
In this post, I want to present basic information about The HAF. I think it is a good idea to have described in one place what is The HAF, what are its components, and how they cooperate with each other, with applications, and with the HIVE network.
What does it mean HAF ?
HAF is an acronym from the HIVE Application Framework. In short, it is a software system that allows to easily write applications working on the HIVE blockchain. Such applications read information delivered by blockchain blocks and very often transform them into their specific data.
A high-level view of The HAF
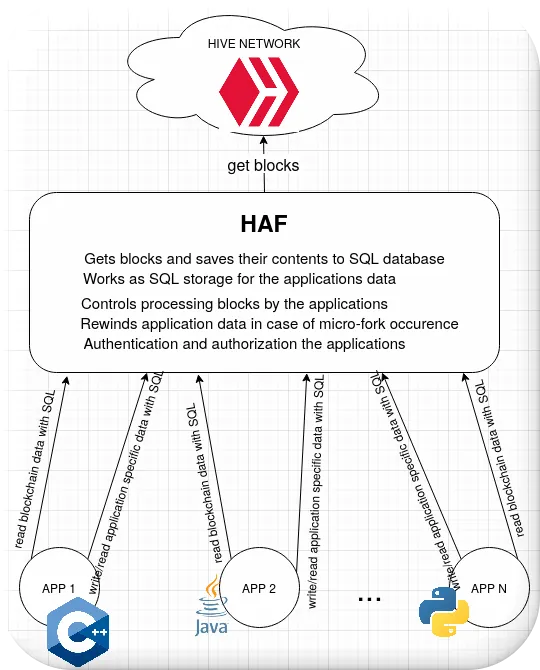
The HAF works between the HIVE network and the applications (App1, App2,...AppN). Below are explained the presented HAF functionalities:
- Gets blocks and saves their contents to SQL database
It gets blocks from the network and presents their data to applications in form of SQL tables. - Works as SQL storage for the application's data
The applications can create their own tables in the HAF SQL database and save their data. - Controls processing blocks by the applications
The HAF drives the applications with processing blocks by telling them which block shall be processed next. The applications will get the arriving blocks in the correct order, the same as the blocks are created in the chain. - Rewinds application data in case of micro-fork occurrence
If the application wants that, the framework can pass to it reversible blocks to process and in case of fork occurrence automatically, transparently for the application, rollback all the changes which were based on abandoned blocks. It allows the applications to present new data immediately after a new block was created, without the need to wait for a moment when the block becomes irreversible. - Authentication and authorization of the applications
The HAF gives some mechanisms that protect the application's data against access by undesirable persons. Each of the applications cannot look at other applications' data, except when they explicitly share their tables.
The HAF API is a set of SQL functions, so the applications can be written with any programming language which has binding to SQL - almost every language has it.
Lets look a little deeper at the framework
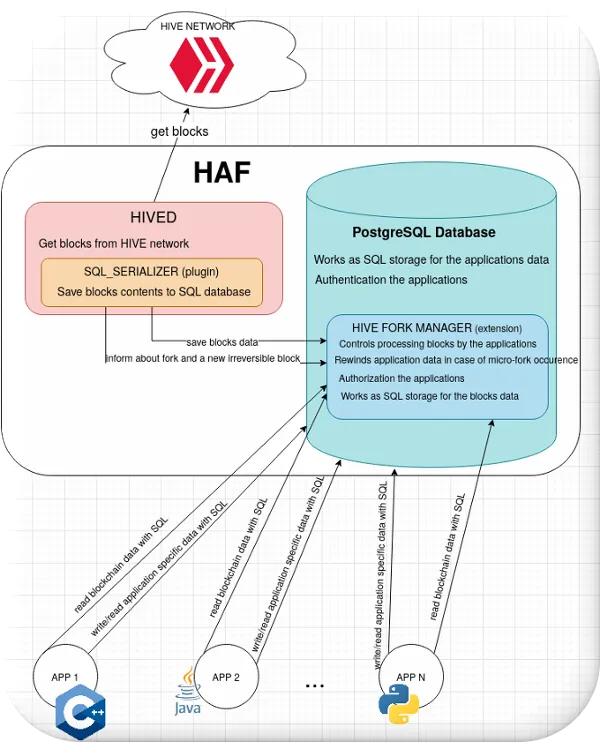
The HAF contains a few components visible at the picture above:
- HIVED - hive node
Regular HIVE node which syncs blocks with the HIVE network or replays them from block.log file.- SQL_SERIALIZER
A hived's plugin (the hive node plugin) which during syncing a new block pushes its data to SQL database. Moreover, the plugin informs the database about the occurrence of micro-fork and changing a block status from reversible to irreversible.
- SQL_SERIALIZER
- PostgreSQL database
The database contains the blockchain blocks data in form of filled SQL tables, and the applications tables. The system utilizes Postgres authentication and authorization mechanisms.- HIVE FORK MANAGER
The PostgreSQL extension provides the HAF's API - a set of SQL functions that are used by the application to get blocks data. The extension controls the process by which applications consume blocks and ensures that applications cannot corrupt each other. The HIVE FORK MANAGER is responsible for rewind the applications tables changes in case of micro-fork occurrence. The extension defines the format of blocks data saved in the database. The SQL_SERIALIZER dumps blocks to the tables defined by HIVE FORK MANAGER.
- HIVE FORK MANAGER
How The HAF can help The HIVE blockchain ?
It allows separating applications codes from code of basic tasks realized by blockchain. The vital tasks of The HIVE, like block producing , blocks evaluation, etc., won't be disturbed by the application's specific requirements. With The HAF we can look at the blockchain ecosystem as a layered architecture:
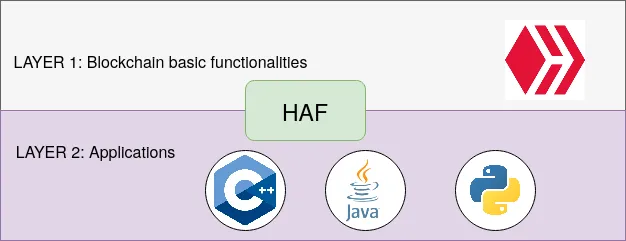
Such architecture gives also benefits to the applications programmers. They get an SQL interface to the blockchain and may start to write simple applications very fast. The complexity of getting blocks and support of micro-forks is hidden behind The HAF. You can see how simple the application can be by looking at the example available on GitLab here
Where are the codes ?
You can find hived code on gitlab here, the SQL_SERIALIZER and HIVE FORK MANGER are parts of HAF project