La imagen de fondo de la portada es una imagen de libre uso tomada de Pixabay y editada por @abdulmath con Inkscape
Un modelo de multiprocesador es un modelo de computación paralela que se basa en el modelo de computación RAM; es decir, generaliza la RAM.
¿Cómo se hace eso?
Resulta que la generalización puede hacerse de tres maneras esencialmente diferentes, lo que da lugar a tres modelos de multiprocesador diferentes. Cada uno de los tres modelos tiene un cierto número de unidades de procesamiento, pero los modelos difieren en la organización de sus memorias y en la forma en que las unidades de procesamiento acceden a las memorias.
Los modelos se denominan:
- Máquina de acceso aleatorio paralelo (PRAM),
- Máquina de Memoria Local (LMM), y
- Máquina de Memoria Modular (MMM).

Imagen de Pixabay
La Máquina de Acceso Aleatorio Paralela, en el modelo PRAM, tiene p unidades de procesamiento que están conectadas a una memoria compartida común no limitada, como podemos apreciar en el modelo presentado en la figura siguiente.
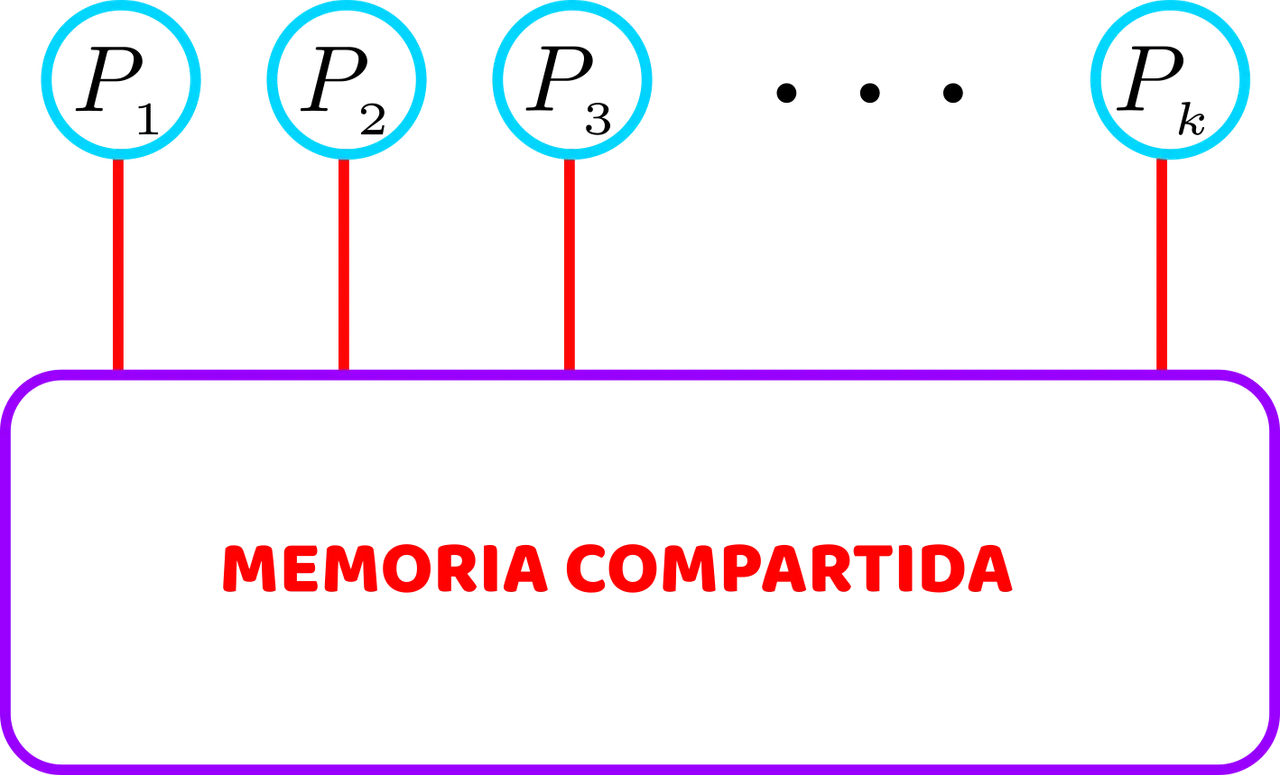
El modelo PRAM de computación paralela: p unidades de procesamiento comparten una memoria ilimitada. Cada unidad de procesamiento puede acceder en un solo paso a cualquier ubicación de memoria. Elaborada con Inkscape, por @abdulmath.
