totally not because I'm reluctant to write the whole thing in one go.

It had been some time since I started working on the idea of a MapleStory boss drop management Discord bot (which I called LutieBot), and so far, it had been a surprisingly complex and somewhat twisty journey of software development. Not to say that other software development processes are less complex or twisty, but LutieBot, which was originally planned out to just be a simple Discord bot doing a simple task, spiralled astonishingly quickly into something that is much more complicated than the initial thought. A bunch of considerations happened after the first idea of the bot happened. For example, Discord heavily encouraging the use of slash commands instead of traditional message-based commands (which happened to be a good thing, because I can scrap away my crappy home-made parser and let slash commands give me the arguments properly), the realisation that a Discord bot should properly support living in several servers and keep their data separated, and, lately, the need to let LutieBot generate its own database properly. For a number of good reasons.
When I first started making LutieBot, I started off with making the database. Since the bot's purpose in its entirety is to save, update, query and present data related to my MapleStory bossing party loot records, it makes sense to first design the database before making code to interact with it. After this step, I get a .db file, which is the empty SQLite database that I just created with DBeaver. By putting this file at the right path, it can serve as a starting database for LutieBot to work on directly without the need of writing any code to generate the database on start. The beauty of SQLite, it just works without any setup! Hence, lazy me had a massive brain moment - hey, if this works, how about I just commit the blank database into the bot's repo, and just ship it with every git clone? Less work for me!
If this is a team project with more competent members working together with me, this would likely have not happened... but, it also didn't took long for me myself to realise that this is a terrible idea, for a number of good reasons.

So, why is it awful?
In short, it sounds really wrong (and is indeed pretty wrong). Like, if you're experienced around the matters of programming and version control, you should be able to intuitively tell that this is not how it should be done. But... let's get on to the explanation.
An SQLite database is not a text-based file, and hence, to Git, it is a blob. Storing one or two blobs in a git repo isn't terrible, but it gets somewhat terrible when the blobs are updated frequently. Git cannot diff them, and hence you cannot easily check if the blobs are having the expected contents before committing and pushing it to the repo. Subsequently, Git also cannot tell you the changes of the blob between commits. This makes it quite uncomfortable to work with, as you will not be able to tell on which commit did you do that database change. Git can only tell you that "this file is last changed on commit xxx", and it isn't really that helpful.
Besides that, since it is a committed file, you cannot .gitignore it and expect Git to leave it alone while your code alters the database throughout its lifetime. Any tiny bit of changes done to the database will let Git mark it as modified, and if you aren't careful with committing, you can easily commit and push the entire database containing private data to the public repo (again, you cannot check what additions or deletions had been done to the database when committing - it is a blob). There is a pretty wacky solution around this, but I will have to revert it every time I want to push a database change to the repo. Pretty bad, eh?
The bot not being able to spawn its own database also makes testing and experimenting ideas on database changes quite troublesome. After performing work on the database, if we want the clean database back for another round of testing, the only way is to either manually replace the database file with a clean one (if we previously made a backup of the clean one), or we manually go into the database and delete everything ourselves (note: SQLite doesn't support truncate table...). If testing is immediately proceeded after a database change and I have not backed up the changed database, oops, because I will not have the new database in its clean form after that, unless I recreate it manually. I lost count of the times this happened!
Finally, one last bonus point... by committing the empty database into the repo, git reset --hard will reset the database to what the commit originally had. Obviously, it happened to me before, and that's pretty much the final straw to push me to finally do it properly.
Now, let's see how...
As with everything, there are a few options to do it, ranging from the simplest to the absurdly complex. On the leftmost corner of the spectrum, I can just let the bot run an SQL script that creates the database if it is presented with a totally empty database (the one created by the SQLite driver upon starting a connection through a connection string), and it will just work, although with a lot lesser flexibility and functionality. The main benefits are that this is a very simple approach, there isn't much logic to handle, and it is likely easy to code (at least that is how it feels like...). However, it is also a "stupider" approach. With a logic like this, the bot will not be able to verify if the database has everything it needs before proceeding to use it. Subsequently, this also means that the bot will not be able to upgrade the database by itself if required, since it can't even tell if it is running on the correct database in the first place! As much as I like simple approaches, I prefer approaches that are both simple and powerful... so, this does not look like it?
