안녕하세요! 저는 파이썬 초보 rexypark입니다…
파이썬을 한달 정도 배우고 시간이지나니 조금씩 잊혀지는게
느껴져 파이썬 연습문제를 풀고 블로그에 포스팅 하려고 합니다!
많이 부족하지만 고수님들 보시고 수정댓글 항상 환영이고 저의
공부에 큰 도움이 될 것 같습니다. 많이 도와주세요 파이썬 고수님들!!
오늘은 텍스트 정제 예제입니다!
문제
사용된 단어의 횟수 알아내기
01_01 파일은 영어 단어로 구성된 일반 텍스트 문서이다.
단어는 공백으로 구분된 문자열(특수 기호 포함) 이라고 정의한다.
단어와 사용된 횟수와 함께 출력.
단, 대소문자가 다른 경우 다른 단어라고 정의한다.
01_01.text
Python is an easy to learn, powerful programming language. It has efficient high-level data structures and a simple but effective approach to object-oriented programming. Python��s elegant syntax and dynamic typing, together with its interpreted nature, make it an ideal language for scripting and rapid application development in many areas on most platforms.
The Python interpreter and the extensive standard library are freely available in source or binary form for all major platforms from the Python Web site, http://www.python.org/, and may be freely distributed. The same site also contains distributions of and pointers to many free third party Python modules, programs and tools, and additional documentation.
The Python interpreter is easily extended with new functions and data types implemented in C or C++ (or other languages callable from C). Python is also suitable as an extension language for customizable applications.
