파이썬의 기초과정
https://steemit.com/kufmba/@grooveflow/1
파이썬 구조 또는 명령어 익히기 시작
https://steemit.com/kufmba/@grooveflow/2
에 이어서 계속해 봅니다.
(Lecture Note의 27페이지입니다.)

String 즉, 문자열에 대해 익혀봅니다.
리스트와 비슷하나 글자 한자한자가 구성요소라고 합니다. 일단 무슨말인지 보겠습니다.
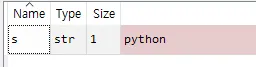
s='python' #s라는 변수에 'python'을 입력합니다.
변수창을 보니 아래와 같이 입력됩니다.
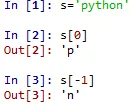
 여기서 s[0]은? s[-1]은?
여기서 s[0]은? s[-1]은?
python에서 정방향 0번째 값과 역방향 첫번째값을 찾는것입니다.
(인덱스의 순서는 0으로 시작하는 것을 기억하셔야 합니다.]
 이런 내용이 나오게 됩니다.
이런 내용이 나오게 됩니다.
여기 s='python'에 s[0]='c' 를 입력하면 어떻게 될까요?
p대신에 c가 입력될까요?
아닙니다. immutable (불변의) 즉 변하지 않는다는 거죠.

TypeError: 'str' object does not support item assignment
str(문자열)은 변경할 수 없다는 내용입니다.
(더 찾아보니, 절대 변경안되는 건 아니에요. 이런건 나중에..)

len명령어를 알아보겠습니다.
len(s)
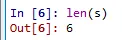
글자수를 물어보는 명령어네요.
다음은 '+'를 사용해봅니다. 문자열끼리 연산이 되네요
s='Hello'+'World'
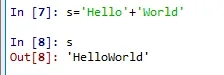
으로 결과값이 나오고..변수 상태창도 변한것을 볼 수 있습니다.
(좀전까지는 python이었는데 HelloWorld로 바뀌었죠)

응용도 해볼까요.
s='python'
s=s+'hello'+'world'
를 하면?
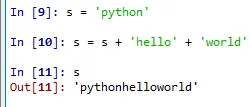
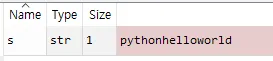
변수상태창도 pythonhelloworld로 바뀌었습니다.
자 이번엔 변수에 Tom's book을 입력하려면 어떻게 할까요?
일단 생각나는 대로 해봅니다.
s='Tom's book'
하면...바로 에러뜹니다.
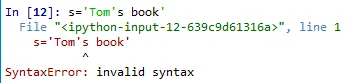
보세요. 작은 따옴표가 Tom을 둘러싼것('Tom')으로 인식한다는 거죠.
그러니 뒤에 문자들(s book')은 작은 따옴표가 하나만 붙어있오니 에러가 뜨는 거죠.
이럴 때는 둘러싸는 기호를 큰 따옴표로 둘러싸면 해결됩니다.
s="Tom's book"

또 '\'(백슬래쉬)를 사용하는 방법도 있습니다.
큰따옴표로 둘러싸지 않고, 백슬래시로 소유격인 어포스트로피에스('s)를 표현할 수 있습니다.
s='Tom\'s book' # 즉, 어포스트로피에스('s)를 쓰기 위해서는 백슬래시와 함께 씁니다.[\'s]

백슬래시와 함께 사용하면 소유격(어포스트로피)의 작은 따옴표를 살리고,
문자열을 둘러싼 작은 따옴표는 큰 따옴표로 바뀐 것을 볼 수 있습니다.
(이럴 바에야 그냥 애초에 큰 따옴표로 둘러싸면 되겠고만...나중에 이유를 알겠죠.)
다음은 큰 따옴표를 3개 연속으로 사용하여 문자열을 둘러싸면 큰 따옴표 1개로 둘러싼것과 같다는 내용입니다.
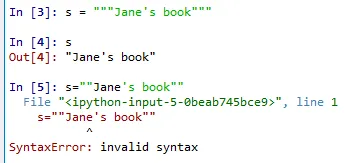
큰 따옴표 2개는요?유효하지 않다고 나오네요.
아마 큰 따옴표를 2개 쓰는 경우는 더러 있기 때문인 듯 싶네요.
"He said,"My name is Tom."" she said.(그녀가 말하기를 "그는" 내 이름은 Tom이야."라고 말했어")

