I thought I'd write something more about one point from @blocktrades recent post because certain aspects of related code were news to me despite them being important. Might be useful to pass that knowledge to broader audience.
It should be most useful for those who want to watch the code under debugger, but if you just want to get general idea on how it works, ignore routine names and there is still plenty to read :o)
But first some basics of state - how changes in node data are managed.
Undo sessions are always created during normal work of the node and kept in a stack. Every time some modification is applied to the existing state of the node, the original is stored in topmost undo session, so it is possible to return to the state from before the change. The only exception is when replaying from local block_log, since node knows it is its own data, so it can be trusted (it actually means that exception during replay constitutes fatal error - either block_log is corrupted or there is a serious bug in code of the node, we don't need to be ready to recover and continue running after such error).
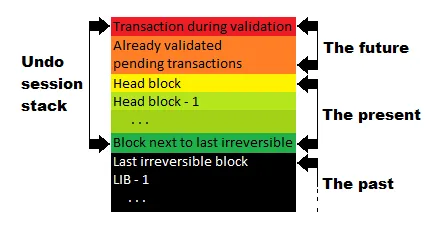
State of the node can be split into three "phases":
- "The past" is the state built solely on irreversible blocks - node is in this phase when it starts after a break and all undo sessions are applied, or it is fresh after replay. It is the state where node has no undo sessions. Note that the node itself can be in the past in relation to other nodes, that is, the network as a whole might already consider more blocks to be irreversible, but the node in question does not know it yet.
- "The present" is the state built on just blocks. There is undo session for each reversible block - node will use them in case of fork. When block receives enough unique witness signatures, it becomes irreversible (now it means that there is long enough chain of further blocks signed by different witnesses, but there are plans to improve that mechanism). Relevant undo session is at the bottom of the stack. Once it is removed the node literally can't "go back into the past" prior to related block. For all nodes that saw the same top block, this phase is identical, unless they are on different forks.
- "The future" is the actual state of the node. The state reflects not just complete signed blocks but also transactions that were already validated but are still waiting to be included in one of upcoming blocks. The order of transactions might be different for different nodes, for some they didn't happen yet (transactions are still being transported over the network) or seemed to be impossible and were dropped (order might influence which transactions are considered valid). Just like different observers described by special relativity :o) (by the way I highly recommend this course on special relativity ). Each node might see a bit different future, however most of the transactions that constitute that future will become part of some block eventually. Therefore it is actually desirable to see related state now. F.e. imagine
alicesending some HIVE tobob- she should see her HIVE gone immediately after transaction was accepted by her chosen API node. If that node was reverting to "the present" right after validating transactions,alicemight think the transfer failed and try to resend it, effectively sending second transaction with new sum of HIVE. In some cases the second transfer might be invalid due to lack of funds, but if nodes were always in "the present", they would keep passing such faulty transaction over the network until previous one became part of some block, which would make second transfer invalid not just in "the future" but also in "the present".
Keeping state in "the future" will be a part of the process described below.
Transactions start their journey in the wallet. They are born in json (text) form. The reason behind it is that json is human readable, so such form can even be presented to the user before transaction is signed. Since json format is pretty loose - the same content can be expressed by different jsons - before transaction is signed, it is expressed as struct in memory, where all necessary elements are present in fixed order and then packed into binary stream (eliminates alignment and should also handle big-endian vs little-endian differences, although I can't find that in the code at the moment). Signatures are calculated on packed binary form and added to transaction, which is subsequently sent to some API node (still as json).
API node reads json into memory to recreate the same struct that wallet saw. Such transaction is not yet validated by anyone. Fresh transaction is pushed onto state of API node to see if it can be properly executed. Transaction is dropped in case of any exception. If everything was ok, it becomes part of mempool as pending and it is passed to P2P plugin to be broadcast further. P2P uses binary form, since from now on transaction will only be passed between nodes (look for p2p_plugin::broadcast_transaction).
