Several days ago I read a post by @acidyo where he expressed that despite the big development differences between Hive and the legacy shitchain, as he calls Steem, there was not a big difference in the price and market value of Hive and Steem.
And to be completely honest, there shouldn't be, since both networks are practically unknown to the general public. The reality is that the price and market value of Hive, and any other cryptocurrency, is based almost exclusively on the perception that the general public has of that ecosystem. But, if the public doesn't even know it exists, then its value tends to zero.
Steem and Hive have very similar prices and market values because they both have more or less the same audience or the same fame among the general public and cryptocurrency connoisseurs. Therefore, it is not surprising that both have the same results when it comes to their markets.
But, if Hive has been investing and generating continuous development of new features and applications, why isn't Hive better known than Steem? For me the answer is quite simple, and it is that Hive has unintentionally been sabotaging itself.
I know that many will think that making large advertising campaigns or announcing all the economic benefits that people can obtain in our ecosystem is the best strategy to increase the number of HIVE users. However, these types of strategies, which can be very effective, are generally very specific and almost always ephemeral. They do not work, nor are they effective as long-term strategies to guarantee constant and continuous growth of the HIVE user base.
The best and only strategy that can guarantee continuous and constant growth is organic traffic to each and every one of the applications that work on HIVE.
Organic traffic is what drives the big platforms, and it is what should drive HIVE's natural growth. But the problem is that precisely all of these new applications that are being developed in HIVE are unintentionally reducing organic traffic to our ecosystem.
The problem lies in the nature of our ecosystem which is actually a blockchain, or simply a large database of text information. Even though we know that the owners of that information are the users who created it, those who present or show that information to the world are the applications that we are generating in the HIVE ecosystem, such as peakd, hive.blog, ecency, etc. Therefore, we have many frontends that show the information to the world.
Organic traffic is generated by search engines such as Google, Bing, Yahoo, DuckDuckGO, etc. These search engines, and especially Google, which dominates the market, determine and define the criteria that make a website or application of interest or not to the general public. One of the most important criteria that these search engines use is to avoid duplicate content in their search results at all costs. And that is precisely what is happening with Hive content that is being displayed by various applications in many different domains.
When a search engine finds duplicate content, it will only show one of the results, and the other will be discarded. This means that Hive apps are not only competing with the rest of the world that are generating content, but they are also competing hard with the other Hive apps to see which of them is chosen as the sole representative of Hive content.
In theory, Google does not penalize duplicate content, but what does happen is that said content hardly reaches the top of searches, unless that content is extremely unique. Parameters that are extremely important for search engine positioning such as backlinks, their effects are diluted because they are distributed among different domains.
