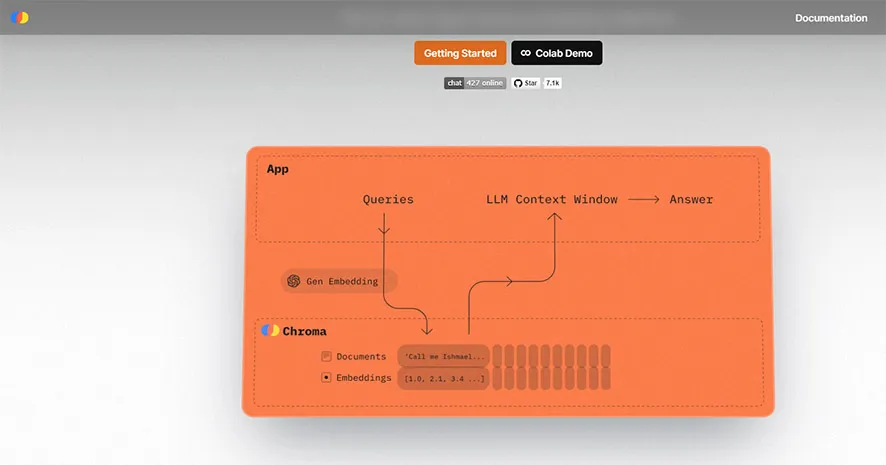
Chroma is a new AI native open-source embedding database.Chroma is the open-source embedding database. Chroma makes it easy to build LLM apps by making knowledge, facts, and skills pluggable for LLMs.
向量数据库 Chroma
pip install chromadb
//chromadb 0.3.29
//python3.10.6 要先装 torch, 再装 chromadb
//python3.11版无法安装!
# 预先依赖
pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple //2.0.1 一堆 nvidia-cublas
//pip install torch
//pip install sentence-transformers
# 虚拟环境
source pythonEnv/bin/activate
ChromaDB使用
import chromadb
# print(366, dir(chromadb))
366 ['API', 'Client', 'ClientStartEvent', 'Settings', 'System', 'Telemetry', '__builtins__', '__cached__',
'__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__settings', '__spec__',
'__version__', 'api', 'chromadb', 'config', 'configure', 'errors', 'get_settings', 'logger', 'logging',
'telemetry', 'types', 'utils']
client = chromadb.Client() # 内存模式
# print(489, dir(client))
489 ['__abstractmethods__', '__annotations__', '__class__', '__delattr__', '__dict__', '__dir__',
'__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__',
'__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__',
'__repr__', '__setattr__', '__sizeof__', '__slots__', '__str__', '__subclasshook__', '__weakref__',
'_abc_impl', '_add', '_count', '_db', '_delete', '_dependencies', '_get', '_modify', '_peek', '_query',
'_running', '_system', '_telemetry_client', '_update', '_upsert', 'create_collection', 'create_index',
'delete_collection', 'dependencies', 'get_collection', 'get_or_create_collection', 'get_version', 'heartbeat',
'list_collections', 'persist', 'raw_sql', 'require', 'reset', 'reset_state', 'start', 'stop']
# 内存模式加磁盘存储
from chromadb.config import Settings
client = chromadb.Client(Settings(chroma_db_impl="duckdb+parquet", persist_directory="./chromadb"))
collection = client.get_or_create_collection(name="my_collection2")
# collection = client.create_collection(name="my_collection2")
112 ['Config', '__abstractmethods__', '__annotations__', '__class__', '__class_vars__', '__config__', '__custom_root_type__',
'__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__exclude_fields__', '__fields__', '__fields_set__', '__format__',
'__ge__', '__get_validators__', '__getattribute__', '__getstate__', '__gt__', '__hash__', '__include_fields__', '__init__',
'__init_subclass__', '__iter__', '__json_encoder__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__post_root_validators__',
'__pre_root_validators__', '__pretty__', '__private_attributes__', '__reduce__', '__reduce_ex__', '__repr__', '__repr_args__',
'__repr_name__', '__repr_str__', '__rich_repr__', '__schema_cache__', '__setattr__', '__setstate__', '__signature__', '__sizeof__',
'__slots__', '__str__', '__subclasshook__', '__try_update_forward_refs__', '__validators__', '_abc_impl', '_calculate_keys',
'_client', '_copy_and_set_values', '_decompose_class', '_embedding_function', '_enforce_dict_if_root', '_get_value',
'_init_private_attributes', '_iter', '_validate_embedding_set', 'add', 'construct', 'copy', 'count', 'create_index',
'delete', 'dict', 'from_orm', 'get', 'id', 'json', 'metadata', 'modify', 'name', 'parse_file', 'parse_obj', 'parse_raw',
'peek', 'query', 'schema', 'schema_json', 'update', 'update_forward_refs', 'upsert', 'validate']
# collection = client.create_collection(name="my_collection", embedding_function=emb_fn)
# collection = client.get_collection(name="my_collection", embedding_function=emb_fn)
# Chroma集合创建时带有一个名称和一个可选的嵌入函数。如果提供了嵌入函数,则每次获取集合时都必须提供。
collection.add(
documents=["2022年2月2号,美国国防部宣布:将向欧洲增派部队,应对俄乌边境地区的紧张局势.", " 2月17号,乌克兰军方称:东部民间武装向政府军控制区发动炮击,而东部民间武装则指责乌政府军先动用了重型武器发动袭击,乌东地区紧张局势持续升级"],
metadatas=[{"source": "my_source"}, {"source": "my_source"}],
ids=["id1", "id2"]
)
# 如果 Chroma 收到一个文档列表,它会自动标记并使用集合的嵌入函数嵌入这些文档(如果在创建集合时没有提供嵌入函数,则使用默认值)。Chroma也会存储文档本身。如果文档过大,无法使用所选的嵌入函数嵌入,则会出现异常。
# 每个文档必须有一个唯一的相关ID。尝试.添加相同的ID两次将导致错误。可以为每个文档提供一个可选的元数据字典列表,以存储附加信息并进行过滤。
# 或者,您也可以直接提供文档相关嵌入的列表,Chroma将存储相关文档,而不会自行嵌入。
# collection.add(
# embeddings=[[1.2, 2.3, 4.5], [6.7, 8.2, 9.2]],
# documents=["This is a document", "This is another document"],
# metadatas=[{"source": "my_source"}, {"source": "my_source"}],
# ids=["id1", "id2"]
# )
collection.query(
