班主任老师发来期中考试各科成绩表,毫无疑问地考砸了,但是还是想对数据进行一下分析,然而老师发过来的是一幅图片的形式,看起来非常不方便。

(图源 :pixabay)
于是我就冒出一个想法,把图片形式的表格重新转换成Excel形式的数据表,方便阅读和分析。
上网查了一下,图片转表格大概有以下方式:
对于方法一,我不想把数据上传到互联网上,所以就没去尝试。
方法二,我试了一下,我的Word、Excel中根本就找不到这项功能,研究了好长一段时间,才搞明白,这个功能是最新(或者相对较新)的版本中才有的,哎。
那么只能用方法三了,当然还是选择Python,我搜索了一下,发现有个img2table似乎能做这件事。于是费了九牛二虎之力装上了img2table。
pip install img2table
然后写了一段测试代码:
from img2table.document import Image
img = Image(src="image.png")
img.to_xlsx("image.xlsx")
结果,不愧是img2table,生成的表格和我提供的原始表格一模一样(合并、拆分的单元格都有)
但是,我的数据呢?
又研究了好久,原来img2table的实现中,抽取表格数据需要使用OCR软件支持来实现。
我首先考虑的使用paddleocr,于是按着教程安装paddleocr :
pip install img2table[paddle]
结果安装过程各种出错,比如说:
Failed to build pymupdf
ERROR: Could not build wheels for pymupdf, which is required to install pyproject.toml-based projects
又是一通研究,大概是对pymupdf版本要求和img2table不一致,各种方案胡乱地试,竟然神奇地安装上了。
又写了新的测试代码:
from img2table.document import Image
from img2table.ocr import PaddleOCR
ocr = PaddleOCR(lang="ch")
img = Image(src="image.png")
img.to_xlsx("image.xlsx", ocr=ocr)
结果运行时报了一堆错误,比如这个:
np.intwas a deprecated alias for the builtinint. To avoid this error in existing code, useintby itself. Doing this will not modify any behavior and is safe. When replacingnp.int, you may wish to use e.g.np.int64ornp.int32to specify the precision. If you wish to review your current use, check the release note link for additional information.
改来改去,越改越晕,放弃之。
既然那个方案不行,咱再换个方案,使用easyocr:
pip install easyocr
安装倒是非常顺利。
写了新的代码:
from img2table.document import Image
from img2table.ocr import EasyOCR
ocr = EasyOCR(lang=['ch_sim', 'en'])
img = Image(src="image.png")
img.to_xlsx("image.xlsx", ocr=ocr)
结果运行时出现提示:
Downloading detection model, please wait. This may take several minutes depending upon your network connection.
这倒也没问题,下载识别模型嘛,可以理解。可是问题是,可能是我网络的问题,始终卡在这里不动。
于是去网站上手动下载了模型:https://www.jaided.ai/easyocr/modelhub/ ,并手动解压模型,复制到对应目录。
我下载了CRAFT、zh_sim_g2 (中文语言)、english_g2(英文语言),解压后的.pth 文件放入 ~/.EasyOCR/model 目录下。
然后再测试抽取表格出来,结果倒是正常运行了,也识别出部分中文来,但是问题是,大部分数据都没识别出来呀。
这不逗我一样嘛?
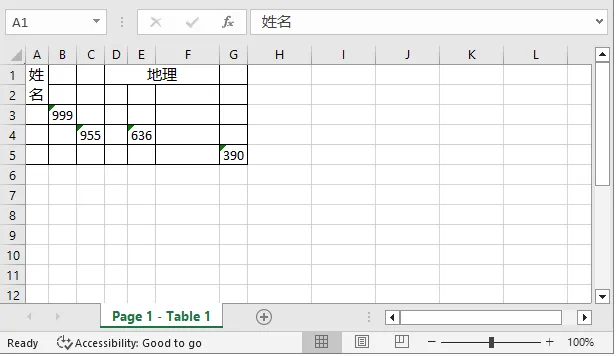
而从网络上随便找了个表格,来测试转换成Excel,相对就好很多。
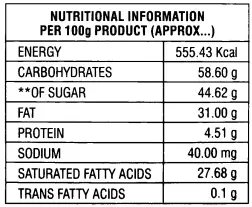
这是表格:
这是转换结果:
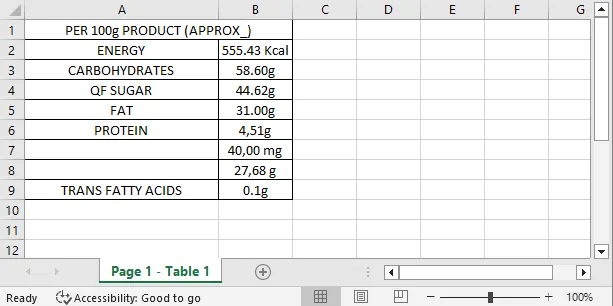
好吧,结果中还是丢了好多数据以及细节。
我估计可能还是我打开的方式不对,毕竟这么复杂的一件事情,怎么可能一整天就研究明白呢?比如是不是有好多影响识别的参数没设置明白?
之后,我打算从两个方向尝试解决这个问题:
顺便说一下,我研究了一整天,没整出个结果,而媳妇用了二十多分钟就把图片中的数据都敲到Excel中了,然后嘲笑了我大半天,呜呜呜。