Somewhere in the middle (probably slightly left from the middle) of the spectrum, there is the option of me just using EF Core. Since I'm writing my bot in C#, it's one of the "goodies" that I can use to heavily simplify everything related to database operations, including creating and updating the database (they call it migrations). But, there's me being me... I prefer writing my own SQL and deal with my data manually! In other words, I like staying in control, and the heavy layer of abstraction that EF Core provides does not really suit my taste. But, on the other hand, I'm really quite attracted to the idea of migrations... The capability to incrementally introduce changes to the database schema used by the bot, while keeping all data and ensuring that the bot is always working on a database with expected tables and columns!
Well, I don't know what are the options available on the far right corner of the spectrum (reimplementing the whole of EF Core in the bot itself?), but, I should be able to do something that takes the nice things from both approaches above. It should not be too hard to implement something that does something similar to the idea of EF Core migrations, and I will just use it to handle the database creation and changes throughout the development process. I will be able to skip the abstractions provided by EF Core, not adding (or recreating) a lot of EF Core migrations throughout the drafting period of new features, and keep my control over the things that I like to keep manual control on. Sounds nice, so let's get to it! Although I still can't explain why I like to keep manual control over my database and my queries...

To build something, we first need to know precisely what is needed for that something. Wishes don't magically get realised if you don't even know what exactly you're wishing for! So, let's start by listing out the things we need to create and what they should be doing for this task.
First of all, we need something to provide the information of the database structure required, as well as the related information to create or update it. This is important, since being able to store the data in a suitable structure can make the task drastically easier. It will be even better if the data provider can return the data in a way so that the bot can use it directly! Maybe we can build a data provider class for this...
Then, with the data from the data provider, we will need a something to create or update the database. Its job will be pretty easy - check if the database is having a structure that fits a known version (or is blank), then run the upgrade or create script respectively if required. It can too be a class by itself, with just a minor concern of me cramming too many methods into it, since after all, its main aim is to run the scripts, validating the database is only a required step before proceeding to do its real job. Considering this, these methods can be separated out into another utility class to make it neater to code and organize. Two classes it is then!
Now that we know what we are implementing, we can proceed with the coding... Starting from the data provider, since we can't do anything without the data provider giving us the data in the first place!

Before we actually start to build the data provider, let's think a little on how the data should look like in the first place. Because, well, after all, we need to know exactly what we want before we know how to make it happen...
The data provider should be providing the database migrator (and it's utility class) the necessary information to verify the current database's schema and the scripts to create or upgrade the database. To verify the database's schema, what we need is a version number and a record of what the database should look like at that version. Then, we will be able to cross-check the database's version and its schema with what we are expecting. Storing the version is not hard, we can just use an integer to represent it, and it'll be easy to store and compare. We can of course also use a string and represent it in a format like x.y.z following the bot's version, but I find it quite unnecessary, as the database's schema might not update together with the bot every time. Besides that, since (ideally speaking) we will be making it possible for databases to migrate from one version to another regardless of the magnitude of changes required, it seems not that important to signify major or minor changes between the versions. So, an integer will do! It's definitely not because I'm lazy to make a version string comparer or something, although this thought indeed did contributed to this decision...
Getting a table's info from an SQLite database is not hard as well, we can make use of some PRAGMA statements to easily do that. For example, to get a table's information, we can do this:
PRAGMA table_info("table_name")
And it'll return this:
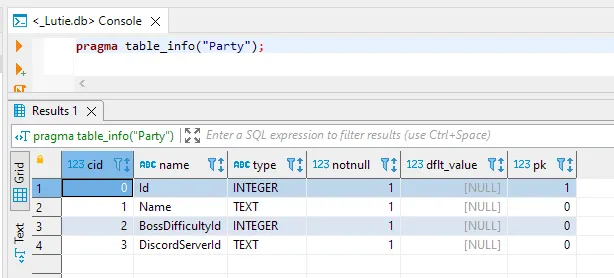
So, we now know that these are the data that we can get from the database from comparisons! Each of these rows refer to a column and its properties in the table. I don't necessarily need everything in this result to do the comparison, though, as the column ID (cid) and the default value (dflt_value) doesn't seem to be too much of importance in making sure that the database can be read as expected. Hence, only the column's name, type, primary key and nullable properties will be provided by the data provider, since this would already be enough to do the job!
