[Custom Thumbnail]
All the Code that will be mentioned in this article can be found at the Github repository:
https://github.com/drifter1/compiler
under the folder "Passing information from Lexer to Parser".
Introduction
Hey it's a me again @drifter1! Today we get back to "revive" my Compiler Series, a series where we implement a complete compiler for a simple C-like language by using the C-tools Flex and Bison in lots of parts. This is the second article of the series where I try to post following utopian standards! Months ago in the "first" article I had troubles contributing using the actual "utopian.io" website. I generally don't quite understood how the whole contribution and evaluation system worked. Either way articles in this series take up quite some time meaning that I don't write articles about this topic very often. I guess it's worth noting that the previous article of the series was half a year ago...
The topics that we will cover today are:
- Fixing a bug/error from inattention
- yylval variable and YYSTYPE union
- Setting up the parser to "support" information passing
- How we pass information directly through the lexemes/tokens
- How we pass information using the Symbol Table (somewhat special case)
- Running for examples and analyzing the results (inside of the other topics)
Requirements:
Actually you need to read and understand all the topics that I covered in the series as a whole, as these articles will give you access to knowledge about:
- What Compiler Design is (mainly the steps)
- For which exact Language the Compiler is build for (Tokens and Grammar)
- How to use Flex and Bison
- How to implement a lexer and parser for the language using those tools
- What the Symbol Table is and how we implement it
- How we combine Flex and Bison together
Difficulty:
Talking about the series in general this series can be rated:
- Intermediate to Advanced
Leaving the small fixes in the beginning aside, today's topic is actually not that difficult, as extending the previous code needs particular steps and has specific cases that can "occur". This means that today's topic(s) can be rated:
- Easy (or Basic to stand with the template)
So, without further ado, let's now finally start with the actual Tutorial...
Actual Tutorial Content
Fixing an unintentional Lexer bug
In the lexer (lexer.l), I noticed that the left bracket "[" and right bracket "]" are in wrong or better said switched places in the file. This was wrong all along, from the article where we first wrote the lexer (Lexical Analysis Using Flex)!
So, this:
"]" { return LBRACK; }"[" { return RBRACK; }now changes into:
"]" { return RBRACK; }"[" { return LBRACK; }Such a bad mistake, that was surely caused by accident and inattention!
I would like to note that caught this previous error when the following rule got triggered:
array: array LBRACK ICONST RBRACK | LBRACK ICONST RBRACK ;from parser.y
Running the Compiler on example2.c, this example contained the following array declaration (where Brackets are surely needed):
double res[10];Somehow a syntax error was triggered, even though the grammar of the file is valid! So, what was wrong is that the Lexer don't returned the correct token to the parser. See how important the passing is?
yylval variable and YYSTYPE union
So, after seeing how important the communication of the Lexer and Parser is, let's now get into how we can pass even more information then the token/lexeme.
Whenever the lexer (Flex) returns a token to the parser (Bison), being called by yylex(), the parser also expects a specific value for the variable 'yylval'. This means that the parser and lexer not only have common access to 'yytext', which is the current input string, but also have a way of passing a specific value/information of specific type (or of specific types) for the current token! The yylval is of type 'YYSTYPE', which is a specific union that we have to define on our own using a %union statement.
This statement goes as following:
%union{ //types};These types can be anything: integers, characters, pointers, arrays, structs etc. If you know what unions are, you can already expect that each token can only be of one of those types, which is very logical for tokens as only one specific type has to be returned at most times. When having more things to return we can just combine all these things as a struct, something that get's us to the second way of passing, which has to do with passing information using the symbol table!
As each token can be only of one type, we have to specify which exact type each token and each rule uses (yes rules can also contain information now). This can be done very easily by including a "type definition" in the token and rule definitions. So, tokens will now be defined as:
%token <type> token_nameRules are defined similarly as:
%type <type> rule_nameSetting up the parser to "support" information passing
Let's start by defining the YYSTYPE union.