The changes made by applying any transaction are remembered in topmost undo session. When transaction turns out to be faulty, all the changes are immediately reverted, as if nothing happened. Valid transaction changes persist. The related undo session remains on the stack.
Nodes exchange messages through P2P. Transaction is one of possible message types. When transaction arrives, it is wrapped in concurrent task within P2P thread (fc::async), which in turn passes it to a queue consumed by worker thread. The task waits for result while P2P thread can go back to handle more messages (as I understand that part of code is what @blocktrades thinks is not working correctly). The content of concurrent task is node_impl::on_message. In case of transaction it follows to node_impl::process_ordinary_message, then to p2p_plugin_impl::handle_transaction and finally to chain_plugin::accept_transaction.
When transaction is passed through P2P, the sending node claims it is valid, but receiving node should not just trust it. It treats it just as it would in case of transaction passed as json through API. Failed transactions are dropped, valid ones become part of mempool and are broadcast further.
If the node is a witness, it behaves as any other node up to the point in time when it detects it is its time to produce block (see witness_plugin_impl::maybe_produce_block). The proper time is up to 1250(Edit: see end of article) 500 ms before expected block timestamp and not later than 250 ms after that timestamp (BLOCK_PRODUCING_LAG_TIME; note that the routine uses current time shifted by 500 ms into the future). Note that node will try to produce even if time for block next to the head one is long gone - it just assumes that whoever was due to produce it, simply failed at that task (this is not necessarily true, the fault might be in the network or even in the node itself, but that is how the reality looks from its perspective). Also note that a single witness node can handle multiple witnesses - maybe not on production but for testnet it is pretty normal situation.

Instead of immediately producing block, request is injected into the worker queue with call to chain_plugin::generate_block. It is done this way most likely to avoid conflicting writes to state - just one thread is allowed to modify state. Also blocks that came before and were not yet processed should come before new block is produced. There is a slight problem in that scheme though. Witness plugin requests building of new block in proper time window, but since worker thread might have significant backlog of transactions in the queue (especially in time of increased demand), the actual production of the block will possibly be outside of that window. At the very least the worker queue should give priority to incoming blocks and new block requests over incoming transactions.
Request for new block is processed in block_producer::generate_block. At the start of block_producer::apply_pending_transactions it recreates undo session for pending transactions, which returns state to "the present". The new undo session will cover whole new pending block. Next pending transactions are executed (note that while they were already validated before, they can still turn out to no longer fit new state, therefore their processing is guarded by separate undo session, which is squashed = merged with main session of pending block once transaction finishes ok). Required and optional actions come after transactions - that mechanism is not used as far as I know (it was prepared for SMTs), but the idea behind it was to introduce actions performed normally by the node as explicit parts of the block (IMHO they would probably just inflate size of block - it should be easier to hardcode proper logic into database::_apply_block with every other action performed automatically). At the end all effects of pending block are removed from the state and the block itself is signed. It is now reapplied as if it was received from P2P and then passed back to witness plugin which sends it to P2P to be broadcast. It doesn't make much difference (at least at the moment when the blocks are small), however I think it would be better if block was reapplied only after it was returned and sent to P2P. "Why reapply it in the first place" - you might ask - "Wouldn't it be faster to just leave the state from block production process?" The reason behind it is that code that handles transactions behaves at times a bit differently when it is the node that holds the power (is_producing() == true) and when it has to respect the decisions made by witness that produced the block (is_producing() == false). By clearing the state after production and reapplying, we make sure that all the blocks in all nodes are processed the same way, ensuring that all nodes see the same chain reality, even in case of bug.
So, we have new block full of transactions. That block is passed through P2P in packed binary form, just like single transactions were passed before. P2P plugin receives blocks while in one of two modes - normal mode (node_impl::process_block_during_normal_operation) and sync mode (node_impl::process_block_during_sync). I'm not sure how it switches between the two, but it looks like either way the block is handled further by p2p_plugin_impl::handle_block followed by chain_plugin::accept_block, where it is put in the same worker thread queue as transactions were previously (the problems mentioned before for transactions are present for blocks as well).