Summarising the idea, it is not that complicated - the data provider should know and be able to provide a list of versions known to it, each version model should contain its own list of tables, each table should contain its own list of columns, recording each column's properties. To make it "fancy", we can just make a few record classes for VersionModel, TableModel and ColumnModel. The column's type can be a nice enum so that we don't need to do string comparisons for it, the name is going to be a string (that's unquestionable), and the nullable or primary key properties are going to be booleans. In the end, we will be getting something like this.
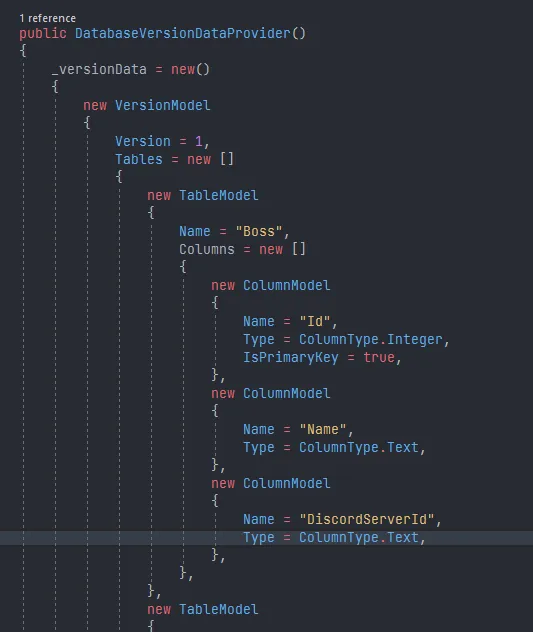
And because we are using record classes, these objects can be easily compared later on when we are checking the database. And also because they are record classes, we can give them some sensible defaults as well, reducing some code clutter!
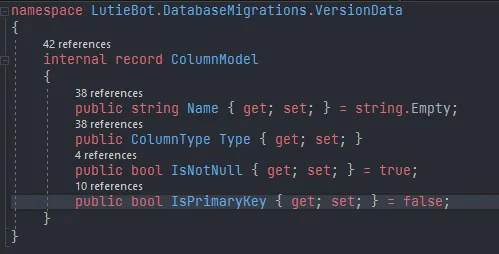
Besides the tables, we will also need the script to upgrade or create the database (because it is not that trivial and easy to make code that automatically generates SQL based on a given table schema!). Since this is the first version, we don't need any upgrade scripts. But, we will still need to prepare a creation script. Luckily, I don't need to figure them out by myself or recreate the tables in DBeaver then copying the scripts myself again, because it turns out that I can get the scripts back with an SQLite query (!):
select * from sqlite_schema;
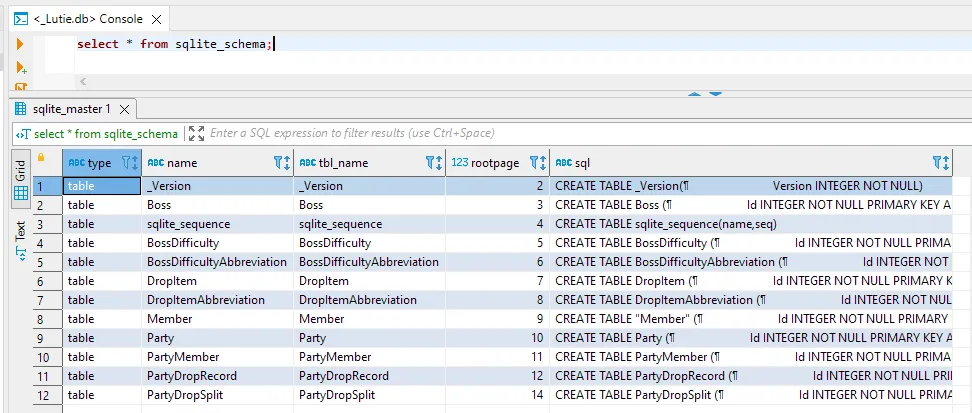
Deep dark black magic here buddy. So, off we go and copy everything into the version model again!
