
机器学习中的决策树
机器学习中的决策树 (decision tree) 广泛影响了机器学习的生态,涵盖了分类和回归分析两种极为重要的机器学习工作。在分析中,决策树可以用于数字分析和视觉分析。正如名称所示,它使用了一个树状的决策模型。虽然决策树本来是用于数据挖掘 (data mining) 而推出的策略,但它不知不觉间广泛应用于机器学习,成为本文的主要焦点。
如何表示算法?
让我们考虑一个基本的例子: 使用决策树分析泰坦尼克数据(Titantic data, 对就是那个电影)来预测乘客是否能够生存。以下模型使用数据中的3个特征/属性,即性别,年龄和sibsp(配偶或儿童的数量)。
图片来自维基百科
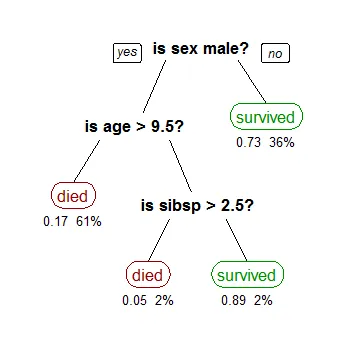
决策树被倒置,其根部位于顶部。在上边的图像中,粗体表示条件/内部节点 (condition / internal node),基于此,树分解成分支/边 (Branch / edge)。不再分裂的分支为结尾/叶 (decision / leaf),在这里,乘客是否死亡或幸存,分别以红色和绿色文字表示。
一个真正的数据分析将具有更多特征,这些特征将由更大的树中的一个分支表示出来,这个算法可以明确分辨出不同特征的重要性,特征之间的关系也可以很容易地看出来。以上树称为分类树 (classification tree),目标是将乘客分类为存活或死亡。另一种树为回归树, 它以相同的方式进行分析,只是他们预测连续的数字 (continuous values),比如房子的价格。一般来说,决策树算法被称为CART或Classification and Regression Trees.
其实AI是怎样计算 / 分类出树和支呢?让我们先了解一种常用的分割技术。
递归二进制分割 (Recursive Binary Splitting)
在此过程中,所有特征都会考虑,并使用成本函数 (cost function)测试不同的分割点 (即决定要使用性别,年龄还是sibsp进行第一层的分割)。选择最低”成本”的分割点进行拆分。
考虑从Titanic data中学到的树的例子。在第一个分割点中,所有特征 (性别,年龄和sibsp) 都会被AI考虑,并且基于该分割点将特征分成2组。我们有3个特征,所以会有3个分割的方法。现在我们将使用一个函数(function)来计算每个拆分所需的成本,并选择成本最低的分割点进行分割,在我们的例子中第一个分割点就是乘客的性别。该算法本质上是递归 (recursive) 的,因为形成的组可以使用相同的策略再进行细分。这算法也被称为贪心算法 (greedy algorithm),这使得根节点成为最佳的预测器/分类器。

分裂成本
让我们仔细看看用于分类(classification)的成本函数。
分类:G = sum(pk *(1-pk))
基尼系数 (Gini score) 评分提供了一个拆分的分数。Pk表示在进行一次的分柝后分类还有多乱 (对分类的判断进步了多少),比如说,如果在Titantic data中,我们第一个分类是年龄,在拆分后,死亡和生存的人依然是0.5 和0.5, pk 和 G 就会变得很高,AI就不会采用这个方式进行分割。
何时停止分裂?
你可能会问什么时候停止分裂呢?通常每一次的Data analysis 都会有一大堆特征,它导致大量的分裂,反过来又给了一个巨大的树。这样的树木很复杂,那么,我们需要知道什么时候停止。可惜,到目前为止,树木分支的上限还得由人手设定,非常不智能。
下星期我会用python 去做一个例子,有兴趣的请follow / upvote / resteem. Thank you very much.