Is it difficult to detect 3D objects in 2D images?
Now, you can do it with a cell phone, or in real-time.
This is the MediaPipe Objection released by Google AI today, a pipeline that can detect 3D objects in real-time.
Separately:
MediaPipe is an open-source cross-platform framework for building pipelines to process different models of perceived data.
Objection calculates object-oriented 3D bounding boxes in real-time on mobile devices.
It can detect objects in daily life and see the effect.
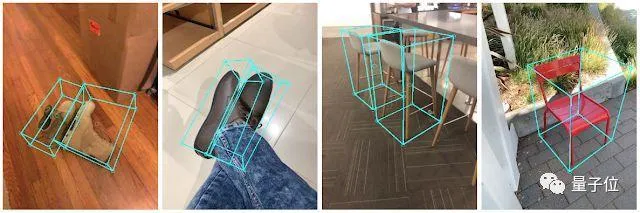
It can determine the position, orientation, and size of objects in real-time on mobile devices.

This pipeline detects an object in a 2D image and then uses a machine learning model to estimate its pose and size.
So, how does it do it?
Get 3D data in the real world
We know that 3D datasets are very limited compared to 2D.
To solve this problem, researchers at Google AI have developed new data pipelines using mobile augmented reality (AR) session data.
Currently, most smartphones now have augmented reality capabilities, capturing additional information in the process, including camera poses, sparse 3D point clouds, estimated lighting, and planes.
In order to label the ground truth data, the researchers constructed a new annotation tool and used it with AR session data to allow the annotator to quickly label the 3D bounding box of the object.
This tool uses a split-screen view to display 2D video frames, as shown below.
On the left is a covered 3D bounding box, and on the right is a view of the 3D point cloud, camera position, and detection plane.

The annotator draws a 3D bounding box in a 3D view and verifies its position by looking at the projection in the 2D video frame.
For static objects, you only need to annotate an object in a single frame and use the ground truth camera pose information from the AR session data to propagate its position to all frames.
This makes the process very efficient.
AR synthetic data generation
In order to improve the accuracy of predictions, one of the more popular methods is to "fill" real-world data through synthetic 3D data.
But this often produces very unreal data, and even requires a lot of calculation work.
Google AI has proposed a new method-AR Synthetic Data Generation.
This allows researchers to use camera poses, detected planes, and estimated lighting to generate physically possible locations and locations with lighting that match the scene.
This method produces high-quality synthetic data that, when used with real data, can improve accuracy by about 10%.

Machine learning pipeline for 3D object detection
To achieve this, the researchers built a single-stage model that predicts the pose and physical size of an object from an RGB image.
The backbone of the model has an encoder-decoder architecture based on MobileNetv2.
A multi-task learning method is also used to jointly predict the shape of the object through detection and regression.
For the shape task, predict the shape signal of the object according to the available ground truth annotations (such as segmentation); for the detection task, use the annotated bounding box and fit the Gaussian distribution to the box, centered on the box centroid, and Standard deviation proportional to the size of the box.
The detection target is to predict this distribution, and its peak represents the center position of the target.
The regression task estimates a 2D projection of the 8 vertices of the bounding box. In order to obtain the final 3D coordinates of the bounding box, a mature pose estimation algorithm (UPnP) is also used, which can recover the 3D bounding box of the object without knowing the size of the object.
With a 3D bou

nding box, the pose and size of the object can be easily calculated.
This model is also very lightweight and can run in real time on mobile devices.
Detection and tracking in MediaPipe
When the mobile device uses this model, the model may "jitter" due to the ambiguity of the 3D bounding box in each frame.
To alleviate this situation, researchers have adopted the detection + tracking framework recently released in the "2D world".
This framework reduces the need to run the network on each frame, allows for larger and more accurate models, and maintains real-time on the pipeline.
In order to further improve the efficiency of the mobile pipeline, let the model inference be run only once every few frames.

Finally, such a good project is of course open source!
Poke the portal link below and try it out ~
Portal
GitHub project address:
https://github.com/google/mediapipe/blob/master/mediapipe/docs/objectron_mobile_gpu.md
Google AI Blog:
https://ai.googleblog.com/2020/03/real-time-3d-object-detection-on-mobile.html
-Finish-
1000 account netflix
https://lnkmeup.com/6UZh
UC PUBG Mobile Free
https://lnkmeup.com/6USY
XBOX ONE Giveaway (Optimized page)
https://lnkmeup.com/6UPi
Make $5 a Day From Leaving Your Computer/Phone On
https://lnkmeup.com/6UOA