[Image 1]
Introduction
Hey it's a me again @drifter1!Today we continue with the Parallel Programming series about the OpenMP API. I highly suggest you to go read the previous articles of the series, that you can find by the end of this one. Today we will get into how parallel threads can be synchronized using Locks and Barriers!
So, without further ado, let's get straight into it!GitHub Repository
Requirements - Prerequisites
- Basic understanding of the Programming Language C, or even C++
- Familiarity with Parallel Computing/Programming in general
- Compiler
- Linux users: GCC (GNU Compiler Collection) installed
- Windows users: MinGW32/64 - To avoid unnessecary problems I suggest using a Linux VM, Cygwin or even a WSL Environment on Windows 10
- MacOS users: Install GCC using brew or use the Clang compiler
- For more Compilers & Tools check out: https://www.openmp.org//resources/openmp-compilers-tools/
- Previous Articles of the Series
Recap
A parallel region is defined using a parallel region construct:
#pragma omp parallel [clause ...]
{
/* This code runs in parallel */
}int i;
#pragma omp parallel for private(i) [clause ...]
for(i = 0; i < N; i++){
...
}#pragma omp sections [clause ...]
{
/* run in parallel by all threads of the team */
#pragma omp section
{
/* run once by one thread */
}
#pragma omp section
{
/* run once by one thread */
}
...
}#pragma omp single#pragma omp critical [[(name)] [ hint (hint-expr)]] [clause ...]
{
/* critical section code */
}#pragma omp atomic [read | write | update | capture] [hint(hint-expr)] [clause ...]
/* statement expression*/
#pragma omp task [clause ...]
{
/* code block */
}Locks In OpenMP
Previously in the series, we learned how to define critical sections and atomic operations, which make specific parts of our code run atomically (on one thread at a time). Critical section constructs use locks in order to achieve this mutual exclusion, but the actual implementation is hidden from us (abstraction). Similarly, atomic operations can mostly be translated into atomic instruction that are executed from the CPU.
Synchronization Hints
What if this pre-defined synchronization isn't enough for our needs? Well, its possible to define synchronization hints, which change the way the locks operate. Using hints its possible to specify if the critical section will be executed with low contention (few threads simultaneously) or high contention (many threads simultaneously). In the same way, it's also possible to specify if speculative techniques should be used. But, both basically affect only the speed of the synchronization.
The same synchronization hints can also be used in lock routines, that will be explained in a bit:
- omp_lock_hint_none: the default behavior
- omp_lock_hint_uncontented: low contention expected, which means that few threads are expected to perform the operation simultaneously
- omp_lock_hint_contended: high contention expected, which means that many threads are expected to perform the operation simultaneously
- omp_lock_hint_speculative: operation should be implemented using speculative techniques
- omp_lock_hint_nonspeculative: operation should not be implemented using speculative techniques
Lock Routines
So, a critical section or atomic operation doesn't suit our needs - even with hints - what do we do? Well, don't worry, OpenMP offers Runtime Library Lock Routines for the management of Locks!
So, what is a lock? A lock (or mutex in some other APIs like POSIX), is an object that is used for mutual exclusion. Only the thread with the ownership of the lock may enter and execute the code inside of a critical section. A thread requests to acquire the ownership of the lock, before entering a critical section. And the thread inside the critical section releases the lock, right after it finishes executing the code inside the critical section. The lock has to be initialized before using it and destroyed after it isn't needed anymore.
In OpenMP a general-purpose lock can be of two types:
- omp_lock_t: A simple lock that cannot be set again if it is already owned by the thread trying to set it
- omp_nest_lock_t: A nestable lock that can be set multiple times by the same thread before being unset
OpenMP offers the following routines:
- omp_init_lock(): Initialize a lock associated with the lock variablek
- omp_init_lock_with_hint(): Initialize a lock associated with the lock variable using synchronization hints
- omp_destroy_lock(): Disassociate the given lock variable from any locks
- omp_set_lock(): Acquire the ownership of a lock, and suspend execution until the lock is set
- omp_unset_lock(): Release a lock
- omp_test_lock(): Attempt to set the lock, but don't block if the lock is unavailable
Barriers In OpenMP
A barrier is a synchronization mechanism that makes all threads wait at the point of the barrier until all other threads have also reached the barrier. When no nowait clause is specified an implicit barrier is placed by OpenMP automatically at the end of each parallel region.
When the barrier has to be placed in a different section of the parallel code, explicitly, then a barrier directive has to be used.
The general format of such an directive is:
#pragma omp barrierAchieving Memory Consistency: Flush Directive
There is one more directive that's quite useful in OpenMP, and that hasn't been covered yet, which is the flush directive. Using this directive its easy to specify a synchronization point at which the implementation must provide memory consistency. Even when the variables are shared, the threads might have their own point-of-view of memory. To optimize the code, the compiler might store those variables in different registers, making each thread have its own value. Thus, the flush directive has to be used, in order to ensure that the values observed by one thread are the same values that are observed by all the other threads.
The general format of the flush directive is:
#pragam omp flush [(list)]And with that we basically covered all synchronization techniques that OpenMP offers!
Example Programs
So, after all that theoretical stuff, let's now get into some hands-on examples!
Synchronization using Locks
Let's start by implementing the code that we wrote in the Critical Sections article, about counting the zeros in a randomly-filled enormous array, using locks instead of the atomic operation.
Well, the only thing that has to change is that a lock has to be initialized before it's used inside of the parallel region, and destroyed (disassociated) after the region.
To specify the counter incrementation as atomic the lock has to be set before the count++ statement and unset after it.
In C-code:
...
/* initialize lock */
omp_lock_t lock;
omp_init_lock(&lock);
...
omp_set_lock(&lock);
count++;
omp_unset_lock(&lock);
...
/* destroy lock */
omp_destroy_lock(&lock);
...
Running this code we get the following console output:

