Hey guys,
during my studies I had to analyze the NoSQL database Cassandra as a possible replacement for a regular relational database.
During my research I dove really deep into the architecture and the data model of Cassandra and I figured that someone may profit from my previous research, maybe for your own evaluation process of Cassandra or just personal curiosity.
I will separate this huge topic into several posts and make a little series out of it. I don't know how many parts the series will contain yet, but I will try to keep every post as cohesive and understandable as possible.
Please forgive me, as I have to introduce at least a couple of terms or concepts I won't be able to describe thoroughly in this post. But don't worry, I will be covering them in an upcoming one.
What is Cassandra?
Cassandra is a column-oriented open source NoSQL database whose data model is based on Big Table by Google and its distributed architecture on Dynamo by Amazon. It was originally developed by Facebook, later Cassandra became an Apache project and is now one of the top-level projects at Apache. Cassandra is based on the idea of a decentralized, distributed system without a single point of failure and is designed for high data throughput and high availability.
Cassandras Data Structure
I decided to begin my series with Cassandras data structure because it is a good introduction to the general ideas behind Cassandra and a good foundation for future posts regarding the Cassandra Query Language and the distributed nature of it.
I try to give you an overview how data is stored in Cassandra and show you some similarities and differences to a relational database, so let's get right to it.
Columns, Rows and Tables
The basic component in Cassandras data structure is the column, which consists classically of a key/value pair. Individual columns are combined in a row and uniquely identified by a primary key. It consists of one or more columns and the primary key, which can also consist of one or more columns. To connect individual rows describing the same entity in a logical unit, Cassandra defines tables, which are a container for similar data in row format, equivalent to relations in relational databases.

the row data structure in Cassandra
However, there is a remarkable difference to the tables in relational databases. If individual columns of a row are not used when writing to the database, Cassandra does not replace the value with zero, but the entire column is not stored. This represents a storage space optimization, so the data model of tables has similarities to a multidimensional array or a nested map.
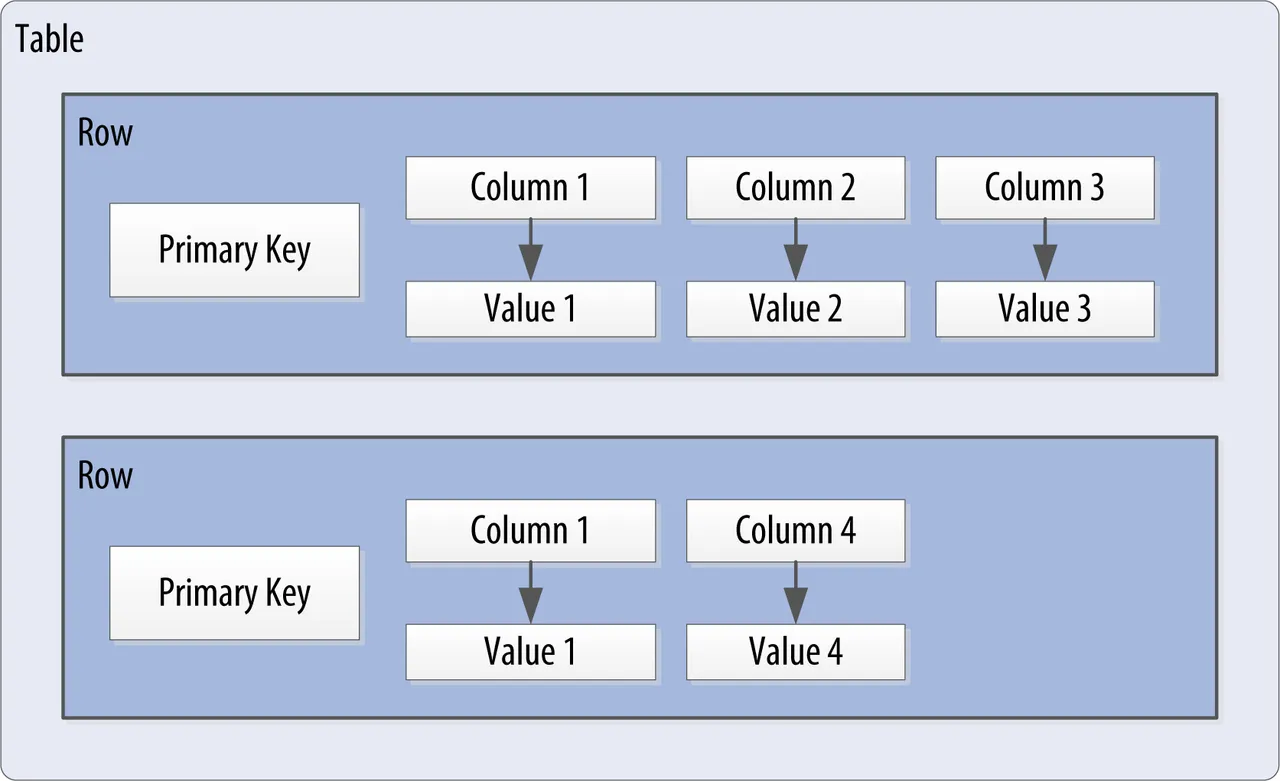
table consisting of skinny rows
Skinny and Wide Rows
Another special feature of the tables in Cassandra is the distinction between skinny and wide rows. I only described skinny rows so far, i.e. they do not have a complex primary key with clustering columns and few entries in the individual partitions, in most cases only one entry per partition.
You can imagine a partition as an isolated storage unit within Cassandra. There are typically several hundred of said partitions in a Cassandra installation. During a write or read operation the value of the primary key gets hashed. The resulting value of the hash algorithm can be assigned to a specific partition inside the Cassandra installation, as every partition is responsible for a certain range of hash values. I will dedicate a whole blog post to the underlying storage engine of Cassandra, so this little explanation has to suffice for now.
Wide rows typically have a significant number of entries per partition. These wide rows are identified by a composite key, consisting of a partition key and optional clustering keys.
table consisting of wide rows
When using wide rows you have to pay attention to the defined limit of two billion entries in a partition, which can happen quite fast when storing measured values of a sensor, because after reaching the limit no more values can be stored in this partition.
The partition key can consist of one or more columns, just like the primary key. Therefore, in order to stay with the example of the sensor data, it makes sense to select the partition key according to several criteria. Instead of simply partitioning according to for example a sensor_id, which depending on the number of incoming measurement data would sooner or later inevitably exceed the limit of 2 billion entries per partition, you can combine the partition key with the date of the measurement. If you combine the sensor_id with the date of the measurement the data is written to another partition on a daily basis. Of course you can make this coarser or grainer as you wish (hourly, daily, weekly, monthly).
The clustering columns are needed to sort data within a partition. Primary keys are also partition keys without additional clustering columns.
Several tables are collected in to a keypsace, which is the exact equivalent of a database in relational databases.
Summary
The basic data structures are summarized,
- The column, consisting of key/value pairs,
- The row, which is a container for contiguous columns, identified by a primary key,
- the table, which is a container for rows and
- the keyspace, which is a container for tables.
I hope I was able to give you a rough overview of the data structure Cassandra uses. The next post in this series will be about the Cassandra Query Language (CQL), in which I will give you some more concrete examples how the data structure affects the data manipulation.
Cheers,
Leon
Posted from my blog with SteemPress : https://craftcodecrew.com/a-deep-dive-into-apache-cassandra-part-1-data-structure/