The types that the Lexer needs to be able to return to the parser are:
- character (char)
- integer (int)
- floating point numbers (float and double)
- strings (char pointer)
- identifiers as symbol table entries
This clearly shows us that the YYSTYPE union must be:
%union{ char char_val; int int_val; double double_val; char* str_val; list_t* symtab_item;}That way the new token definitions are:
%token<int_val> CHAR INT FLOAT DOUBLE IF ELSE WHILE FOR CONTINUE BREAK VOID RETURN%token<int_val> ADDOP MULOP DIVOP INCR OROP ANDOP NOTOP EQUOP RELOP%token<int_val> LPAREN RPAREN LBRACK RBRACK LBRACE RBRACE SEMI DOT COMMA ASSIGN REFER%token <symtab_item> ID%token <int_val> ICONST%token <double_val> FCONST%token <char_val> CCONST%token <str_val> STRINGI guess it's worth noting that all tokens need to have a specific type and so even Keywords and Symbols that don't actually have a value also need to be of some type, which I declare being "int_val"! I also talked about rules also having types now. This, I will leave out for semantic analysis...
So, let's now finally get into how we exactly pass this information.
Passing information "directly"
Passing information from the lexer happens before we return the token. Meaning that we have to "do something" and then return the token. This something actually hat to do with setting the value of yylval, which as we saw previously is a "self-defined" union with name YYSTYPE (even though this name never actually shows up in our Code). Being a union we have to access the specific entry of that union using the '.' modifier. That way storing the actual information inside of yylval goes as following:
yylval.entry = value;The value of the corresponding token that we want to send to the parser from the lexer is mostly "hidden" inside of the yytext variable, which stores the current input. What we have to take into account is that the 'yytext' variable is actually a "string" or to be more accurate "a pointer to the char type". This means that non-character types need to be converted into their corresponding types using some functions. The language C gives us a lot of helpful functions in this manner inside of the 'stdlib.h' library. The functions that I'm talking about are:
- atoi() -> that converts strings into integers
- atof() -> that converts strings into floating points numbers aka doubles
Knowing that we use dynamic memory allocation for the symbol table we of course already included this library in our project!
So, which exact tokens can be "put" into yylval to be accesible from the parser later on, by doing "nothing" or just converting types? Well, simple! The tokens are: ICONST, FCONST, CCONST and STRING, which are also 4 of the entries of the YYSTYPE union. This means that the following lines of the Lexer:
{ICONST} { return ICONST; }{FCONST} { return FCONST; }{CCONST} { return CCONST; }{STRING} { return STRING; }now change into:
{ICONST} { yylval.int_val = atoi(yytext); return ICONST; }{FCONST} { yylval.double_val = atof(yytext); return FCONST; }{CCONST} { yylval.char_val = yytext[0]; return CCONST; }{STRING} { yylval.str_val = malloc(yyleng * sizeof(char)); strcpy(yylval.str_val, yytext); return STRING; }I guess it's worth noting that I don't need to use strlen() to get the length of the 'yytext' string, but this can also be got from the variable 'yyleng', which always contains the length of the current input string. Being a pointer we need to allocate memory for 'str_val' before setting the actual value using strcpy().
After doing that the parser now has complete access over the value when using yylval.'entry_name'. For example let's play with the 'constant' rule of the parser:
constant: ICONST | FCONST | CCONST ;Let's print out the values of ICONST and FCONST as they occur in the test file: "example.c". This can be done very easily by including action code for that specific rule that just prints out the corresponding yylval entry! The previous line becomes:
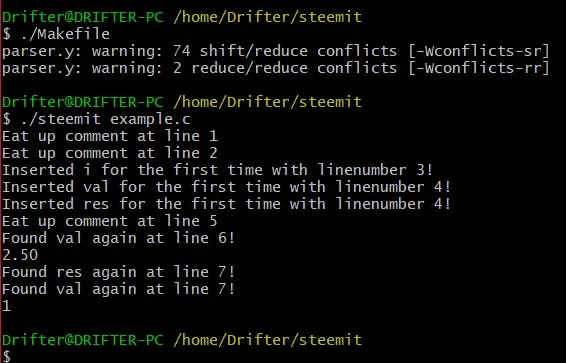
constant: ICONST {printf("%d\n", yylval.int_val);} | FCONST {printf("%.2f\n", yylval.double_val);} | CCONST ;Compiling the compiler again and running it on the example we get:
[Cygwin Screenshot]
You can see how the values '2.5' and '1' are printed out to the console!
I will revert this change of course as just printing out doesn't make so much sense in that manner. This whole article is mostly about covering the changes in the Lexer and the ways that we can transfer/pass information from the Lexer to the Parser!