이번에는 String의 함수를 공부해보겠습니다.(29p)

s에 String 즉 문자열을 입력합니다.
s='Today is a good day'


후, dir(s)를 사용하면 문자열에 대한 함수들이 주르륵 나옵니다.
이 중에 Split 라는 함수를 사용해보겠습니다.어떤 함수일까요?
s.split()

괄호 안에 아무런 값도 넣어 주지 않으면 공백(스페이스, 탭, 엔터등)을 기준으로 문자열을 나누어 줍니다.
값을 넣어주면 어떻게 될까요? 예를 들어 첫문자인 Today의 T와 good의 g를 넣어보겠습니다.
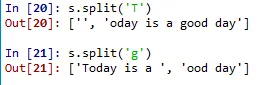
넣어준 문자를 기준으로 문자열이 나뉘는 것을 볼 수 있습니다.
문장 내 여러번 표시되는 'o'를 넣으면?

'o'의 갯수만큼 나뉘는 걸 볼 수 있습니다.
strip 함수도 소개하고 있습니다.
적당한 예제가 없어서 검색해보니 다음의 내용이 나옵니다.
양 끝단의 공백을 없애는 기능이었네요.
이 함수 s.strip()의 괄호안에 공백이 아닌 문자를 입력하면 어떻게 될까요?

양 끝단의 문자('y' 또는 'T'들을 입력해서 실행하면 해당 문자는 삭제되어 나오지만,
안쪽의 문자들은 영향을 미치지 못하네요.
s='Today is a good day'
s.split('a') #s의 value a 기준으로 나눠라
s.split() #s의 value 공백 기준으로 나눠라
실행해보면

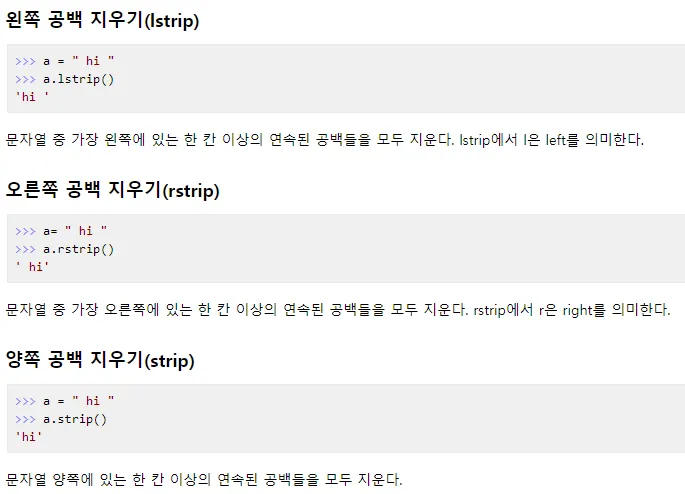
a=' Hi, there. '
a.lstrip() #a의 왼쪽 value 공백을 제거하라
a.rstrip() #a의 오른쪽 value 공백을 제거하라
a.strip() #a의 양쪽 value 공백을 제거하라.
실행해보면

s.rstrip('y') #s의 오른쪽 끝의 value 'y'를 제거하라.
s.lstrip('T') #s의 왼쪽 끝의 value 'T'를 제거하라
s.strip('T') #s의 양쪽 끝의 value 'T'를 제거라하
실행해보면

k='he establish'
k.rstrip('h') #k의 오른쪽 끝의 'h'를 제거하라
k.lstrip('h') #k의 왼쪽 끝의 'h'를 제거라하
k.strip('h') #k의 양쪽 끝의 'h'를 제거하라
실행해보면

s.find('is') #s의 'is'의 위치를 구하라.
s.find('g') #s의 'g'의 위치는 구하라.
실행해보면

s.replace('o','a') #s의 'o'를 'a'로 교체하라
실행해보면
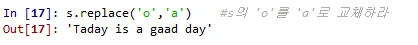

