Quizz sur "Eventually consistent"
Parmi les 3 propriétés CAP, il faut absolument garantir la tolérance aux partitions réseau dans un système distribué à l'échelle mondiale.
Disponibilité VS Consistance (cas d'exemple):
- Réseau social de microblogging: Disponibilité
- Moteur de recherche sur le web: Disponibilité
- Site de commerce en ligne:
- recherche de produits dispo -> Disponibilité,
- commande -> Consistance (stock, banque, …)
- Banque en ligne: Consistance
- Crypto-monnaie: Consistance
Mécanismes pour obtenir la consistance causale: Lamport clocks
Apport de connaissances
Types de mémoire de stockage:
- Mémoire virtuellement partagée
- Système de fichier distribué
- Stockage matériel:
- RAID
- NAS
- SAN
- Base de données répartie
Problème central:
- Théorème CAP
- On peut pas avoir en même temps Consistance, disponibilité et résistance aux partitions réseaux
Catégories:
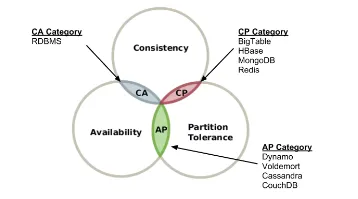
Réplication:
- Ressources:
- Options de gestion
- Lecture:
- Serveur primaire
- N'importe quel serveur
- Quorum
- Écriture:
- Primaire
- Sur tous
- Mise à jour atomique
- Sur tous les disponibles
- Sur un quorum
- Propagation lente
- Stratégies de réplication:
- Lit d'un/écrit sur tous: Sérialisation & pas de concurrence
- Lit d'un/écrit sur tous les disponibles: Plus de sérialisation si panne
- Lit d'un quorum/écrit sur un quorum: Bon compromis
- Lit d'un/ propagation lente:
- Haute disponibilité
- Si probabilité élevée de pannes: Vecteurs d'estampilles pour garantir la causalité
- Lecture:
- Options avec migration:
- Possibilités lecture/écriture: Accès distant, migration et réplication
- Stratégies:
- Serveur distant: Accès distant en lecture et en écriture
- Serveur dynamique: Migration en lecture et en écriture
- Lecture réplication/écriture migration: Choix populaire & sémantique claire
- Consistance forte:
- Lecture réplication/écriture réplication
- Consistance forte difficile
- Possibilité d'utiliser la validation à deux phases
- Options de gestion
- Services:
- État:
- Modélisation avec machine à états
- Indépendance au temps
- Tolérance à N pannes
- Primaire/secours:
- Principe:
- Communication avec un serveur primaire
- Secours: prend le relais en cas de panne
- Pro: Simple & performant
- Cons:
- Que faire si primaire donne un mauvais résultat
- Des requêtes peuvent être perdues
- Nécessités:
- 1 seul primaire à un instant t
- 1 seul primaire pour chaque client
- Interruptions bornées de services
- Requêtes traitées seulement sur le primaire (lecture)
- Battements de cœur: Pacemaker, heartbeat, …
Consistance:
- Principe:
- État:
- N'a de sens que relativement à un modèle
- Accès généraux lectures/écritures:
- Consistance atomique:
- Toutes opérations apparaissent atomiques & séquentielles
- Ordre correspond au temps-réel: même sur tous processeurs
- Très coûteux
- Consistance séquentielle:
- Relâche de la contrainte temps-réel
- Écriture = multicast
- Consistance causale:
- Relâche de la contrainte ordre identique sur tous les processeurs
- Garanti seulement la causalité
- Écriture = envoi
- Lecture = réception
- Consistance de processeur:
- Seules les écritures venant d'un même processeur doivent être vues dans le même ordre
- Implémentation facile
- Consistance de mémoire lente:
- Seules les écriture par le même processeur à une même adresse doivent être vues dans l'ordre
- Mise à jour locale visible immédiatement
- Propagation lente
- Consistance atomique:
- Accès spécifiques (de synchronisation):
- Protection par sémaphore: Exclusion mutuelle & demande l'intervention du programmeur
- Consistance faible: barrière de synchronisation
- Consistance de relâchement: Accès exclusif des sections critiques: acquisition et relâchement
- Consistance d'entrée: Chaque variable partagée est associée à une variable de synchronisation
Exposés en binôme
NAS & RAID
RAID est un ensemble de méthodes pour organiser les disques de manière intelligente:
- RAID 0: Agrégation 2+ disques:
- Capacité: plus petit des 2+ disques
- Fiabilité: faible (perte si 1 disque tombe)
- Perte: aucune
- RAID 1: Réplication 2+ disques
- Capacité: plus petit des disques
- Fiabilité: excellente (perte max de N-1 disques)
- RAID 5: Parité 3+ disques
- Capacité: plus petit des disques
- Fiabilité: perte max de 1 disque
- Plusieurs façons de répartir la parité entre les disques
- RAID 6: N fois la redondance (RAID 5 évolué)
- Capacité: plus petit des disques
- Fiabilité: perte max de N disque
- RAID 10: RAID 1 et RAID 0 (4+ disques)
- Réplication et redondance
- On réplique et on augmente la bande passante
Nb1 : Mixer les disques afin de pallier aux probabilités de panne
Nb2 : RAID possible en hardware ou en software, on peut les coupler
HDFS
Système de fichier distribué utilisé par Hadoop Apache
- Pro:
- Système distribué sur plusieurs milliers de serveurs :
- Evite la congestion du réseau
- Portabilité
- Surtout utilisé pour les grands ensembles de données
- Modèle de cohérence simple
- Cons:
- Pas de bénéfices pour des petits volumes de données
- Système séparé en NameNodes et en DataNodes, nodes dont la criticité n'est pas la même au sein du système
Dynamo
Ensemble de techniques qui forme un ensemble de stockage structuré avec des groupes clés-valeurs:
- Propriétés de base de données
- Tables de hachage distribué
Et ce en se reposant sur divers principes et techniques.
- Principes:
- Évolutivité incrémentielle
- Symétrie
- Décentralisation
- Hétérogénéité
- Techniques:
- Consistant hashing
- Vector clock
- Stoppy quorum
- Merckel tree
- Gossip-based
Systèmes pair-à-pair
Le pair-à-pair (en anglais peer-to-peer), souvent abrégé "P2P" est un modèle d'échange en réseau où chaque entité est à la fois client et serveur, contrairement au modèle client-serveur traditionnel.
Les termes "pair", "nœud" et "utilisateur" sont généralement utilisés pour désigner les entités composant un tel système.
Il peut être partiellement centralisé (une partie de l'échange passe par un serveur central intermédiaire) ou totalement décentralisé (connexions entre participants sans infrastructure particulière). Il peut servir entre autres au partage de fichier, au calcul distribué ou à la communication.
- Utilisation la plus célèbre: les torrents.
- Problème: la découverte de ressources, des nœuds, etc.
- Utilisations légales et avec un réel intérêt :
- MaJ Windows Update
- Blockchain
- IPFS
- …
On revient aux sources d'internet, où les informations ne sont pas centralisées