Cada unidad de procesamiento puede, en un paso, acceder a cualquier ubicación (palabra) de la memoria compartida emitiendo una petición de memoria directamente a la memoria compartida.
El modelo PRAM de computación paralela está idealizado en varios aspectos. En primer lugar, no hay límite en el número p de unidades de procesamiento, excepto que p es finito. Además, también es idealista la suposición de que una unidad de procesamiento puede acceder a cualquier ubicación de la memoria compartida en un solo paso. Por último, para las palabras de la memoria compartida sólo se supone que tienen el mismo tamaño; de lo contrario, pueden tener un tamaño finito arbitrario.
Nótese que en este modelo no existe una red de interconexión para transferir las peticiones de memoria y los datos de ida y vuelta entre las unidades de procesamiento y la memoria compartida.
Sin embargo, la suposición de que cualquier unidad de procesamiento puede acceder a cualquier ubicación de memoria en un solo paso no es realista. Para ver por qué, supongamos que las unidades de procesamiento Pi y Pj emiten simultáneamente instrucciones Ii é Ij en las que ambas instrucciones pretenden acceder (para leer o escribir) a la misma posición de memoria L, tal como lo podemos apreciar en lel siguiente modelo de la figura anexa.
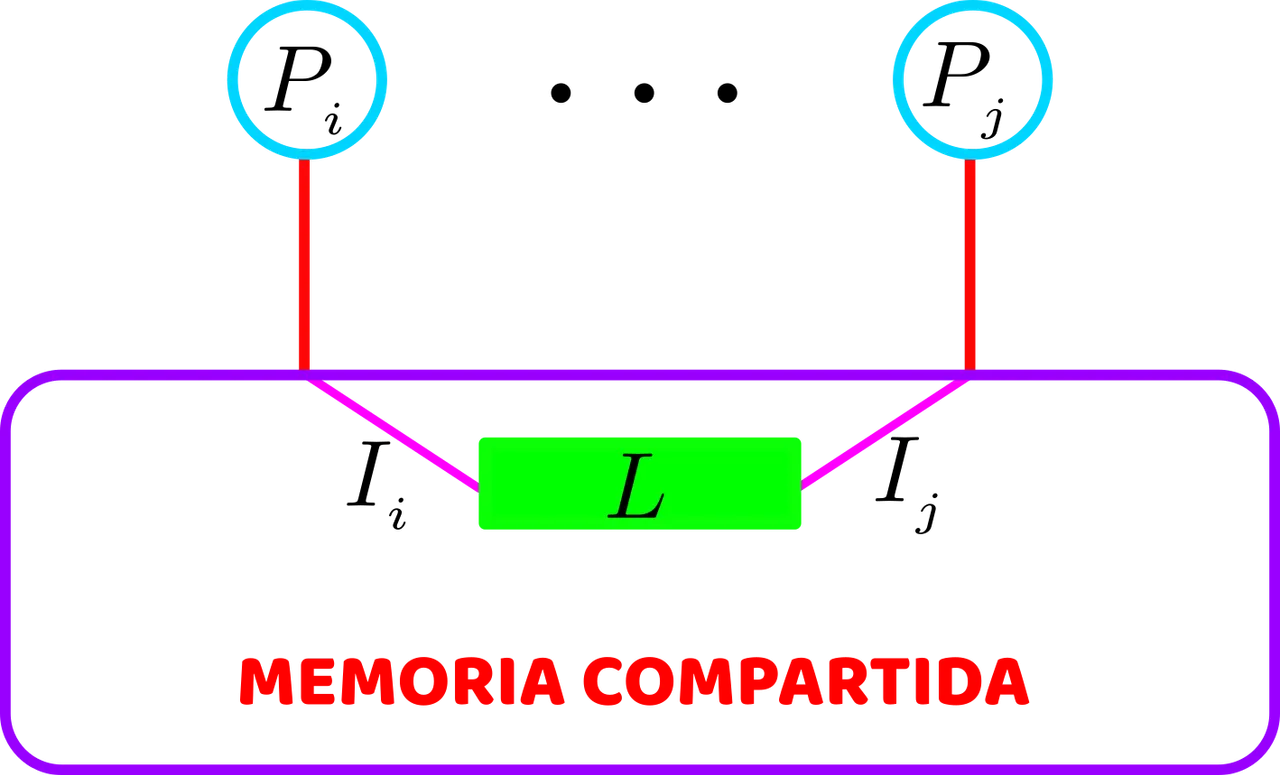
