
Un des défis aujourd'hui est de pouvoir traiter des données de plus en plus volumineuses de manière rapide et efficace sans pour autant perdre de l'information. La stratégie est de distribuer le stockage de données et de paralléliser leur traitement.
Il y a 2 challenges à relever :
- les traitements sur les données doivent être divisés en tâches indépendantes pour pouvoir être exécutées en parallèle sur plusieurs machines afin de minimiser la durée du traitement.
- les données doivent être redondées sur plusieurs machines pour garantir la disponibilité des données en cas de panne d'une machine.
MapReduce répond au premier challenge par le parallélisme des traitements et HDFS (Hadoop Distributed File System) répond au second challenge par la redondance des données.
Définition
Hadoop est un framework libre faisant partie des projets de la fondation logicielle Apache. Ce framework permet le traitement par application distribuée de grands volumes de données à travers des noeuds réparties sur différentes machines. Le traitement des données se fait par bloc qui sont traités de façon optimale. Hadoop a été conçu pour être résistant aux pannes qui peuvent être fréquentes sur ce genre de structure étant donné le grand nombre de machines.
MapReduce est un modèle algorithmique de type diviser pour régner qui découpe automatiquement les traitements en tâches indépendantes et les exécute en parallèle sur plusieurs machines dans un cluster.
L'algorithme MapReduce est composé de 3 étapes :
- Map
- Shuffle
- Reduce
Pour mieux comprendre le fonctionnement de MapReduce, voir le schéma à la fin de l'article.
Map
Dans cette étape les données à traiter sont déjà partitionnées dans le HDFS.
Chaque tâche Map se charge d'une partition. Map est une fonction qui prend en entrée un ensemble de données et qui les transforme en un ensemble de paires clé/valeur.
Ici le terme Map n'est pas dans le sens objet, mais dans le sens fonctionnel.
Shuffle
Cette étape intermédiaire commence quand l'étape précédente se termine.
Cette étape a 2 parties :
- trier toutes les paires clé/valeur par clé
- regrouper dans une liste pour chaque clé, toutes les valeurs se trouvant dans différents noeuds (il y a communication entre les noeuds)
On a donc maintenant pour chaque clé une liste de valeurs, et non plus une seule valeur.
Le résultat de cette étape est compatible avec l'entrée de l'étape suivante Reduce.
Reduce
Le but de cette dernière étape est de réduire les données des valeurs associées à chaque clé.
Dans l'illustration en fin d'article, on peut voir que la valeur pour une clé est transformée d'une liste de valeurs à une seule valeur.
Dans la fonction Reduce il est possible d'utiliser l'agrégat désiré comme par exemple la somme, la moyenne, le maximum, le minimum, etc. Il est aussi possible de faire des opérations sur les résultats comme par exemple l'affichage, l'enregistrement dans une base de données, ou l'envoi à un autre job MapReduce.
Vue d'ensemble avec un schéma
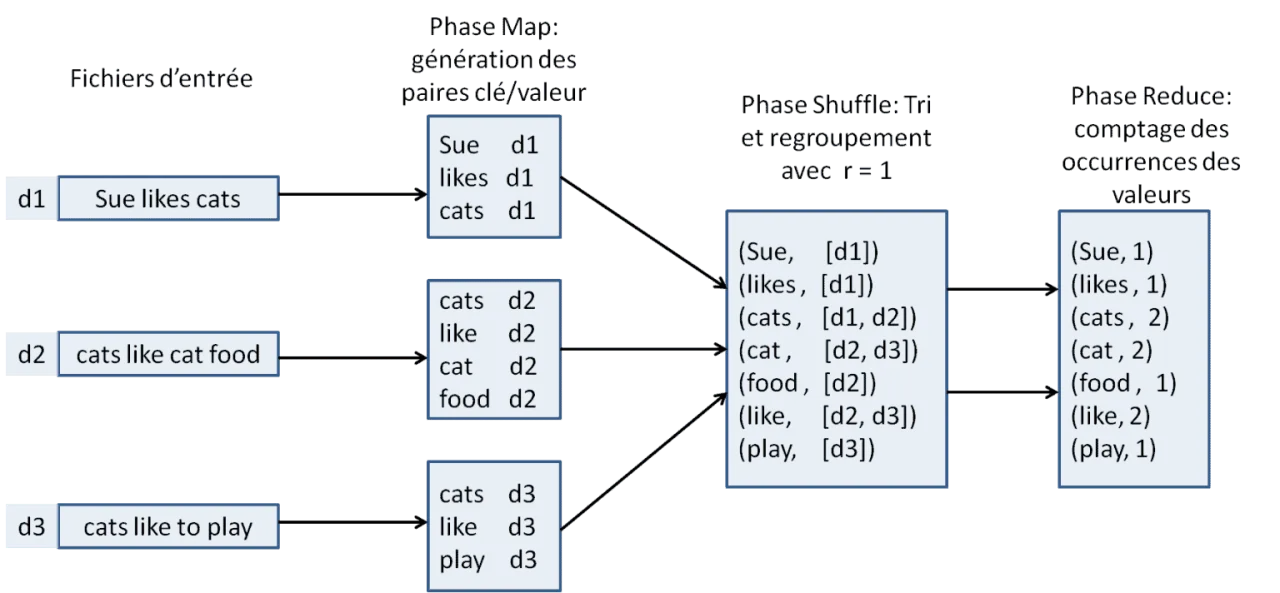
Source : https://www.data-transitionnumerique.com
Pendant la phase Map, le traitement des données est complètement indépendant entre les noeuds.
Cependant pendant la phase Reduce, les noeuds communiquent entre eux à travers les fichiers ce qui peut s'avérer être lent.
La programmation MapReduce fournit une abstraction pour l'utilisateur. Le système se charge de lancer l'exécution des tâches en parallèle et leur coordination dans le cluster. Ainsi du point de vue de l'utilisateur, il ne fournit que le job MapReduce, c'est-à-dire les fonctions Map et Reduce.
Mais, quel est le lien avec Hadoop, et comment s'exécute-t-il dans un cluster Hadoop ?
Hadoop
Le traitement des données par MapReduce est exécuté dans un cluster Hadoop en 7 étapes :
- Configuration de Job MapReduce puis exécution sur le cluster
- Partitionnement en taille fixe et réplication de manière redondante du fichier par HDFS
- Lancement du processus Map sur chaque noeud
- Partitionnement des paires clé/valeur dans des régions et communication de la localisation des régions
- Lecture des pairs clé/valeur à distance pour l'étape Shuffle
- Lancement du processus Reduce sur n noeuds
- Récupération des résultats