않다 vs 대립가설 : 0%보다 크다
'2) 유의수준 α = 5%
'3) 검정통계량 결정 t= 1.782424
'4) P-value는 0.04819로써
'5) P-value가 0.05(α =5%)보다 작으므로 귀무가설을 기각할 수 있습니다. 투자이익 0보다 큽니다.
'B) 정규성 검정
'1) 귀무가설 : 데이터가 정규분포를 따른다 vs 대립가설 : 데이터가 정규분포를 따르지 않는다.
'2) Nortest 설치해서 불러오기
'3) 각종 정규성 검정 명령어 불러오기
'4) P-value가 0.05보다 크므로 정규성 검정 완료입니다.
시간에 쫓겨 잘못된 풀이를 한 지난 1주간을 반성합니다.
제가 풀이집(?)을 블로깅으로 공유하는 이유는 학부생도 아니고 하니..
과제에 얽매이지 말고, 스트레스 받지말고 함께 공부하는 분들과 좀 더 쉽게쉽게 이해하고 잘 지냈으면
하는 마음인데 잘못된 풀이내용을 적어놔서...굉장히 부끄럽네요.
반성의 의미로...언제든 혹시 이해가 잘 안가는 부분을 여쭈시면, 아는 선으로 설명드리겠습니다.
그래도 여기까지 읽느라 고생많으셨고....도움이 되면 좋겠네요^^