Hola hivers. He creado un pequeño script para extraer los enlaces y guardarlos en un archivo de texto del sitio web https://www.sciencealert.com/. Sciencealert es un sitio web que se caracteriza por ofrecer noticias sobre el ámbito científico; descubrimientos, avances y problemas de la actualidad relacionados con la ciencia.
A mi parecer, este sitio web dispone de una sección de comentarios y opiniones bastante interesante y redactado de una forma que facilita la comprensión del contenido.
En fin, no tengo muchos detalles que agregar para siempre quedara a criterio de ustedes realizar sus apreciaciones para definir si el sitio web es apto a su criterio para valorizar su contenido.
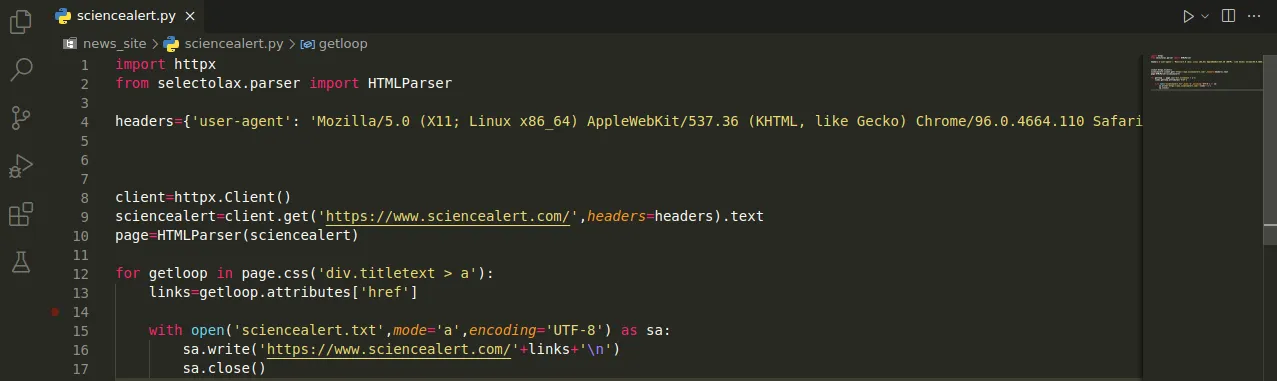
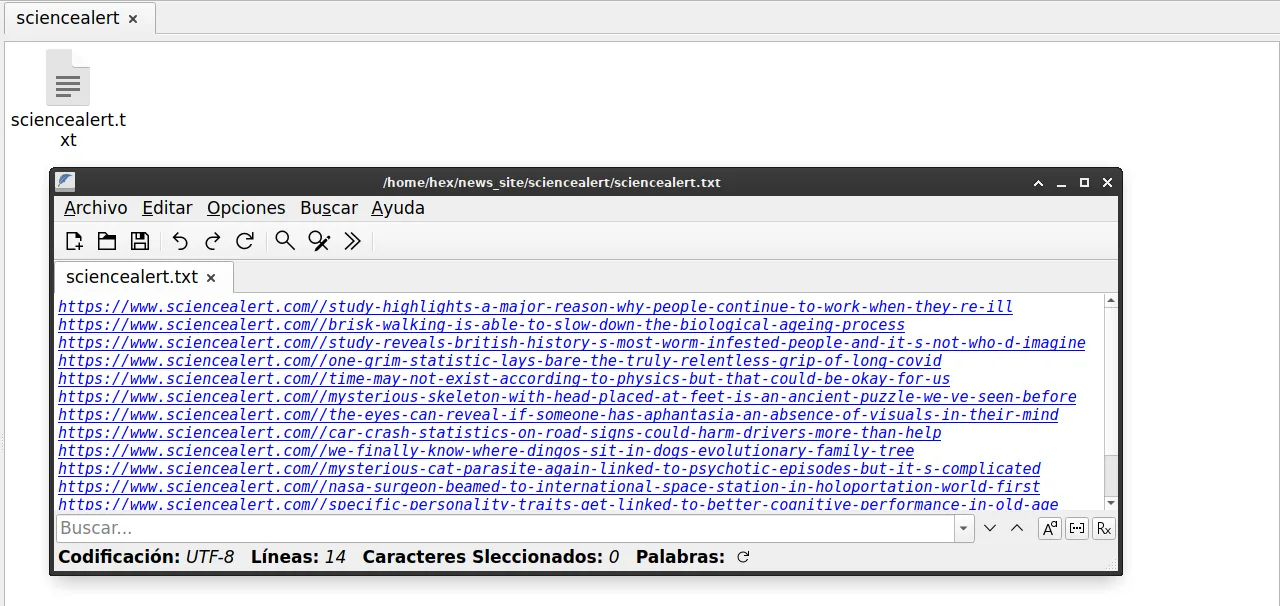
Me despido de ustedes hivers, Abajo adjunté el script elaborado en Python con sus respectivos resultados gracias por leer. Hasta la próxima publicación.
Este script fue ejecutado con Python 3.9.2 en el sistema operativo Debian Bullseye.
Hi hivers. I have created a small script to extract the links and save them in a text file from the website https://www.sciencealert.com/. Sciencealert is a website that is characterized by providing news about science; discoveries, advances and current issues related to science.
In my opinion, this website has a section of comments and opinions quite interesting and written in a way that facilitates the understanding of the content.
In short, I do not have many details to add to always remain at your discretion to make your assessments to define if the website is suitable in your opinion to value its content.
I say goodbye to you hivers, Below I attached the script developed in Python with their respective results, thanks for reading. Until the next publication.
This script was executed with Python 3.9.2 on Debian Bullseye operating system.
import httpx from selectolax.parser import HTMLParserheaders={'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 RuxitSynthetic/1.0 v8809747757102018443 t8093092299234304605 ath2653ab72 altpriv cvcv=2 smf=0'}
client=httpx.Client()
sciencealert=client.get('https://www.sciencealert.com/',headers=headers).text
page=HTMLParser(sciencealert)for getloop in page.css('div.titletext > a'):
links=getloop.attributes['href']with open('sciencealert.txt',mode='a',encoding='UTF-8') as sa: sa.write('https://www.sciencealert.com/'+links+'\n') sa.close()