Passing information through symbol table (special case)
Why put the symbol table entry as a special case? Well, there a lots and lots of ways with which we can access the symbol table entry easily from the Parser. The easiest way is similar to the previous cases, meaning that we just have to "put" the corresponding entry into the yylval. By having a lookup() function this can be done very easily inside of the lexer by just setting "yylval.symtab_item"equal to the pointer result of that function. This exact step and also the actual insertion into the symbol table, could also be done in the Parser, as 'yytext' is still accessible in the parser. But, to stay with the "motif", only the Lexer will have access to the actual input file. The parser should only work with Tokens and their values.
So, returning an identifier from the Lexer to the Parser changes now FROM:
{ID} { // insert identifier into symbol table insert(yytext, strlen(yytext), UNDEF, lineno); return ID; }INTO:
{ID} { // insert identifier into symbol table insert(yytext, strlen(yytext), UNDEF, lineno); yylval.symtab_item = lookup(yytext); return ID; }Yes, the only thing that changes is that we have to call the lookup function to get a pointer to the item that we inserted one step before, by also setting the corresponding yylval union entry "symtab_item" equal to that exact pointer.
The entry that we are passing into the parser can now be accessed in the corresponding rule that contains ID in the resulting grammar tree, which in our case can only be the "variable"-rule. Let's access the specific field of the symbol table item called st_name, that gives back the name of the Identifier (ID) that we inserted. This looks as following in Code:
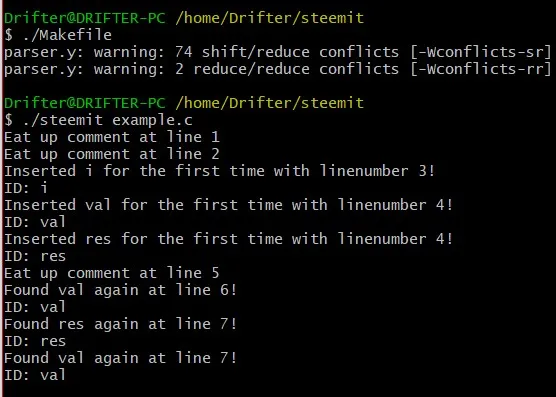
variable: ID {printf("ID: %s\n", yylval.symtab_item->st_name);}| pointer ID | ID array;Running the Compiler again we get the following result:
[Cygwin Screenshot]
You can see that the names of the Identifiers are being printed to the Console everytime this exact case of the variable rule gets triggered. Of course printing out a symbol table entry is not that useful in the compiling procedure and so let's revert this change also :P
Sum up of changes
The changes that we did today are:
- Fixed the unintentional error in the Lexer, where I swapped the places of the '[' and ']' rules
- Defined the YYSTYPE union that includes the types of information that we pass from the lexer to the parser using the yylval variable
- Added a type to the token definitions as result of the previous one
- Gave values to the yylval variable in the "needed" lexer rules by also covering the special case of the ID that is a symbol table item
So, what remains now is accessing the information from the parser (that we already covered in some exampels) in an actually useful way that makes sense in the overall compiling procedure!
References
The following helped me refresh my knowledge about these topics, including theory and examples for other grammars:
- https://ds9a.nl/lex-yacc/cvs/lex-yacc-howto.html
- https://www.epaperpress.com/lexandyacc/download/LexAndYaccTutorial.pdf
Previous parts of the series
- Introduction -> What is a compiler, what you have to know and what you will learn
- A simple C Language -> Simplified C, comparison with C, tokens, basic structure
- Lexical Analysis using Flex -> Theory, Regular Expressions, Flex, Lexer
- Symbol Table (basic structure) ->Why Symbol Tables, Basic Implementation
- Using Symbol Table in the Lexer -> Flex and Symbol Table combination
- Syntax Analysis Theory -> Syntax Analysis, grammar types and parsing
- Bison basics -> Bison tutorial actually
- Creating a grammar for our Language -> Grammar and first Parser
- Combine Flex and Bison -> lexer and parser combined
Final words | Next up on the project
And this is actually it for today's post! I hope that I explained everything as much as I needed to, meaning that you learned something out of it.
Next up on the series are:
- Finishing of the Grammar/parser by adding more rules
- Semantic analysis (predicates, more about the symbol table)
- Intermediate Code generation (Abstract Syntax Tree)
- Machine Code generation (MIPS Assembly)
I would like to note that other articles might come in-between and some might even need more than one article to complete. Also, after that we could also get into Optimizations or could even extend the Language by adding complex datatypes, even more rules etc.
See ya next time!
GitHub Account:

Keep on drifting!