
[Image 1]
Introduction
Hey it's a me again drifter1 and I wish you all a happy new year!
Today we continue with the Parallel Programming series around Nvidia's CUDA API to talk about Thread Hierarchy.
So, without further ado, let's dive straight into it!
GitHub Repository
Requirements - Prerequisites
- Knowledge of the Programming Language C, or even C++
- Familiarity with Parallel Computing/Programming in general
- CUDA-Capable Nvidia GPU (compute capability should not matter that much)
- CUDA Toolkit installed
- Previous Articles of the Series
CUDA Kernels
In order to execute code on the GPU, the host (CPU) has to execute something that is called a kernel. A kernel is a function without return type (void) that takes in parameters and executes on the GPU. Kernels that can be called by the host and executed on the device are marked with __global__, whilst kernels that can only be called from other devices (GPUs) or global functions are marked with __device__.
Calling a __global__ kernel function from the host has a weird syntax that contains triple angle brackets (<<< >>>). Inside of those angle brackets the programmer can define the exact thread hierarchy for the kernel's execution. In other words the number of blocks and thread per block, that are defined as grids.
So, to get more specific a __global__ kernel is executed by the host as follows:
function_name <<< /* Thread Hierarchy Definition */ >>> ( /* Parameters */ );After a kernel function call from the host (CPU) its always a good practice to execute the cudaDeviceSynchronize() function, that makes the host wait until the kernel finishes. This way the CPU will be able to access the correct results.
CUDA Thread Hierarchy
Thread and Blocks in the CUDA API can be organized into one-, two- or even three-dimensional grids of threads and thread blocks respectively. That way its easy to invoke computation across vectors, matrices or volumes of data. Its worth noting that all threads of a block are expected to reside on the same processor core and are limited to the resources of that core. In the current generation of Nvidia GPUs a thread block may contain up to 1024 threads in each dimension.
Each thread in the CUDA API is defined by dim3 structures (with x, y and z fields):
- threadIdx - thread index in the thread grid
- blockIdx - block index in the block grid
- blockDim - thread grid dimensions
- gridDim - block grid dimensions
2D grid of threads
For example let's suppose that there is only one block with a 2D grid of threads. Then is possible to use only the threadIdx.x, threadIdx.y and blockDim.x values to calculate a unique identifier for each thread. In the case of 2D matrix calculations the thread can directly compute on the indices defined by threadIdx.x and threadIdx.y or use those for a unique range of indices. In the case of a 1D vector calculation a unique identifier could be of the form:int ID = threadIdx.x + threadIdx.y * blockDim.x2D thread grid of 2D blocks
Let's suppose that we now have a 2D block grid of 2D thread grids. Now the unique identifier for each thread can no longer be specified by the values of the thread grid that its in (threadIdx, blockDim). The location of the block, or thread grid, that the thread is in (blockIdx, gridDim) has to also be taken into consideration. Calculating a unique block identifier is as simple as:
int blockId = blockIdx.x + blockIdx.y * gridDim.xUsing the blockId its now possible to define a unique identifier as follows:
int threadId = blockId * (blockDim.x * blockDim.y) + threadIdx.x + threadIdx.y * blockDim.xThe computed threadId is useful for 1D vector calculations, but 2D grids of threads are more useful in 2D Matrix calculations. Thus, let's also calculate a unique identifier for each index on a matrix. Its as simple as:
int offset = blockId * (blockDim.x * blockDim.y);
int x = offset + threadIdx.x;
int y = offset + threadIdx.y;3D thread grid of 2D blocks
To complicate things even more let's also define a 3D grid of threads organized into a 2D grid of blocks. 3D thread grids make sense to be used in volume calculations and so 3D arrays. Therefore, we shall calculate a unique identifier for each index of the 3D array. The calculation looks as follows:
int blockId = blockIdx.x + blockIdx.y * gridDim.x;
int offset = blockId * (blockDim.x * blockDim.y * blockDim.z);
int x = offset + threadIdx.x;
int y = offset + threadIdx.y;
int z = offset + threadIdx.z;int threadId = offset + threadIdx.x + threadIdx.y * blockDim.x + threadIdx.z * blockDim.x * blockDim.yCompiling CUDA Code
Before we can get into an example, we first have to talk about compilation. In order to compile cuda programs we use the NVCC compiler, which interprets .cu files as cuda source files. Such files contain both host and device functions. The syntax is quite similar to gcc, which makes nvcc very simple to use.
To compile a simple cuda program we have to write the following in the command line:
nvcc -o output_name program_name.cuExample Program
Let's write a simple cuda program that create a single block of N x N threads (2D thread grid). Each thread will print out its unique identifier and the indices for matrix computations.
In code this looks as follows:
#include <cuda.h>
#include <stdio.h>
#define N 4
// kernel function
__global__ thread_function(){
int threadId = threadIdx.x + threadIdx.y * blockDim.x;
printf("thread %2d: (%d, %d)\n", threadId, threadIdx.x, threadIdx.y);
}
int main(){
// define dimensions
dim3 threadDims;
threadDims.x = N;
threadDims.y = N;
threadDims.z = 1;
// execute kernel
thread_function<<<1, threadDims>>>();
// wait for device to finish
cudaDeviceSynchronize();
}
Compiling and executing the program we get the following console output:
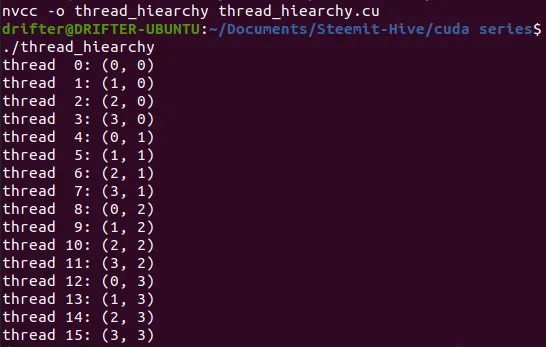
So, each of the N x N = 4 x 4 = 16 threads has a unique identifier in the closed range [0, 15].
Such a hierarchy can be used for calculations on N x N matrices of elements, making each thread compute on a single index.
Moving data from/to the device from/to the host will be covered next time!
RESOURCES:
References
Images

Previous articles about the CUDA API
- CUDA API Introduction → Installation, GPU Computing, CUDA API
Final words | Next up
And this is actually it for today's post!
Next time we will continue with Memory Management...
See ya!
Keep on drifting!