
데이터가 중복이 발생해 불필요한 데이터가 생겨서 처리할 방법을 고민 중 Distinct나 group by 를 사용하려 했다. 그리고 이김에 이 둘의 차이점을 확실하게 짚고 넘어가야 겠다고 생각했다. (어떤 걸 사용해야 더 나은지 확인하기 위해서)


DISTINCT : 유니크한 데이터(컬럼, 레코드)를 조회할 때 사용
GROUP BY : 데이터를 그룹핑해서 그 결과를 조회할 때 사용


위 쿼리는 중복을 제거 처리한다.
동일하게 결과는 나오지만 차이는 존재한다.
- 다른 기능이 동일하게 처리되는 이유?
Distinct : SELECT한 전체 row에 중복을 제거한다.
Group by : 내가 원하는 그룹별로 row들을 집계하니,
select 구문 속에 집계함수를 사용하지 않으면 중복된 값들이 집계되어 하나로 처리되어 distinct랑 같은 결과를 얻을 수 있다.
- 위 결과의 차이는?
Distinct : 단순 그룹핑 작업 수행
Group by : 그룹핑 작업 + 정렬 작업 수행
만약 “정렬”이 필요하지 않다면 부가적인 작업이 없는 DISTINCT를 사용하는 것이 더 빠르다고 볼 수 있다.


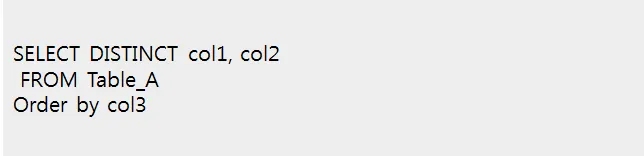
위의 쿼리를 실행하면 아래와 같은 에러 메시지가 뜬다
"ORA-01791:SELECT 식이 부적합합니다"
이는 Distinct로 인해 col3 컬럼 기준이 모호해져서 발생하는 에러이다.
동일한 col1, col2의 그룹 안에 서로 다른 col3 값이 여러 개 있어서 어떤 값을 대표로 해야될지 모름
즉, distinct를 order by 절과 같이 사용할 떄는 order by에 Select 문에서 사용한 컬럼만 쓸수 있다.

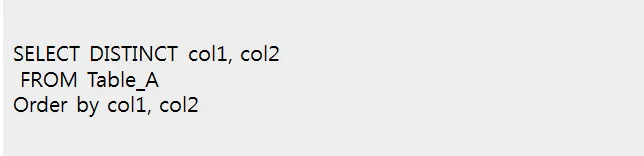

2번과 마찬가지로 Group by 와 order by가 함께 사용할 때는 제한이 있다.
SELECT 절에 있는 컬럼만이 group by, order by에 포함되어야 한다.
Group by 절의 그룹핑 기준으로 selec문의 컬럼과 집계 함수에 사용된 데이터 칼럼이 새로 만들어진다
그 후 수행되는 select절이나 order by절에서 새로 만들어진 컬럼 데이터 이외의 개별데이터를 사용하면 에러가 발생한다
즉, group by를 order by 절과 같이 사용할 떄는 order by에 Select 문에서 사용한 컬럼만 쓸수 있다.