다음은 string문자열이 숫자로만 되어있을 때 이를 숫자로 치환하는 방법을 보겠습니다.
먼저 문자열 변수가 숫자로만 되어져있는지를 판별해야겠죠?
x='123' #x는 '123'이다
x.isdigit() #x는 숫자로만 되어있는가

참(True) 값이 나옴을 알 수 있습니다.
자 그럼 숫자로 이루어진 문자열들을 계산하면 어떻게 되는지 보겠습니다.
x='123' #x는 '123'이다
y='123.123' #y는 '123.123'이다.
이를 실행시키면

변수창에도
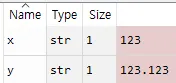
x의 value 123과 y의 value 123.123이 str로 입력됨을 볼 수 있습니다.
x+y
를 하게되면? 246.123? 만약 숫자로 인식한다면 246.123이 나와야 하죠. 하지만..
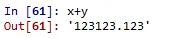
문자열이기 때문에 평행하게 나열함을 볼 수 있습니다.
그리고 문자열을 숫자로 인식하는 방법은 다음과 같습니다.
a=float(y) #a는 y를 유리수화함
b=int(x) #b는 x를 정수화 함
이를 실행시키면

변수창 또한

좀 전의 x와y는 str로 표기되어있고 a와b는 float, int로 표기됨을 알 수 있습니다.
x+y
를 하게 되면? 이번에는 246.123으로 나오지 않을까요?

그렇네요. 246.123으로 나온 것을 확인할 수 있었습니다.
가만 그렇다면 숫자로 된 변수도 문자열로 바꿀 수 있지 않을까요?
c=str(a) #c는 a를 문자열화 함
d=str(b) #c는 b를 문자열화 함
실행해보면

