Now that we have installed all the things that we need to start using Node.js, it’s time to write a
small program to investigate what Node is, what its peculiarities and advantages over other
platforms are, and how to use it best to develop applications.
Hello world
The basic hello world application in Node.js is something like this:
console.log('Hello world');
It’s not much. It’s just a JavaScript instruction. But if we write that line inside a file named
index.js, we can run it from the command line. We can create a new file called index.js, and
inside it we write the previous statement. We save it and we type this in the same folder:,
> node index.js
And what you obtain is the “Hello world” string in the terminal. Not so interesting. Let’s try
something more useful.
In a few lines of code, we can create the HTTP version of the hello world:
const http = require('http')
const server = http.createServer((request, response) => {
response.writeHead(200, {'Content-Type': 'text/plain'})
response.end("Hello World")
})
server.listen(8000)
This is a basic web server that responds “Hello World” to any incoming request. What it does is
require from an external library the http module (we will talk about modules in the next
chapter), create a server using the createServer function, and start the server on the port
The incoming requests are managed by the callback of the createServer function. The
callback receives the request and response objects and writes the header (status code and
content type) and the string Hello World on the response object to send it to the client.
We can run this mini HTTP server from the command line. Just save the preceding code inside
a file named server.js and execute it from the command line like we did in the previous example:
> node server.js
The server starts. We can prove it by opening a browser and going to http://localhost:8000 to
obtain a white page with Hello World on it.

Figure 5: Hello World in the browser
Apart from the simplicity, the interesting part that emerges from the previous code is the
asynchronicity. The first time the code is executed, the callback is just registered and not
executed. The program runs from top to bottom and waits for incoming requests. The callback is
executed every time a request arrives from the clients.
This is the nature of Node.js. Node.js is an event-driven, single-thread, non-blocking I/O
platform for writing applications.
What does that mean?
Event driven
In the previous example, the callback function is executed when an event is received from the
server (a client asks for a resource). This means that the application flow is determined by
external actions and it waits for incoming requests. In general events, when something
happens, it executes the code responsible for managing that event, and in the meantime it just
waits, leaving the CPU free for other tasks.
Single thread
Node.js is single thread; all your applications run on a single thread and it never spawns on
other threads. From a developer point of view, this is a great simplification. Developers don’t
need to deal with concurrency, cross-thread operations, variable locking, and so on. Developers
are assured that a piece of code is executed at most by one single thread.
But the obvious question to be asked is: how can Node be a highly scalable platform if it runs on
a single thread?
The answer is in the non-blocking I/O.
Non-blocking I/O
The idea that lets Node.js applications scale to big numbers is that every I/O request doesn’t
block the execution of an application. In other words, every time the application accesses an
external resource, for example, to read a file, it doesn’t wait for the file to be completely read. It
registers a callback that will be executed when the file is read and in the meantime leaves the
execution thread for other tasks.
This is the reason why a single thread is sufficient to scale: the application flow is never blocked
by I/O operations. Every time an I/O happens, a callback is registered on a queue and executed
when the I/O is completed.
The event loop
At the heart of the idea of non-blocking I/O is the event loop. Consider the previous example of
a simple web server. What happens when a request arrives before the previous one was
served? Remember that Node.js is single thread, so it cannot open a new thread and start to
execute the code of the two requests in parallel. It has to wait, or better yet, it puts the event
request in a queue and as soon as the previous request is completed it dequeues the next one
(whatever it is).
Actually, the task of the Node engine is to get an event from the queue, execute it as soon as
possible, and get another task. Every task that requires an external resource is asynchronous,
which means that Node puts the callback function on the event queue.
Consider another example, a variation of the basic web server that serves a static file (an
index.html)
var http = require('http')
var fs = require('fs')
var server = http.createServer((request, response) => {
response.writeHead(200, {'Content-Type': 'text/html'});
fs.readFile('./index.html', (err, file) => {
response.end(file);
})
})
server.listen(8000)
In this case, when a request arrives to the server, a file must be read from the filesystem. The
readFile function (like all the async functions) receives a callback with two parameters that will
be called when the file is actually read.
This means that the event “the file is ready to be served” remains in a queue while the execution
continues. So, even if the file is big and needs time to be read, other requests can be served
because the I/O is non-blocking (we will see that this method of reading files is not the best
one).
When the file is ready, the callback will be extracted from the queue and the code (in this case
the function response.end(file)) will be executed