This tutorial introduces the reader informally to the basic concepts and features of the Python language and system. It helps to have a Python interpreter handy for hands-on experience, but all examples are self-contained, so the tutorial can be read off-line as well.
For a description of standard objects and modules, see The Python Standard Library. The Python Language Reference gives a more formal definition of the language. To write extensions in C or C++, read Extending and Embedding the Python Interpreter and Python/C API Reference Manual. There are also several books covering Python in depth. …….(더깁니다)
내가 쓴 식
설명 주석

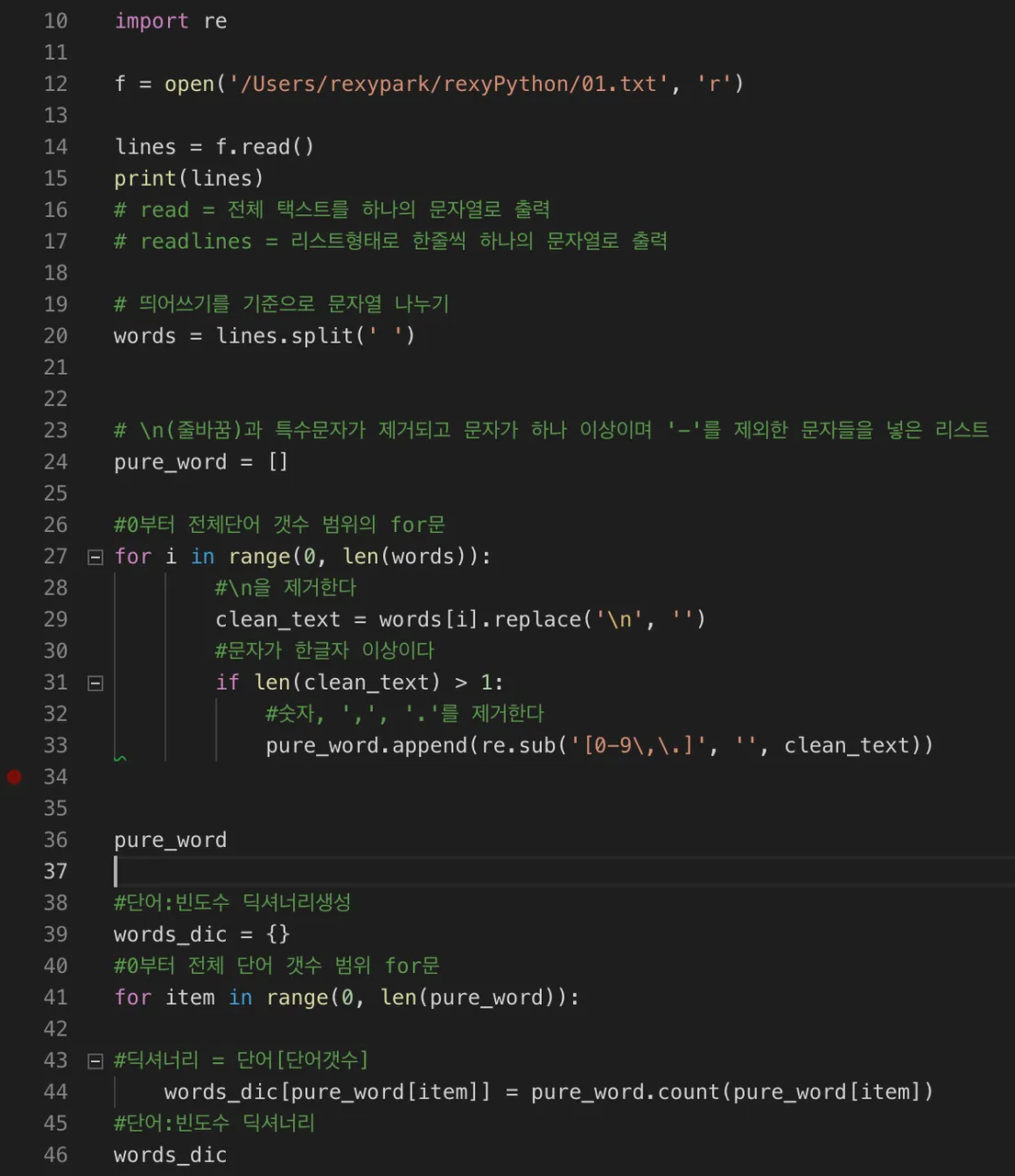
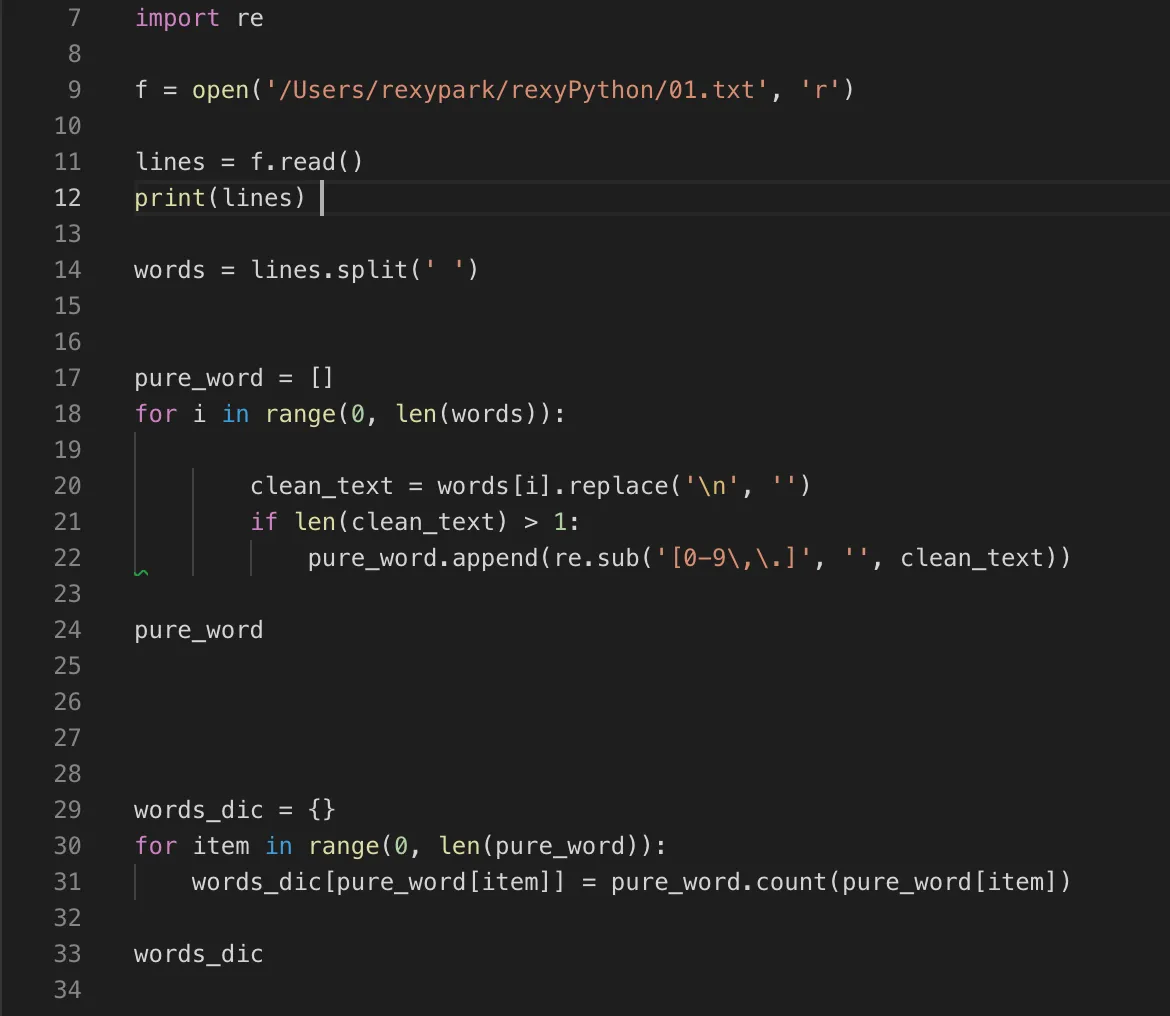
텍스트 식
————————————————————————
import re
f = open('/Users/rexypark/rexyPython/01.txt', 'r')
lines = f.read()
print(lines)
words = lines.split(' ')
pure_word = []
for i in range(0, len(words)):
clean_text = words[i].replace('\n', '')
if len(clean_text) > 1:
pure_word.append(re.sub('[0-9\,\.]', '', clean_text))
pure_word
words_dic = {}
for item in range(0, len(pure_word)):
words_dic[pure_word[item]] = pure_word.count(pure_word[item])
words_dic
————————————————————————
읽어주셔서 감사합니다 ㅎㅎ
아직 많이 부족해서 실수가 많지만 귀엽게 봐주시고 수정댓글은
항상 대환영 입니다 :)
사용에디터 : 아나콘다-spyder
codeviewer - Visual Studio
OS : Mac