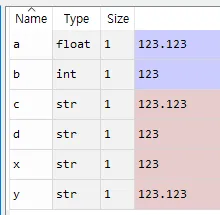
정말 c와 d는 str로 표기됨을 볼 수 있습니다.
자. 이번에는 변수로 문장을 만든 다음, 변수에 내용을 집어넣는 방법을 보겠습니다.
무슨 말인지 설명이 어렵긴 하네요. 일단 보시면 됩니다.
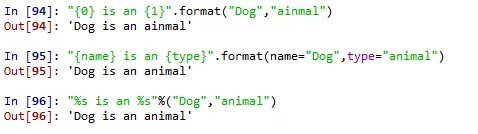
"{0} is an {1}".format("Dog","ainmal")
"{name} is an {type}".format(name="Dog",type="animal")
"%s is an %s"%("Dog","animal")
실행해보면
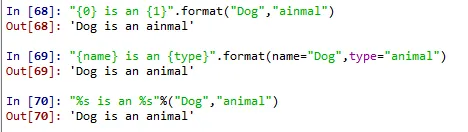
'Dog is an animal'이라는 문장을 만들기 위해 {0}과 {1}, {name}과 {type}, 그리고 %s 라는 변수를 만들고 나중에 집어넣는 내용이었습니다.
아마 나중에 저 안의 내용을 어떻게든 교체하는 방식으로 사용하지 않을까 싶습니다.
여기까지 string 내용이었습니다.
지금까지 했던 내용을 한번 쑥 정리해보겠습니다.
사용코드
a="hello, World"
print(a)
b=a.capitalize() #b는 a의 첫글자를 대문자화함
print(b)
c=a.upper() #c는 a의 모든 글자를 대문자화함
print(c)
a=1
print(a,type(a)) #a의 값과 a의 유형을 출력하라
b=1.1
print(b,type(b)) #b의 값과 b의 유형을 출력하라
c=1+2j
print(c,type(c)) #c의 값과 c의 유형을 출력하라
d=True
print(d,type(d)) #d의 값과 d의 유형을 출력하라
e=c+d
print(e,type(e)) #e의 값과 e의 유형을 출력하라
f=a*b
print(a,'*',b,'=',f,type(f))
a=False #True는 1, False는 0의 값을 가짐
b=a+1
c=a*3
print(a,type(a))
print(b,type(b))
print(c,type(c))
a=['python',1,5]
print(a)
a[1] #list내의 index를 지정할때 대괄호[]를 사용, index에서는 0이 제일 처음
a[0] #a의 0번 인덱스(제일 처음)
a[0:2] #a의 0번 인덱스부터 2번 인덱스 전까지
a[:] #a의 모든 인덱스
a[1:] #a의 1번인덱스(두번째)부터 끝까지
x=[1,2,3,4]
x[1]='python' #x의 1번 인덱스(두번째)를 'python'으로 교환
print(x)
y=[5,6,7]
x+y
x*2
x=[1,2,3,4]
x.append(5)
x.extend([5,6])
print(x)
x.append([5,6])
print(x)
x.index(3) #x의 value3의 index값을 구하라.
x.remove(1) #x의 value1을 remove하라.
x.count(5) #x의 value 5값을 세어라.
1 in x #x에 1이 있다(참/거짓)
5 in x #x에 5가 있다(참/거짓)
min(x) #x의 최소 value를 구하라.(여기서는 문자열이므로 크기비교 불가)
max(x) #x의 최대 value를 구하라.(여기서는 문자열이므로 크기비교 불가)
len(x) #x의 길이를 구하라.
del x[0] #x의 0번 인덱스(첫번째)를 삭제하라.
del x[4] #x의 4번 인덱스(다섯번째)를 삭제하라
s='python' #s에 python을 입력하라
s[0] #s의 0번 인덱스(첫번째)
s[-1] #s의 -1번 인덱스(뒤에서 첫번째)
s[0]='c' #s의 0번 인덱스에 c를 입력하라, string은 immutable 이므로 error 발생함
len(s) #s의 길이
a='Hello'+'World'
b='Tom\'s book'
print(b)
c="""jane's book"""
print(c)
d='"He said,"My name is Tom."she said'
print(d)
s='Today is a good day'
s.split('a') #s의 value a 기준으로 나눠라
s.split() #s의 value 공백 기준으로 나눠라
a=' Hi, there. '
a.lstrip() #a의 왼쪽 value 공백을 제거하라
a.rstrip() #a의 오른쪽 value 공백을 제거하라
a.strip() #a의 양쪽 value 공백을 제거하라.
s='Today is a good day'
s.rstrip('y') #s의 오른쪽 끝의 value 'y'를 제거하라.
s.lstrip('T') #s의 왼쪽 끝의 value 'T'를 제거하라
s.strip('T') #s의 양쪽 끝의 value 'T'를 제거라하
k='he establish'
k.rstrip('h') #k의 오른쪽 끝의 'h'를 제거하라
k.lstrip('h') #k의 왼쪽 끝의 'h'를 제거라하
k.strip('h') #k의 양쪽 끝의 'h'를 제거하라
s.find('is') #s의 'is'의 위치를 구하라.
s.find('g') #s의 'g'의 위치는 구하라.
s.replace('o','a') #s의 'o'를 'a'로 교체하라
x='123' #x는 문자열'123'이다
x.isdigit() #x는 숫자로만 되어있나?
y='123.123' #y는 문자열'123.123'이다.
x+y
a=float(y) #a는 y를 유리수화함
b=int(x) #b는 x를 정수화 함
a+b
c=str(a) #c는 a를 문자열화 함
d=str(b) #c는 b를 문자열화 함
"{0} is an {1}".format("Dog","ainmal")
"{name} is an {type}".format(name="Dog",type="animal")
"%s is an %s"%("Dog","animal")
코드들을 실행해보세요. 아래의 내용이 나옵니다.








.


.
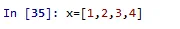



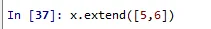

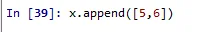

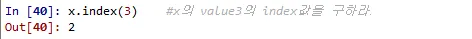
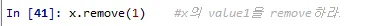

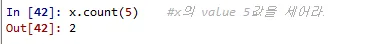





.


.


.


.



.


.