Because the atomic operation on the CPU was replaced by locks, the performance got a little bit worse!
Synchronization using Barriers
To understand how the implicit barriers that OpenMP automatically defines and explicit barriers defined using the barrier directive operate, let's print out messages inside and outside parallel regions!
An Implicit Barrier is automatically defined at the end of each parallel region:
#pragma omp parallel
{
printf("Thread %d running inside of the parallel region\n", omp_get_thread_num());
}
printf("Main thread after implicit barrier!\n");Let's also print out multiple messages inside of the parallel region, to see the order in which the messages will be printed:
#pragma omp parallel
{
printf("Thread %d running before explicit barrier\n", omp_get_thread_num());
printf("Thread %d running after explicit barrier\n", omp_get_thread_num());
}
printf("Main thread after implicit barrier!\n");An Explicit Barrier causes threads inside the parallel region to wait until all threads have reached the barrier, before they resume the execution of the parallel code:
#pragma omp parallel
{
printf("Thread %d running before explicit barrier\n", omp_get_thread_num());
#pragma omp barrier
printf("Thread %d running after explicit barrier\n", omp_get_thread_num());
}
printf("Main thread after implicit and explicit barriers!\n");
The console output is:
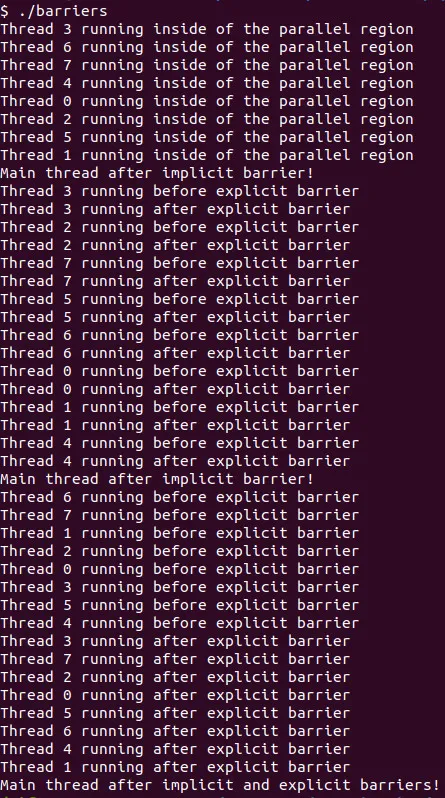
As you can see the main thread executes after the parallel region has finished (implicit barrier), and the threads inside the parallel region with the explicit barrier wait for all threads to finish printing before going further!
Memory Consistency using Flush
Let's lastly also get into an example on how the flush directive might be useful.
Consider a for loop where a specific value is incremented by one thread (main thread), and the other threads printing out the value. The main thread has to use the flush directive after each incrementation, so that the other threads print out the correct value! Let's initialize a variable x to 0, and increment it by i for 10 iterations (1 to 10) of a for loop. The final value that we expect to see is 55.
The code for that is:
int x = 0;
int i;
#pragma omp parallel num_threads(8)
{
if(omp_get_thread_num() == 0){
for(i = 1; i <= 10; i++){
x += i;
#pragma omp flush
}
}
else{
sleep(1);
printf("x : %d\n", x);
}
}
The output is:
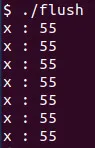
It's also worth noting that the flush statement isn't always necessary as the implementation might do the job for us! The most optimized implementation of course doesn't specify different registers for each thread's variable in this case, but it might in other cases!
RESOURCES:
References
- https://www.openmp.org/resources/refguides/
- https://computing.llnl.gov/tutorials/openMP/
- https://bisqwit.iki.fi/story/howto/openmp/
- https://nanxiao.gitbooks.io/openmp-little-book/content/
- https://www.geeksforgeeks.org/mutex-vs-semaphore/?ref=lbp
Images

Previous articles about the OpenMP API
- OpenMP API Introduction → OpenMP API, Abstraction Benefits, Fork-Join Model, General Directive Format, Compilation
- Parallel Regions in OpenMP → Parallel construct, Thread management, Basic Clauses, Example programs
- Parallel For Loops in OpenMP → Parallel For Construct, Iteration Scheduling, Additional Clauses, Example programs
- Parallel Sections in OpenMP → Parallel Sections Construct, Serial Section, Example Program
- Atomic Operations and Critical Sections → Process Synchronization Theory, Critical Section Construct, Atomic Operations, Example Program
- Tasks in OpenMP → Task Construct, Synchronization, Loops and Groups, Example Programs
Final words | Next up
And this is actually it for today's post!Next time we will get into how we call SIMD Instructions from OpenMP...and I'm not sure if there is much more to cover after that!
Nvidia's CUDA API is already on the horizon :)
See ya!

Keep on drifting!