
Below is a list of Hive-related programming issues worked on by BlockTrades team during last week or so:
Hived work (blockchain node software)
Cli-wallet signing enhancement and bug fix
We’ve enhanced the command-line interface wallet to allow it to sign transactions using account authority. We’re currently testing this.
We fixed an erroneous error message from cli wallet that could occur when calling list_my_accounts: https://gitlab.syncad.com/hive/hive/-/issues/173
Performance metrics for continuous integration system
We’re also adding performance metrics to our automated build-and-test (CI) system: https://gitlab.syncad.com/hive/tests_api/-/tree/request-execution-time
These changes are also being made for hivemind tests:
https://gitlab.syncad.com/hive/tests_api/-/tree/request-execution-time
This work is still in progress.
Fixed final issues associated with account history and last irreversible block
We also completed a few fixes related to account history and the last irreversible block and added some new tests:
https://gitlab.syncad.com/hive/hive/-/merge_requests/275
Continuing work on blockhain converter tool
We’re also continuing work on the blockchain converter that generates a testnet blockchain configuration form an existing blocklog. Most recently, we added multithreading support to speed it up. You can follow the work on this task here: https://gitlab.syncad.com/hive/hive/-/commits/tm-blockchain-converter/
Hivemind (2nd layer applications + social media middleware)
Dramatically reduced memory consumption
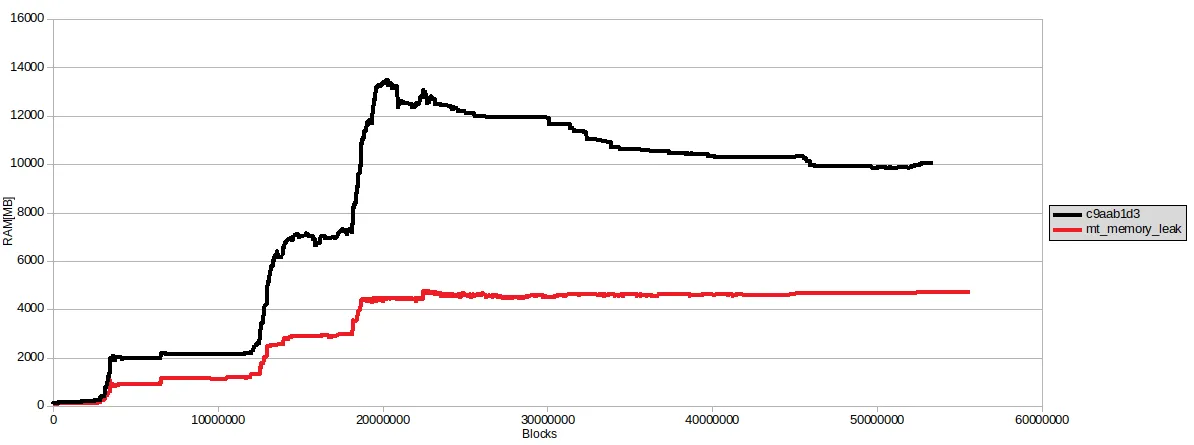
We’ve made some progress on hivemind’s memory consumption issue. While it appears the leak issue is gone (probably fixed when we pinned versions of library dependencies used by hivemind), we still saw some higher-than-desirable memory usage during massive sync. We made several changes (queues used by consumer/provider were too long, used prepared queries where possible, explicitly cleared some python containers) to reduce this number and were able to reduce hivemind’s peak memory usage from over 13GB to just over 4GB. Changes are here: https://gitlab.syncad.com/hive/hivemind/-/commits/mt-memory-leak/
Here’s a graph of memory usage before and after the above changes:
Optimized update_post_rshares down from 11.4hrs to ~15m
We’re also continuing work on optimizing the update_post_rshares function that is executed after massive sync. Originally this function took 11.4 hours and we’ve reduced it to around 15 minutes by adding an index. Initially this index was pretty large (around 25GB), but we’ve also made other optimizations to reduce database writes wrelated to posts that paid out during massigive sync, and this has not only reduced IO usage, it also reduced the size required by this index. It’s also worth noting that this index can be dropped after update_post_rshares has completed.
Made hivemind shutdown time configurable when it loses contact with hived
Hivemind had an annoying habit of shutting down completely if it lost contact with the hived node that it was using to get blockchain data (it retried 25 times, then shutdown). This was problematic because this meant that temporary network disruptions could leave hivemind dead in the water. We’ve added a new option, --max-retries (or –max-allowed-retries, to be determined) which will default to a value of -1 (infinitely retry).
We’re also moving hivemind tests out of the tests-api repo to hivemind repo as part of some general restructuring of the test system.
Hive Application Framework (HAF)
Our primary developer for the forkresolver code in HAF is back as of yesterday and has resumed work on this project. Our next step is to begin developing some sample applications for HAF. I hope to be able to officially release HAF in about a month. Once we have HAF as a foundation, we can begin building our 2nd layer smart contract system on top of it.
What’s next?
For the rest of this week, we’ll be focused on testing associated with above tasks. In the week thereafter, we’ll begin planning what tasks will be scheduled for hardfork 26 as well as other tasks that we plan to complete which can be released sooner (as they don’t require protocol changes). Of such non-hardfork tasks include development of common-use HAF applications (e.g a HAF application to generate tables about Hive accounts and custom_json).