Continuing
my research into distributed systems I came across the concept of causality determination systems for distributed systems without a centralised clock. It is based on Vector Tree Clocks, and this is a simple diagram that gives you some idea of how it works:
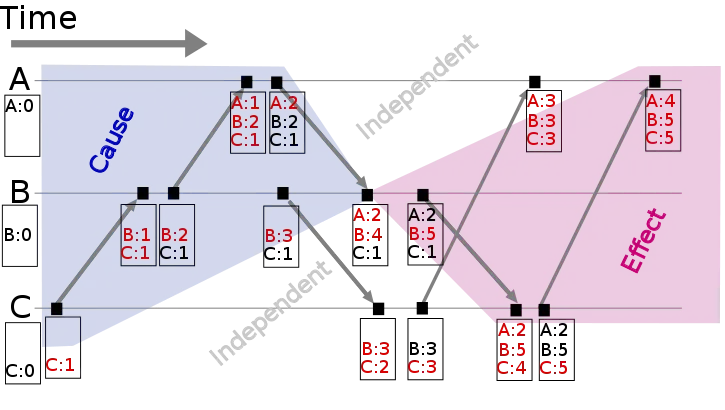
Interval Tree Clocks go a step further and allow you to track events that spawn multiple subprocesses that can converge again as well:

TL;DR:
Basically this is a way to positively determine whether an action by one actor, was before, after, or potentially concurrent with another, without having to trust a centralised clock.
This is important because for example the case of a sequence of two spends of a quantity of a cryptocurrency, if a sends 10 to b, and then b sends 10 to c, but you are d, and you heard about 10 going from b to c before you heard about it first going from a to b, when you inspect the stamps you can see the chain that a did the send before b, not by a time stamp, but by the codes in the messages, the first has a send and receive from a to b, and the second from b to c, and the stamps from b can tell you that it received the 10 before it then sent it.
Obviously, as this example shows, you would reject the data if you could not arrange its' order because it would be impossible, in the case that b and c both had zero, how could b send 10 to c if it had zero prior learning about a sending it to b?
I was all girding up to port a java version to go, and then I found this:
It's nice when you can just say 'ok, that problem is solved'. Well, mostly. I still have to write the code that actually creates events.
Maintaining lists of peers in a network
I also have found the tool for maintaining lists of nodes in the network , that implements the SWIM protocol (I may have mentioned this before). There is a go implementation of this here: https://github.com/clockworksoul/smudge and interestingly it also provides the possibility of carrying up to 256 bytes of data in the ping/ack packets, which I am considering using as the underlying transport for the Dawn Nexus messaging system, and because it is a reliable protocol operating over unreliable UDP, it will recover when IP addresses change or there is disruptions in the connection.
The Interval Tree Clocks will be the timestamps used for the database synchronisation and transaction transmissions, which will ensure that it isn't possible to fork the network by synchronised sending of differing spends on the same account (double spend attack), as well as a two tier distribution pattern with geographically localised validators that feed transactions up through a global validator set who then send out the synchronisation digests that drop any conflicting transactions between different geographical validator zones.
Thinking further about it, it is possible that Smudge could in fact become the primary transport layer instead of gRPC, which is built on HTTP/2, which is TCP based, meaning it does not cope as well with unstable network environments. gRPC is still the best choice for the interface for database querying by applications, as it is efficient and compact, and protocol buffers also for storage. I will write a packet protocol to put protocol buffers data into the SWIM protocol UDP packets, and the IPC between nodes will be more resistant to partitions in the network cutting a hop in a TCP/IP route, UDP reroutes without needing the time to negotiate a new path.
Anyway, I just wanted to share this thing - I am far from fully understanding it but I think I grasp it well enough to be able to use the logical clock stamps for messages to ensure that transactions always go into the log in the correct order, preventing the possibility of exploiting timing to attack the network, as well as making the network resilent in the face of quite large scale connectivity failures in the internet as a whole.