
I thought I'd share a bit about how I create AI art.
AI art uses generative representational learning trained on collections of images labeled by humans. It learns semantic relations between language and visual patterns.
You paint by priming it with a description of what you'd like to see. However language is infinitely interpretable. A single description can be painted infinite ways.
So there is a level of randomness or stochasticity in the output.
I wanted to draw St. Vincent. These models have some understanding of the structure of even mildly famous people's faces. Often it will at least understand key features, and if I can collect enough key features it will resemble the person.
When you start your canvas is layers of gaussian noise:

Kind of looks likes clouds huh? Like how you can see patterns in the clouds?
Well the model looks for patterns in the clouds that look like the thing you want to see.
The model doesn't just look at the image as a whole to evaluate whether it looks like the description. It takes sub-cuts of the image and evaluates those too. When it takes smaller cuts, it can add more detail. When it takes larger cuts it can focus more on the larger picture.
For things like landscapes, it can paint straight from noise well. In nature there are a lot of repeating sub-patterns. So it has a lot of things to paint, and you don't need a lot of coherence.

This series for example takes advantage of the fact that coral has a lot of subtleties to draw and if it's looking at every section of the image the same then it's going to do great.
But most images don't look as composed as this.
Most look like this:

It's kind of just throwing random coral and clouds and shit everywhere. It looks beautiful but it's not composed as a full image.
I basically accepted this in my early art and just tried to paint vaguely beautiful patterns to see how well I could control color and lighting:

In order to get better composition, in early steps of mutation from the initial noise, the samples need to mostly focus on the whole picture so it can sketch something and not get lost in the details:
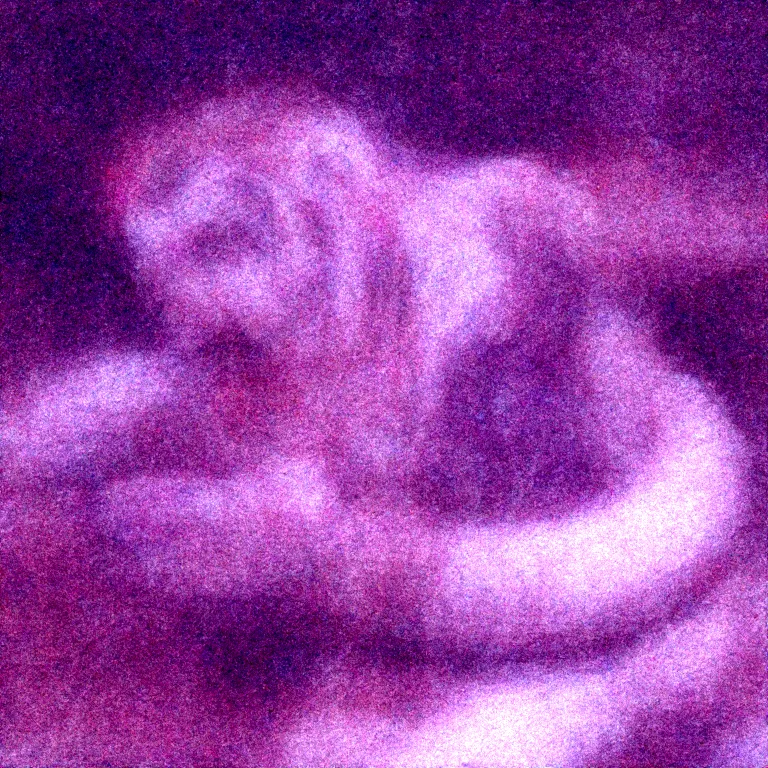
This was primed with "a monkey riding a tiger", you can kind of see mammalian features forming in the noise, and there seems to be one coherent figure.
If I let this keep going it would fill in all the detail depending on how the cuts are made to evaluate against the description.

Okay weird, kind of bad. Kind of looks like it. But mostly it's shit.
Most images output by the model are like this. Vaguely in line with the description but still not that coherent.
However, if you tune the parameters just right, and say exactly the right thing, and let the same prompt run many times, you have somewhere to start from.
SO! Back to St. Vincent.
I primed a model with well tuned parameters for generating faces with the phrase "st. vincent" to see if it "knew" who she was.
My first few outputs looked like this:

Wow! It can paint a lot of things out of nothing! Some things are coherent almost immediately! Plus I recognize her face here. So it's clear to me the pattern of her likeness is in there somewhere, I just need to suss it out. It's also interpreting the religious interpretation and I don't want that. But I feel confident I can paint her with these models with a little elbow grease and a few hours and a few hundred renders. I could still paint her if it didn't have images of her in the training set but it would be a lot harder.
For example, I recently rendered an image of owocki who is not that well known.
In this case, he has a very particular color hair and beard. If I capture that I basically capture a lot of his essence.

He also is all about green pill and regenerative crypto-economics so the general vibe crafts his likeness. But it's definitely way easier if the model has seen images of the person you're trying to paint.

After a few renders I find something that I feel is just embodying St. Vincent without the religious energy.

These are okay. It gets her hair and it's bringing in the music elements. I also was able to get rid of the religious elements. They're still fairly clumsy drawings. They don't look anywhere as complex as the cover photo.
I also really don't like the color. I'd love to just say what colors but every word added affects the interpretation of all other words. So I use other words associated with color patterns like "80's" or "90s".

Finally I hone in on what I'm looking for:

Something that I feel really embodies her energy and style. I feel like she has an 80's aesthetic but there's something classic there as well. Here I have found a local optima of what I perceive as quality that aligns with what "feels right"
I decide I really like the bottom right image but I'd like her to have a chin. How do I approach this?

Well every change in word is going to dramatically change the output. I need to retain some features and change others. So I make variations on this image with different hyperparameters. Hyper-paramters are values that affect how the model will draw.
But I can also just take a very small step in latent space. It will mutate the image randomly.
Latent space is where all the patterns are encoded. Your location in it along with the hyperparameters determines the output by the model.
A point in latent space will output similar but different images.
So I start mutating the image:

Okay cool... Definitely looking like a mutant.
Her face is now ... on at least. Her face is not off. It's roughly in the right place... Let's take this point in latent space and start looking in different directions to find semantically similar outputs.

Well here's... a full nose... and a mouth! Let's go from here!

Fuck. Fuck, this variant is stunning. But the mouth is gone. I know with the current access I have to the tools I have limited control over what direction I can move in latent space.

I finally have a coherent face with lips, eyes, nose and hair. But it has lost something.

I do many more nested iterations of mutation seeking to regain some of the earlier spark. And the final product is great. And it does have a similar energy and it definitely is well composed. But did I lose something along the way? Maybe.
Ultimately I still wish I could have simply added a chin to this image:
Everything about it is stunning. But you aren't painting with pixels, you're painting with patterns. There are other neural tools you can try, or just photoshop which I did try but ultimately I was unsatisfied.
In the future the tools will evolve. Who knows how the interface will improve?
But I am sure that these models can construct any image with enough iterations and refinement. And that's an exciting and fascinating prospect.
EDIT:

I decided I needed to know how she looked completed and completed her via more traditional means.