 Image by @doze
Image by @dozeThis post is a continuation to the previous post I wrote - Exploring Hive Blogs. The intent of this post is not necessarily to explore the comments posted on the blockchain, but rather how they are stored and can be retrieved using python library Beem. A couple of weeks ago I also wrote a post - Connecting to PostgreSQL database and making queries within Python code. All of these post are part of the project I am working on. This is not a professional project. It is simply me trying to learn new coding skills by exploring Hive blockchain.
The goal of this project is to retrieve data like posts, comments, votes, etc and store then in a local PorstgreSQL database. The main reason is this is something for me to practice while learning SQL and python. But also having Hive data stored in an SQL database makes it easy implement various filters and get results fast. Also, something like this on a local computer can help searching posts more efficiently and can be used for better curation.
For some reason both posts and comments on the Hive blockchain are called 'Comments' and are stored as comment_operation. The way can differentiate posts from comments is by checking if the comment has a parent_author. If a comment doesn't have a parent author or in other wards it is an empty string, then it is a post. Otherwise it is a comment on some post or comment. The following is an example of a post:
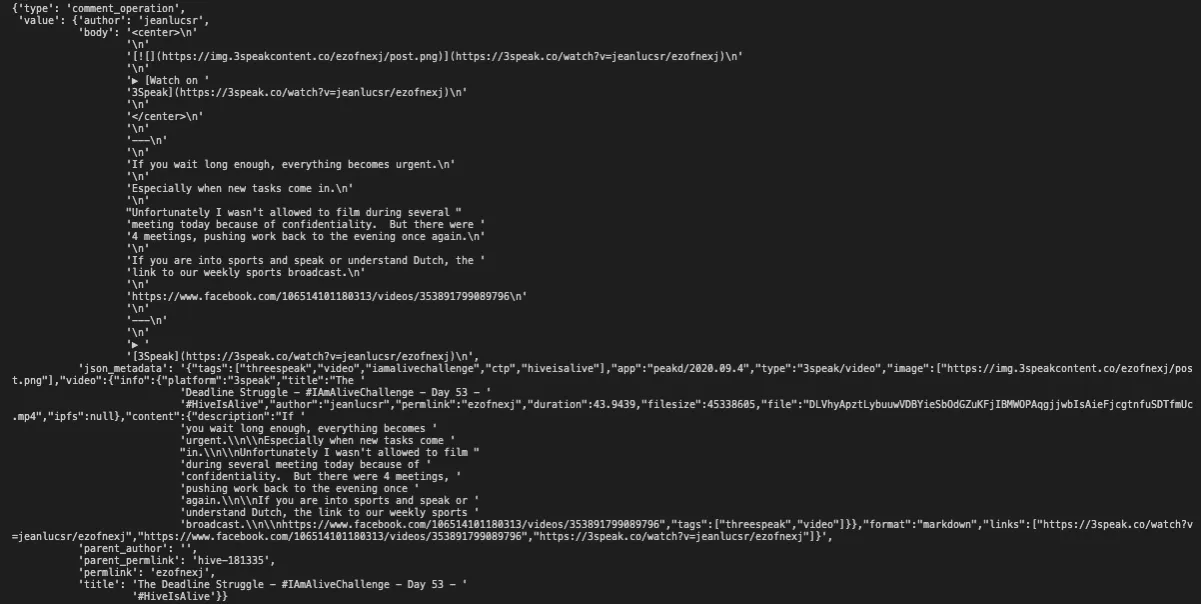
Each comment operation has two key/value pairs: type, and value. If type of the operation is comment_operation then it is a post or a comment. value has all the details about the post/comment. Among the data this operation stores are:
author- The author of the post or comment.body- The main body of the post or comment.parent_author- If this is a post then the value is '' (empty string). If it is a comment then the value is the author of the parent comment or post.parent_permlink- is a category, main tag, or the hivemind community for the post.permlink- is the ending part of the link to the post.title- is the title of the post.json_metadata- It stores additional data about the post like tags, image, app, format, links, etc.
Various front-end Apps configure json_metadata differently. The screenshot above was an example for a post, the following screenshot is an example for a comment.
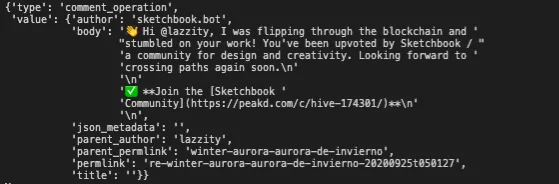
As you can see a comment has an author for parent_author. And also json_metadata and title are empty, because comments don't usually have titles and extra data that posts have.
The following is a starting point for a code I am writing for retrieving posts and comments data from the blockchain. I will be combining it with python/sql code to store them in my postgreSQL database. For now only thing this code does is goes through block and counts how many posts and comments were stored on the blockchain within the last hour.
from beem import Hive
from beem.nodelist import NodeList
from beem.instance import set_shared_blockchain_instance
from beem.blockchain import Blockchain
from beem.block import Block
from pprint import pprint
import datetime as dt
nodelist = NodeList()
nodelist.update_nodes()
nodes = nodelist.get_hive_nodes()
hive = Hive(node=nodes)
set_shared_blockchain_instance(hive)
bc = Blockchain()
current_block_number = bc.get_current_block_num()
start_block_number = current_block_number - (int(60/3) * 60 * 1 * 1)
start_time = dt.datetime.now()
def get_comments(start_block_number, current_block_number):
result = []
count = 0
count2 = 0
for block_num in range(start_block_number, current_block_number + 1):
block = dict(Block(block_num))
for transaction in block['transactions']:
for operation in transaction['operations']:
if operation['type'] == 'comment_operation':
if operation['value']['parent_author'] == '':
count += 1
print('Post: ', count)
else:
count2 += 1
print('Comment: ', count2)
result.append(count)
result.append(count2)
return result
result = get_comments(start_block_number,current_block_number)
print(result)
print(start_time)
print(dt.datetime.now())
When I run this code it takes about 4 minutes to execute. Now if I increase the time period for a day, it will run about an hour and a half. If I change it to a week, it would run for half a day. However, once data is stored in a local postgreSQL, getting the data back, sorting, etc will be much faster. That will be the next step, to store this data on a local database. If/when I am successful doing that, I hope to share that experience as well.
Posting and commenting are among the most fun participation activities on Hive!