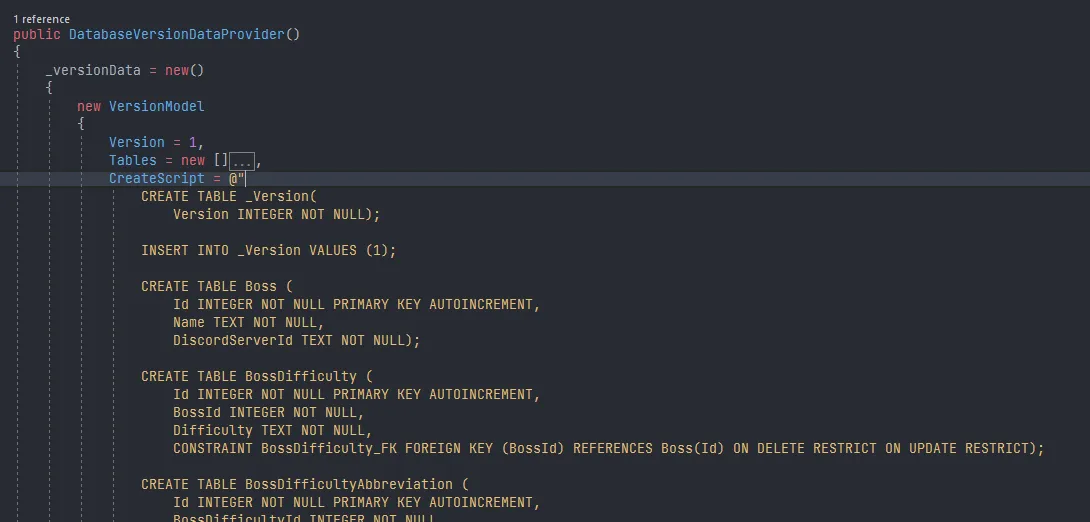
To make the data provider more useful, I can add a few more utility methods for some common tasks to be performed more easily. For example, it would be nice if there's a method to get the data for a version given a version number, get the latest version known to the bot, get the update script to update to a given version... Well, why not?
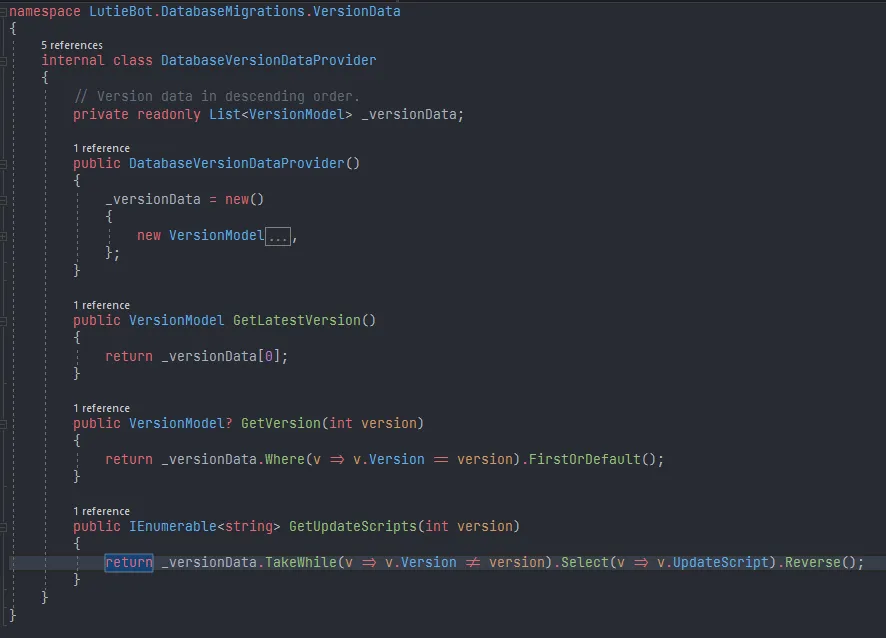
It's decently useful now! That's pretty much the work on the data provider for this "upgrade"... there's still some other stuff. Hold on for part 2, which should be coming in the future :> It will be about the code for actually verifying and upgrading/creating the database upon starting up the bot, which is, well, where the real thing happens. If you are interested, you can check the code on the GitHub repo (although it doesn't compile for now, I seem to had forgotten a file or something). It also includes the code for part 2 of the post! Hopefully the next commit will come to the repo in the visible future, xd.
That's all for now and see you!