Now I know you are thinking. "Could he make the title any longer?"
Yes. Yes, I could.
The full title should in fact be:
"How to export a production Postgres database using pg_dump and then import it into your Laravel Sail and Psql docker environment for local testing with pg_restore."
 Source
Source
As a person is developing an application you want to be able to have access to realistic data sets, edge cases happen and the closer your local data is to the data on the live site. The better and quicker you can debug any issues that might arise.
So aside from backup purposes, using a replica of the live database allows you to better test and code for edge cases and it is just better, ok. Dammit.
For the longest time I have been using pgAdmin to export the database to SQL and that is my backup. Fair enough, it works.
Now without writing any fancy import script myself, I would use HeidiSql to then import that exported file. Sure the DB is small 1mb, took about 30minutes.
I did not know better.
The DB is now at 7mb , and close to 50 000 rows and takes 2 hours to import via HeidiSql.
So I just import fresh data less often.
What if production went down and I needed to restore the database? Would that take 2 hours, eventually longer, data grows quickly and when it does with how I was doing it to the best of my knowledge, it would take almost a day to restore.
Obviously eventually you have better fail-safes etc. So for all intents and purposes just know that you should always be looking at how you can further optimize and improve your workflow when running applications.
One of those steps for me was finally taking the evening and figuring out how to speed up the process.
Turns out that the pgAdmin SQL dump is a text format, this means that Heidi (gui) and cli tools like psql will use insert to create the data on a fresh database.
the SQL INSERT command is extremely slow and has to write each row one by one. There are ways to improve it, and reading through this article on the Postgres Docs - www.postgresql.org/docs/10/populate.html. I realised that I was not intending on writing my own custom importer.
One of the biggest things I read in that article, was that COPY was faster than INSERT on large data sets. I equate this to copying a 4gb zip is quicker than copying 2000 small files of equal size.
The same idea applies, since read and writes need to be closed off each time. So if you only have one then there is less time wasted finalizing operations.
Please note a lot of how I phrase things and explain is based on my own opinion and how well I may or may not understand something. Feel free to correct me.
Now for all intents and purposes the .sql I was getting from pgAdmin is perfect. If you were writing your own importer I think the tips from that Postgres docs article would be great and you could implement them all.
Why their tip on using COPY stuck with me is, because COPY works on tables. So as such you would need to loop the .sql file and read the tables one by one and copy them over. I might attempt to write my own in the future but many tutorials keep mentioning pg_dump and pg_restore and I want fast and convenient.
Because it exports the data and writes the instructions for how to restore a database in the most efficient way;
pg_dump already implements most of the tips from the populate article above. Its counterpart pg_restore then is able to use the exported instructions to quickly restore the database in a fraction of the time it takes a normal import from say HeidiSql or the Psql utility.
My import of 2 hours before took only about a minute when I changed to using that combination. So all of this is just my experience, I guess results may vary.
Ok so apart from a example in using pg_dump and pg_restore this is also specific to how I did it using Laravel Sail with Postgres (pgsql image), which is a docker compose virtual environment.
I am also using WSL inside windows 10 with docker desktop to run everything, apart from the live data which is on a standard VPS.
You will want to log in to your production server, and if you don't have a specific location you keep backup files then make a folder for that. Say we make a "mybackups" folder in your home directory of the user you are using, then you can always dump to that location.
The cli command you will run in your terminal:
pg_dump -U userName -d databaseName -h 127.0.0.1 -Ft > /mybackups/myfilename.tar.gz
To break it down, pg_dump is the utility you are using, the -U userName flag is the name of the user that has permission to access the database, -d databaseName is the database you want to export and -h 127.0.0.1 is the hosts IP.
Adding the host IP avoids the issue where it will silently fail, and this will instruct pg_admin to prompt you for the password of the postgres user that has permissions on the database.
The last bit -Ft > /mybackups/myfilename.tar.gz sets the FORMAT -F to tar, and I also name the export file appropriately. There are multiple formats available and you should check docs to see what suits you.
Using an archive format like .tar also removes the ability to add flags such as --no-owner or --clean which we will instruct pg_restore to do instead.
Run the command and enter the password when prompted, you should then be able to find the file in the location you specified.
Copy the file from the server to your local machine, and place it in a location you prefer. I copied mine via the scp tool inside my WSL to a folder and then move it one to the root of my Laravel install and added that folder to the .gitignore so it won't be committed.
scp username@[remoteIP]:~/mybackupfolder/backupfile /destination/directory/onlocal
Use a period if you are already in the destination directory to download to the same location.
Then you can optionally move or copy the file into your laravel root or inside another folder. It is best to have it in the project because we will need to mount it as a volume for the pgsql container to use.
mv backupFile.tar.gz /laravelProject/backups/mackupFile.tar.gz
Laravel Sail uses docker-compose to orchestrate the local environment, to use files inside the containers they need to be accessible. To make them accessible you need to instruct Docker to mount the data into the container.
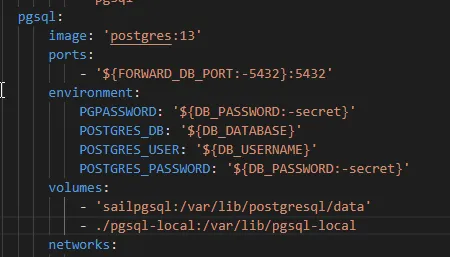
Inside your Laravel docker-compose file you can add a volume to the pgsql container instructions.
Below the,
volumes:
- 'sailpgsql:/var/lib/postgresql/data'
line add your local folder location and the destination folder on the container as a new volume:
volumes:
- 'sailpgsql:/var/lib/postgresql/data'
- ./folderWithBackups:/var/lib/folderOnContainer
Then spin up your Sail install with sail up -d and then we will get to accessing the Pgsql container.
psql and pg_restore inside the Pgsql Container with execWhen Sail is up and your site is running, run docker ps -a and copy the ID of the Pgsql container.
Now you could run pg_restore with the
--clean
flag and trust that everything is wiped but I chose to manually remove and recreate the sail database just to be sure.
First we will drop the entire database:
docker exec -it [containerID] psql -U sail -d template1 -c "drop database yourDatabaseName;"
You will find the User and Database name in your .env file for Sail , those are the credentials it uses like you normally connect. The template1 being connected to via the -d flag is a default database inside postgres because you can't drop a database you are connected to. So we connect to template1 then drop "yourDatabase".
Then we recreate the database with:
docker exec -it [containerID] psql -U sail -d template1 -c 'create database [yourDatabaseName] with owner sail;'
We create the database with the owner of sail and the same name as that in the .env file. This means the permissions everything should still be the same for Laravel to operate just fine.
pg_restoredocker exec -it [containerId] pg_restore -U sail -d yourDatabaseName --clean --no-owner -Ft /locationOnContainer/toYourFile.tar.gz
Now, you execute pg_restore on the file that is inside the folder you mounted earlier. The flags used are very similar and in many cases exactly the same as with pg_dump the only difference when using a -F format of t .tar which is an archive, the pg_dump ignores flags such as --clean and --no-owner
I use --clean to tell pg_restore to remove any old data and overwrite with the new data, because we dropped first that is a non-issue but you don't need to drop the database beforehand if you use that option.
I use --no-owner because I want my local user to own all the data in the database and not have issues with permissions.
Once you have the workflow down, or maybe wrote a shell script to run it for you , restoring a local copy or even maybe a production database should go a hell of a lot quicker.