Figure 6: The Node.js event loop
The event loop is the thing that continues to evaluate the queue in search of new events to
execute.
So the fact that Node is single-thread simplifies a lot of the development, and the non-blocking
I/O resolves the performance issues.
The event loop has various implications on how we write our code. The first and most important
is that our code needs to be as fast as possible to free the engine so that other events can be
served quickly.
Consider another example. You should already be familiar with the JavaScript function
setInterval. It executes a callback function every specified number of milliseconds.
setInterval(() => console.log('function 1'), 1000)
setInterval(() => console.log('function 2'), 1000)
console.log('starting')
When we run this code, the output will be something like this:
starting
function 1
function 2
What happens inside?
The first line adds in the queue the callback that writes “function 1” to the console after one
second. The second line does the same and the writes “function 2.”
Then it writes “starting” to the console.
After about one second, “function 1” will be printed to the console, and just after “function 2” will
appear. We can be sure that function 1 will be printed before function 2 because it is declared
first, and so it appears first in the queue.
So this program continues to print the two functions to the console.
Now we can try to modify the code:
setInterval(() => console.log('function 1'), 1000)
setInterval(() => {
console.log('function 2')
while (true) { }
}, 1000)
console.log('starting')
We are simulating a piece of code that is particularly slow…infinitely slow!
What happens when we run this script? When it is its turn, function 2 will be executed and it will
never release the thread, so the program will remain blocked on the while cycle forever
This is due to the fact that Node is single-thread and if that thread is busy doing something (in
this case cycling for nothing), it never returns to the queue to extract the next event.
This is why it is very important that our code is fast, because as soon as the current block
finishes running, it can extract another task from the queue. This problem is solved quite well
with asynchronous programming
Suppose that at a certain point we need to read a big file:
var fs = require('fs')
var data = fs.readFileSync('path/to/a/big/file')
If the file is very big, it needs time to be read, and since this piece of code is synchronous, the
thread is blocked while waiting. All the data and all the other events in the queue must await the
completion of this task.
Fortunately, in Node.js all the I/O is asynchronous and instead of using the readFileSync, we
can use the async version readFile with a callback:
var fs = require('fs')
fs.readFile('path/to/a/big/file', (err, data) => {
// do something with data
})
Using the async function guarantees that the execution continues to the end, and when the file
is eventually read and the data ready, the callback will be called, passing the read data. This
doesn’t block the execution and the event loop can extract other events from the queue while
the file is being read.

The Node.js runtime environment
When we run a script using node index.js, Node loads the index.js code and after compiling
it, Node executes it from top to bottom, registering the callbacks as needed
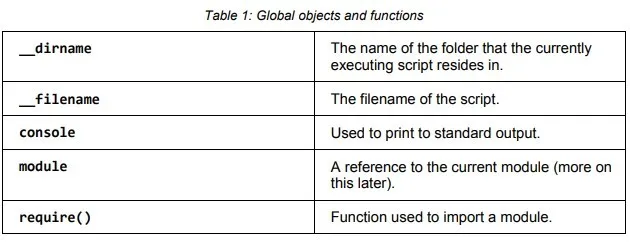
The script has access to various global objects that are useful for writing our applications. Some
of them are:
As already stated, Node comes with a REPL that is accessible by running Node from the
command line.
Inside the REPL we can execute JavaScript code and evaluate the result. It is also possible to
load external modules by calling the required function. It very useful for testing and playing with
new modules to understand how they work and how they have to be used.
The Node.js REPL supports a set of command line arguments to customize the experience:
~/$ node --help
Usage: node [options] [ -e script | script.js ] [arguments]
node debug script.js [arguments]
Options:
-v, --version print Node.js version
-e, --eval script evaluate script
-p, --print evaluate script and print result
-c, --check syntax check script without executing
-i, --interactive always enter the REPL even if stdin
does not appear to be a terminal
-r, --require module to preload (option can be repeated)
--no-deprecation silence deprecation warnings
--throw-deprecation throw an exception anytime a deprecated function is
used
--trace-deprecation show stack traces on deprecations
--trace-sync-io show stack trace when use of sync IO
is detected after the first tick
--track-heap-objects track heap object allocations for heap snapshots
--v8-options print v8 command line options
--tls-cipher-list=val use an alternative default TLS cipher list
--icu-data-dir=dir set ICU data load path to dir
(overrides NODE_ICU_DATA)
Environment variables:
NODE_PATH ':'-separated list of directories
prefixed to the module search path.
NODE_DISABLE_COLORS set to 1 to disable colors in the REPL
NODE_ICU_DATA data path for ICU (Intl object) data
NODE_REPL_HISTORY path to the persistent REPL history file
Documentation can be found at https://nodejs.org/.