Peligros del acceso simultáneo a un lugar. Dos unidades de procesamiento emiten simultáneamente instrucciones, cada una de las cuales necesita acceder a la misma ubicación L. Elaborada con Inkscape, por @abdulmath.
Por lo tanto, es razonable asumir que, eventualmente, los accesos reales de Ii é Ij a L son de alguna manera, sobre la marcha serializados (secuencializados) por el hardware para que Ii é Ij accedan físicamente a L uno tras otro.
¿Esta serialización implícita neutraliza todos los riesgos de acceso simultáneo a la misma ubicación?
Lamentablemente, no. La razón es que el orden de los accesos físicos de Ii é Ij a L es impredecible: después de la serialización, no podemos saber si Ii accederá físicamente a L antes o después de Ij.
Las cuestiones anteriores han llevado a los investigadores a definir diversas variantes de PRAM que difieren en
- qué tipo de accesos simultáneos a la misma ubicación se permiten; y
- el modo en que se evita la imprevisibilidad al acceder simultáneamente a la misma ubicación.
Las variaciones se denominan
- PRAM exclusiva de lectura y escritura (EREW-PRAM),
- PRAM de lectura exclusiva y escritura concurrente (CREW-PRAM), y
- PRAM de lectura y escritura simultánea (CRCW-PRAM).

Imagen de Pixabay
El modelo LMM tiene p unidades de procesamiento, cada una con su propia memoria local, dicho modelo se puede apreciar en la siguiente figura.
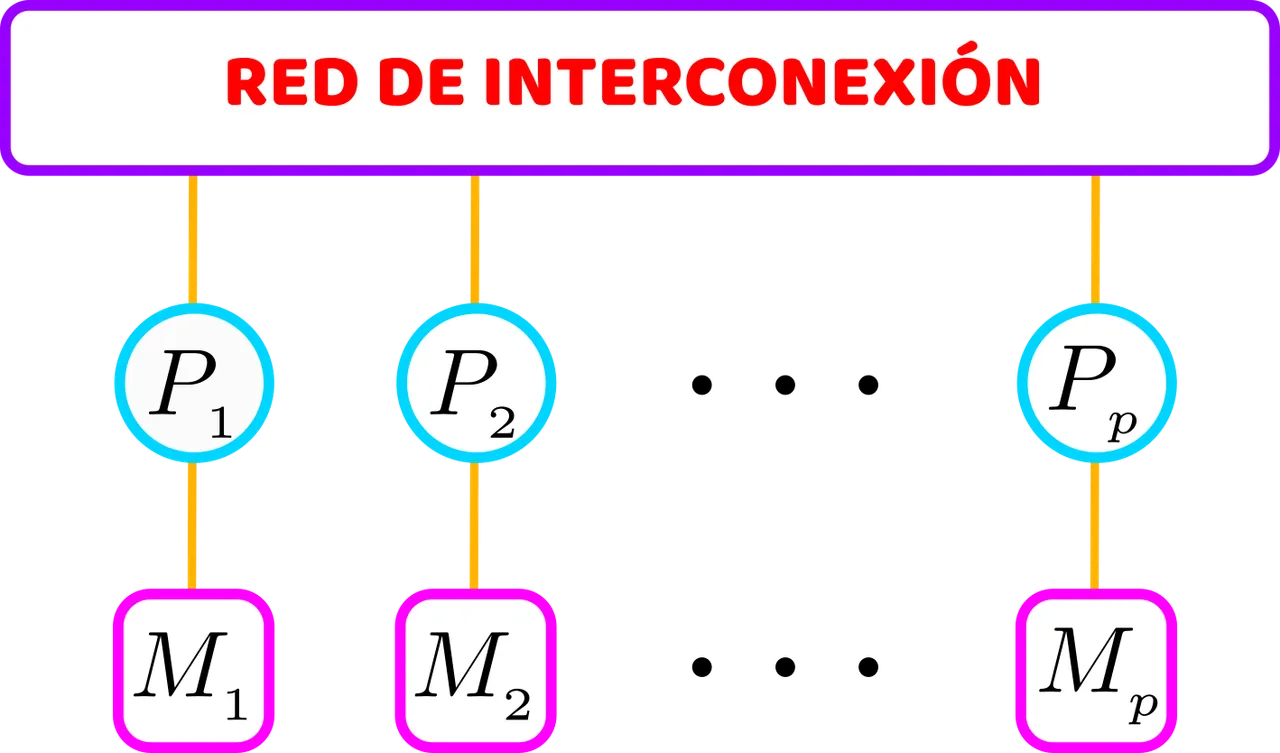
