How to find the percentage of similarity between two documents? A python script that finds the percentage of similarity between two documents using the cosine similarity algorithm.
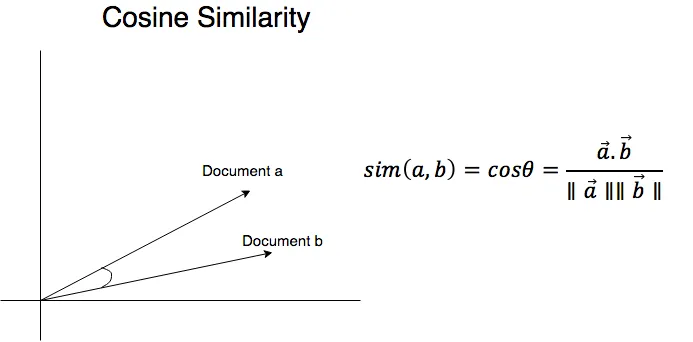
İki döküman arasındaki benzerlik yüzdesini bulmak için kullanılan kosinüs benzerliği yönteminin ayrıntılarını şu linkteki dökümandan okuyabilirsiniz. Bu yöntemi kullanarak benzerlik yüzdesini bulan bir python scripti yazdım, ben bunu anlatacağım.
Not: Dökümanlarda geçen kelimelerin hangi dökümanda kaç defa geçtiğinin hesaplamasına girmeyeceğim. Bu aşamanın yapıldığını varsayarak, sonrasını anlatacağım.
scipy modülüne ihtiyacmız olacak. Önce onu kuralım.
$ pip3 install scipy
Açıklamaları script içinde görebilirsiniz.
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
from scipy import spatial
# Dökümanda geçen kelimeler ve frekanslarından sözlük oluşturulur.
doc1 = {'social':6, 'steemit':6, 'internet':5, 'cyriptocoin':1, 'blue':3, 'red':2, 'yellow':1}
doc2 = {'social':18, 'steemit':11, 'internet':9, 'cyriptocoin':5, 'blockchain':60, 'steemdolar':40, 'upvote':20}
# İki dökümanda geçen tüm kelimelerden bir küme yapacağız. Sonra bu kümedeki kelimeler tek tek dökümanlarda ayrı ayrı kontrol edilecek. Kelime dökümanda var mı, var ise kaç tane? sorgusu yapılacak.
# Önce dökümanların kelime listesi oluşturulur. Frekans değerleri ayıklanır.
doc1_word_list = list(doc1.keys())
# OUTPUT : ['social', 'steemit', 'internet', 'cyriptocoin', 'blue', 'red', 'yellow']
doc2_word_list = list(doc2.keys())
# OUTPUT : ['social', 'steemit', 'internet', 'cyriptocoin', 'blockchain', 'steemdolar', 'upvote']
# Her iki listeyi toplayıp, küme yapıyoruz. Böylece tekrarlayan kelimeler teke düşüyor.
all_word_set = set(doc1_word_list + doc2_word_list)
# OUTPUT : {'blockchain', 'internet', 'upvote', 'steemdolar', 'cyriptocoin', 'yellow', 'social', 'blue', 'steemit', 'red'}
# Her iki döküman için vektör oluşturuluyor. Dökümanda geçen kelimelerin frekansından liste oluşturuluyor. Eğer kelime yok ise sıfır yazılıyor.
vector1 = []
vector2 = []
for v in all_word_set:
if v in doc1:
vector1.append(int(doc1[v]))
else:
vector1.append(0)
if v in doc2:
vector2.append(int(doc2[v]))
else:
vector2.append(0)
# OUTPUT vector1 : [0, 0, 6, 6, 5, 3, 0, 1, 1, 2]
# OUTPUT vector2 : [60, 40, 18, 11, 9, 0, 20, 5, 0, 0]
# Son olarak Kosinüs benzerliği yüzdesi hesaplanır.
result = 1 - spatial.distance.cosine(vector1, vector2)
print("Similarity :", (result * 100), "%")
# OUTPUT : Similarity : 26.98771675773639 %
Similarity : 26.98771675773639 %
İki döküman birbirlerine %26 oranında benziyormuş.
Dökümanları birbirlerine biraz daha benzeştirip test edelim.
doc1 = {'social':16, 'steemit':9, 'internet':10, 'cyriptocoin':8, 'blockchain':15, 'steemdolar':15, 'blue':3, 'red':2, 'yellow':1}
doc2 = {'social':18, 'steemit':11, 'internet':9, 'cyriptocoin':5, 'blockchain':60, 'steemdolar':40, 'upvote':20}
Similarity : 82.78837878218168 %
Gayet güzel. Yüzdenin artması sistemin çalıştığını gösteriyor.
Her iki dökümandaki kelimeler aynı olsun ama her kelimenin frekansları arasında 20 kat olsun.
doc1 = {'social':15, 'steemit':9, 'internet':10, 'cyriptocoin':8, 'blockchain':15, 'steemdolar':15, 'blue':3, 'red':2, 'yellow':1}
doc2 = {'social':300, 'steemit':180, 'internet':200, 'cyriptocoin':160, 'blockchain':300, 'steemdolar':300, 'blue':60, 'red':40, 'yellow':20}
Similarity : 100.0 %
Bunu beklemiyordum doğrusu! Mükemmel bir sonuç.
Son testimizde de hiçbir kelime benzerliği olmasın.
doc1 = {'social':15, 'steemit':9, 'internet':10, 'cyriptocoin':8, 'blockchain':15, 'steemdolar':15, 'blue':3, 'red':2, 'yellow':1}
doc2 = {'xxxxsocial':300, 'xxxxsteemit':180, 'xxxxinternet':200, 'xxxxcyriptocoin':160, 'xxxxblockchain':300, 'xxxxsteemdolar':300, 'xxxxblue':60, 'xxxxred':40, 'xxxxyellow':20}
Similarity : 0.0 %
Son testden de görüldüğü üzere algoritma gayet güzel çalışıyor.
http://bilgisayarkavramlari.sadievrenseker.com/2012/11/08/kosinus-benzerligi-cosine-similarity-2/
https://stackoverflow.com/a/18424933