Data. It is the lifeblood of all AI development.
Some are not theorizing that we will run out of data. This was first projected to occur in 2024, something that is now pushed out to 2027 or 2028 by many estimates.
Are we headed for a data crunch? This is a worthwhile topic to dig into.
In this article we will look at where we are and what is likely to happen.
Data: The Fuel of the Digital Age
We cannot deny the fact that we generate a massive amount of data. This is something that started years ago. The first conversation centered around the cost of storage. Fortunately, the prices of hard drives have consistently been dropping, forming their own "Moore's Law" albeit not quite as fast.
With that problem resolved, the feeding of LLMs, has gotten some concerned. The growth in this arena is mind-numbing, with total GPU compute doubling every 6 months. We can think of this as Moore's Law on steroids.
If compute keeps growing, how are we going to feed it. This is a chart put together by Brian Wong, detailing what he sees as the potential growth of compute used by XAI for Grok.
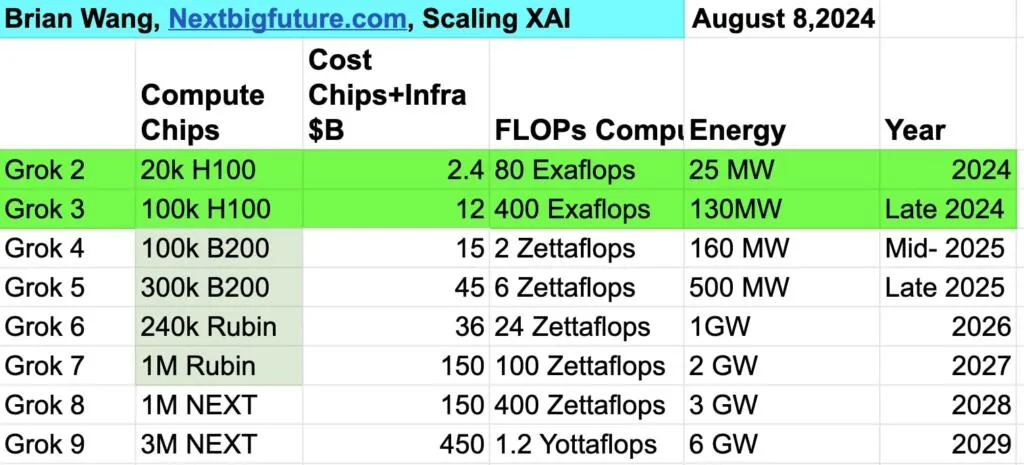
The 100K H100 are already in place. When we look at the Blackwell series, that was already stated as on order, at least the first 100K. Some of the rest of these might already have orders in. To be honest, this is not something that I follow as closely as he does.
NVIDIA put the specs for Rubin out. next is not something I am familiar with but that doesn't mean it isnt accurate.
How accurate this are is not relevant for our discussion. The important criteria is the fact that we are seeing massive amount of compute going in over the next couple years. We are looking at billions of dollars for these systems.
Of course, this is across the board. We will likely see the same thing with Meta, Google, Amazon, and OpenAi. TSMC is going to be very busy.
Beyond that, we come back to the data question.
Where are we going to get this from.
Data Explosion
The topic of data has to be broken down.
One key to this is what is structured or not. That is what truly gives it value. Of course, we have to start somewhere, thus unstructured is used. However, it has to be manipulated, i.e. labelled, to be of major use.
Fortunately, much of the focus was on text. There is still a lot of video and audio which has not been fed in. Multimodal is something that is relatively new. Over the next few years, this is going to be used to a much larger degree.
Even with this, however, how are we going to have enough to feed these system in 2026 or 2027.
Here is where we could be a massive data explosion.
Real world AI is the next hotbed. This is going to be embedded in robots and different items that move throughout our spaces. This will add another dimension completely.
It will also send the volume of data skyrocketing.
There is a ton of data that we do not collect. This is generated by the entire global population but it never makes it into the Internet. Consider what we see while just sitting on a park bench. That data is imprinted in our minds but we don't upload to the cloud (at least not yet).
Consider if what "seen" with robots through cameras. From the prototypes I saw on video, there are at least 5 cameras on each robot. It is possible there are more. We also have to factor in the number of sensors in throughout the bot also.
All of this will generate a massive amount of data. It is going to create a feedback loop for these entities. A great deal of that compute will be fed data of this nature.
One big advantage is that it can be set up to be structured from the start. Hence, we are dealing with quality data from the beginning as the producers of the robots will know how to design the capture to best integrate into their system.
This is the direction we are heading. Meta trained Llama3.1, their latest model on 16K H100, the largest to date. Their next version is certainly going to top 100K also. We can see this across the board.
Compute is nothing without data. There are a lot of companies out there that want it. Big Tech is going to get it.
My question, as always, what about the start ups? That is something that we have to keep considering.