Further work is a standard database::push_block call, similar to database::push_transaction in case of transactions. There is one detail that might be easily missed, hidden within without_pending_transactions call (or, to be more specific, in destructor of pending_transactions_restorer). All the pending transactions are put aside, the block is executed with database::_push_block and then pending transactions are reapplied. The end of block execution shifts "the present" to that new block. Reapplying popped transactions (the ones that were previously part of blocks but were reverted due to fork) and pending transactions shifts the state back to "the future". Since there can be very large amount of pending transactions, the process is limited to 200 ms of execution time. Transactions that didn't fit in time limit are just moved to the pending list without being revalidated. There is one important aspect of that process aside from return to "the future". Transactions that were in the pending list but were also part of last processed block are now duplicates - their reapplication attempt ends in exception which in turn causes them to fall out of pending list. Also some pending transactions might happen to become outdated - either they waited too long to be included in block and expired or are no longer valid due to conflict with some other transaction that was included in recent block (f.e. alice sending all her HIVE to bob and then the same tokens to steve - if the node received the latter first, it would make it to the pending list, but later the former comes with block making transfer to steve no longer valid). This is the way to ensure the mempool does not grow indefinitely. One important detail - when transactions are executed during above process, the node is in is_producing() == false state. It means that is_producing() == false does not mean "current transaction is part of some block" which was the core problem of issue #197 and why I even wandered into all the code mentioned in this article.
Ok, so let's see fragment of witness log.
2021-10-19T16:22:12.405521 node.cpp:3474 process_block_during ] p2p pushing block #58426349 037b83edac38891c6565a09a7d560825d5b38995 from 95.217.143.98:2001 (message_id was 23491abad6d11f42e6a79a90b0b0458287949229)
2021-10-19T16:22:12.405630 p2p_plugin.cpp:166 handle_block ] chain pushing block #58426349 037b83edac38891c6565a09a7d560825d5b38995, head is 58426348
2021-10-19T16:22:12.678892 db_with.hpp:125 ~pending_transaction ] Postponed 3 pending transactions. 1284 were applied.
2021-10-19T16:22:12.679299 p2p_plugin.cpp:183 handle_block ] Got 216 transactions on block 58426349 by stoodkev -- Block Time Offset: 679 ms
Also see the block itself.
The block timestamp is 2021-10-19T16:22:12. As we know the witness that produced it (stoodkev) could have started its work 500 ms before that time. We don't know when he actually did, but all the waiting on locks in P2P thread, then processing backlog of transactions in worker queue, making of new block, reapplying it and finally transport over the network caused offset of 405 ms from the timestamp, before our node received the block. Now our node executes potential local backlog of transactions waiting in worker queue, then the block (containing 216 transactions) and revalidates 1284 pending transactions (not counting those that were dropped) plus 3 didn't fit in 200 ms time limit. It all added up to final offset of 679 ms.
It should be clear that only P2P locking and lack of block prioritization is the problem here. The block was executed in less than 679 - 405 - 200 = 74 ms (which is still not true since that time also covers local backlog).
So there are some problems in the code described above. Should it be a source of concern? Actually not. They were found and diagnosed, it is just a matter of time before they are addressed. Now we can also be confident, that once fixes are applied, there will be no danger in allowing more transactions, at least from execution time perspective (it also confirms what RC analysis showed before). In fact if witnesses voted for bigger blocks, nodes would have less work to do, because transactions would pass through pending phase faster. It is not that easy of course, since bigger blocks might open some other problems that need to be tackled first (I won't describe them here for security reasons) however at the very least it looks like RC pool related to execution time could be made bigger meaning somewhat smaller RC cost of transactions. By the way I might write about RC changes next, but don't hold your breath :o)
Edit note: the production opportunity window is indeed 750 ms both ways from now()+500ms = [-1250 ms .. 250 ms], however if current time was within [-1250 ms .. -500 ms), then previous slot would be active, meaning the time would be compared with earlier scheduled_time and outside its window. Related picture and text fragments corrected.