Perhaps in this aspect Steem surpasses Hive, because all its content is centralized in a single domain, which is Steemit. The simplest way to analyze the effect of duplicate content is to show the performance obtained by these applications according to recognized evaluators. In this case, I am going to use the MOZ site and check the domain authority it assigns to each website.
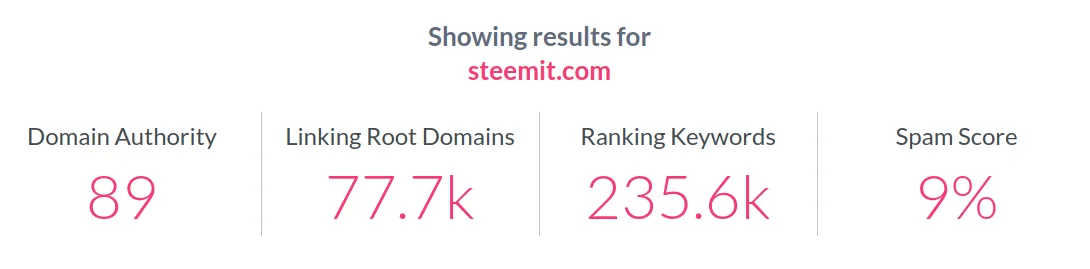
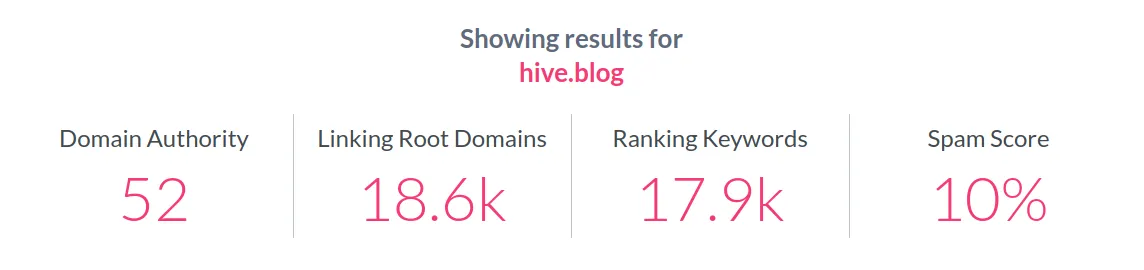
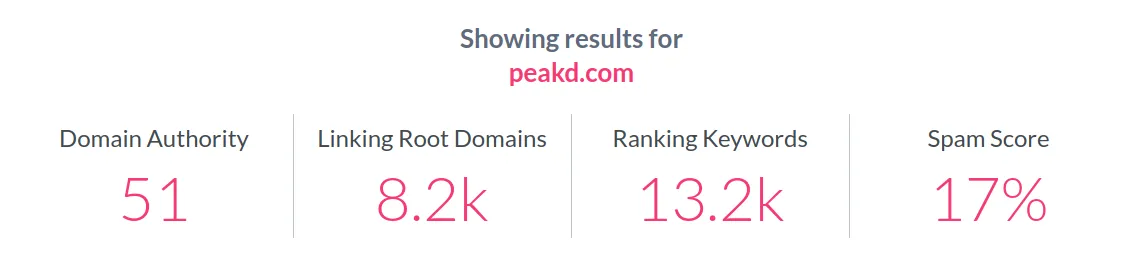
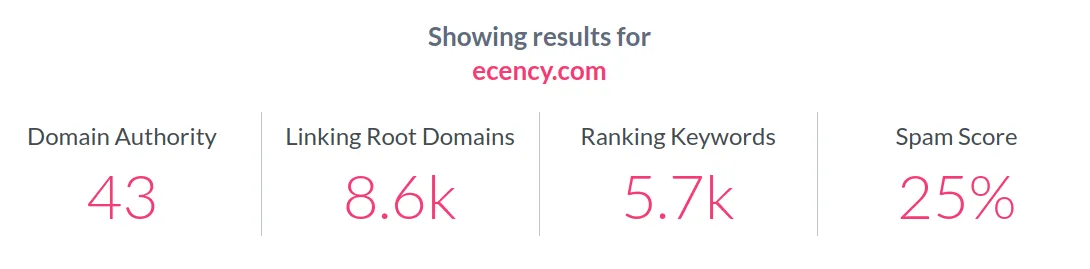
Even though these metrics are relative and in no case can they be considered absolute values of the true dominance of one website over another, there is no doubt that in all metrics Steemit far surpasses those of Hive applications.
Perhaps the most compelling metric is the number of ranking keywords, which ensure a considerable number of organic visits to the website.

What is happening with all Hive applications or frontends is what usually happens with domains that have duplicate content. Although there is no real penalty for duplicate content, there is a strong drawback, which is the fact that the authority metric is diluted among all domains. Hence, almost none of these domains go much higher than the value of 50 on a scale of 1 to 100. As new applications emerge that introduce more duplicate content, these new applications will have a lower authority, with lower metrics and a higher percentage of spam content.
What is effectively being achieved with all these applications is that none of them manages to reach their maximum potential, and therefore, they reduce visibility and exposure to the general public. In short, the opportunities to show Hive content to the public are reduced. As my Turkish friend who is a merchant would say: you always have to show the merchandise! something that Hive is definitely not doing properly.
Does that mean we shouldn't continue developing applications? No not at all. But if Hive wants to constantly increase its organic traffic, it needs to develop a strategy in line with that objective. The first thing is to avoid internal competition and minimize all the duplicate content that exists on all websites.
The simplest and most direct way I can think of that can dramatically improve the search engine rankings of all Hive applications is by creating canonical pages. According to Google Search Labs:
Canonical pages are web pages that Google considers to be the most representative of a group of duplicate or similar pages. Google selects a canonical URL to prioritize for indexing and ranking.
To indicate to search engines that a URL is canonical, you can use an HTML tag called canonical tag or rel canonical. This tag is inserted in the head section of the HTML page and has the following format: .
Canonical pages are useful when you have pages with similar or identical content, as this prevents search engines from classifying them as duplicate content.
Google can choose as the canonical URL the page that it considers most complete and useful to users, based on the factors collected during the indexing process.
Of course, there must be a tacit agreement between all developers to respect those canonical pages. It occurs to me that the platform or application through which the user has decided to use to create their post automatically becomes the canonical domain.
I am convinced that this simple change will allow the domain authority of all applications to continue improving without restrictions. This will result in greater exposure of the Hive ecosystem to the general public, which will positively impact the price and market value of HIVE.