El modelo LMM de computación paralela tiene p unidades de procesamiento, cada una con su memoria local. Cada unidad de procesamiento accede directamente a su memoria local y puede acceder a la memoria local de otras unidades de procesamiento a través de la red de interconexión. Elaborada con Inkscape, por @abdulmath.
Las unidades de procesamiento están conectadas a una red de interconexión común. Cada unidad de procesamiento de unidad de procesamiento puede acceder directamente a su propia memoria local. En cambio, puede acceder a una memoria no local (es decir, la memoria local de otra unidad de procesamiento) sólo enviando una solicitud de memoria a través de la red de interconexión.
Se supone que todas las operaciones locales, incluido el acceso a la memoria local requieren un tiempo unitario. En cambio, el tiempo necesario para acceder a una memoria no local depende de
- la capacidad de la red de interconexión y
- el patrón de accesos a la memoria no local coincidentes de otras unidades de procesamiento, ya que los accesos pueden congestionar la red de interconexión.
El modelo MMM consta de p unidades de procesamiento y m módulos de memoria a los que puede acceder cualquier unidad de procesamiento a través de una red de interconexión común. No hay memorias locales para las unidades de procesamiento. Una unidad de procesamiento puede acceder al módulo de memoria enviando una solicitud de memoria a través de la red de interconexión. Dicho modelo lo podemos ver descrito en la siguiente figura.
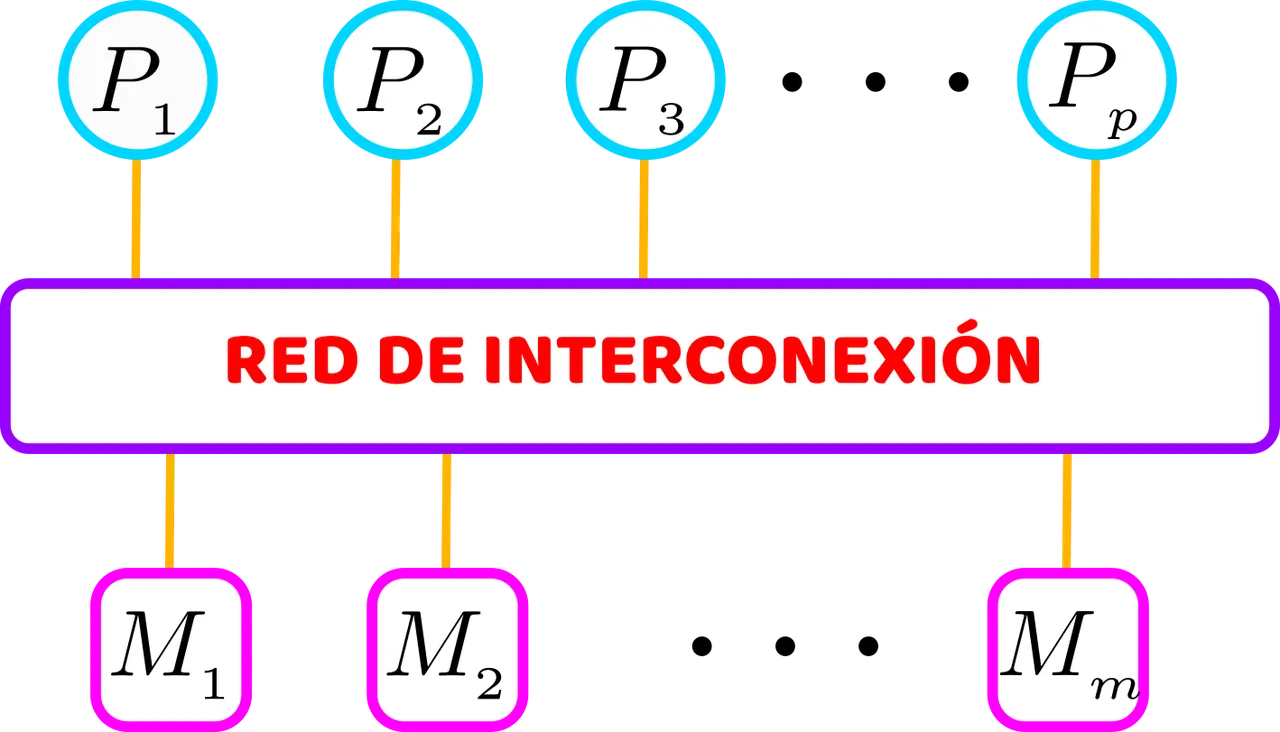
El modelo MMM de computación paralela tiene p unidades de procesamiento y m módulos de memoria. Cada unidad de procesamiento puede acceder a cualquier módulo de memoria a través de la red de interconexión. No hay memorias locales para las unidades de procesamiento. Elaborada con Inkscape, por @abdulmath.
Se supone que las unidades de procesamiento y los módulos de memoria están dispuestos de tal manera que --cuando no hay accesos coincidentes-- el tiempo para que cualquier unidad de procesamiento acceda a cualquier módulo de memoria es aproximadamente uniforme. Sin embargo, cuando hay accesos coincidentes, el tiempo de acceso depende de
- la capacidad de la red de interconexión y
- de la red de interconexión y del patrón de accesos coincidentes a la memoria.
Hemos visto que tanto el modelo LMM como el modelo MMM utilizan explícitamente redes de interconexión para transmitir las peticiones de memoria a las memorias no locales. Es por ello indispensable conocer el papel de una red de interconexión en un modelo multiprocesador y su impacto en la complejidad temporal paralela de los algoritmos paralelos.
Imagen de Pixabay
Si quedastes fascinado con este apasionante tema de la computación y programación en paralelo, no te pierdas la próxima publicación sobre este tema, si deseas ampliar más te invito a leer las siguientes referencias:
- Atallah, M., Blanton, M. (eds.): Algorithms and Theory of Computation Handbook, Chapman and Hall, Boca Raton (2010).
- Chandra, R., Menon, R., Dagum, L., Kohr, D., Maydan, D., McDonald, J.: Parallel Programming in OpenMP. Morgan Kaufmann, Burlington (2000).
- Foster, I.: Designing and Building Parallel Programs: Concepts and Tools for Parallel Software Engineering. Addison-Wesley Longman Publishing Co., Inc, Boston (1995).