query_embeddings=[[11.1, 12.1, 13.1],[1.1, 2.3, 3.2], ...],
n_results=10,
where={"metadata_field": "is_equal_to_this"},
where_document={"$contains":"search_string"}
)
results = collection.query(
query_texts=["俄乌战争发生在哪天?"],
n_results=2
)
print(156, results)
156 {'ids': [['id1', 'id2']], 'embeddings': None, 'documents': [['2022年2月2号,美国国防部宣布:将向欧洲增派部队,应对俄乌边境地区的紧张局势.',
' 2月17号,乌克兰军方称:东部民间武装向政府军控制区发动炮击,而东部民间武装则指责乌政府军先动用了重型武器发动袭击,乌东地区紧张局势持续升级']],
'metadatas': [[{'source': 'my_source'}, {'source': 'my_source'}]], 'distances': [[1.2127416133880615, 1.3881784677505493]]}
ChromaDB案例
# 存入数据库
import chromadb
from chromadb.config import Settings
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders import TextLoader
import uuid
client = chromadb.Client(Settings(chroma_db_impl="duckdb+parquet", persist_directory="./chromadb"))
collection = client.get_or_create_collection(name="my_collection8")
loader = TextLoader('./russia.txt', encoding='gbk')
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=400, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
Adocs = []
Ids = []
for i in range(len(docs)):
Adocs.append(docs[i].page_content)
Ids.append(uuid.uuid4())
print(566, Adocs, 666, Ids )
collection.add(documents=Adocs, ids=Ids)
print(126, "saveDb ok", collection)
# 查询
import chromadb
from chromadb.config import Settings
client = chromadb.Client(Settings(chroma_db_impl="duckdb+parquet", persist_directory="./chromadb"))
collection = client.get_collection(name="my_collection8")
results = collection.query(
query_texts=["俄乌战争发生在哪天?"],
n_results=2
)
print(156, results)
Chroma embedding
嵌入式是A.I(人工智能)表示任何类型数据的原生方式,因此非常适合与各种A.I(人工智能)工具和算法配合使用。它们可以表示文本、图像以及音频和视频。无论是本地使用安装的库,还是调用API,创建嵌入式都有很多选择。
Chroma为流行的嵌入式提供商提供了轻量级封装,使您可以轻松地在应用程序中使用它们。您可以在创建Chroma集合时设置一个嵌入函数,该函数将被自动使用,您也可以自己直接调用它们。
from chromadb.utils import embedding_functions
default_ef = embedding_functions.DefaultEmbeddingFunction()
# By default, Chroma uses the Sentence Transformers all-MiniLM-L6-v2 model to create embeddings.
print(235, default_ef)
res = default_ef("hello world")
print(456, res)
# 向量化速度很慢,不推荐使用
# Custom Embedding Functions
You can create your own embedding function to use with Chroma, it just needs to implement the EmbeddingFunction protocol.
from chromadb.api.types import Documents, EmbeddingFunction, Embeddings
class MyEmbeddingFunction(EmbeddingFunction):
def __call__(self, texts: Documents) -> Embeddings:
# embed the documents somehow
return embeddings
Chroma docker
//server
docker-compose up -d --build
//client
pip install chromadb-client
//请注意,chromadb-client软件包是完整Chroma库的子集,并不包含所有依赖项。如果您想使用完整的Chroma库,可以安装chromadb包。最重要的是,没有默认的嵌入函数。如果您在 add() 文档时没有使用嵌入函数,您必须手动指定一个嵌入函数并为其安装依赖项。
import chromadb
from chromadb.config import Settings
# Example setup of the client to connect to your chroma server
client = chromadb.Client(Settings(chroma_api_impl="rest", chroma_server_host="localhost", chroma_server_http_port=8000))
langchain中的使用
from langchain.vectorstores import Chroma
# print(156, dir(Chroma))
// langchain 默认文档 collections [Collection(name=langchain)]
///
156 ['_Chroma__query_collection', '_LANGCHAIN_DEFAULT_COLLECTION_NAME', '__abstractmethods__', '__class__',
'__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__',
'__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__',
'__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__slots__', '__str__', '__subclasshook__',
'__weakref__', '_abc_impl', '_cosine_relevance_score_fn', '_euclidean_relevance_score_fn', '_max_inner_product_relevance_score_fn',
'_select_relevance_score_fn', '_similarity_search_with_relevance_scores', 'aadd_documents', 'aadd_texts', 'add_documents',
'add_texts', 'afrom_documents', 'afrom_texts', 'amax_marginal_relevance_search', 'amax_marginal_relevance_search_by_vector',
'as_retriever', 'asearch', 'asimilarity_search', 'asimilarity_search_by_vector', 'asimilarity_search_with_relevance_scores',
'delete', 'delete_collection', 'from_documents', 'from_texts', 'get', 'max_marginal_relevance_search',
'max_marginal_relevance_search_by_vector', 'persist', 'search', 'similarity_search', 'similarity_search_by_vector',
'similarity_search_by_vector_with_relevance_scores', 'similarity_search_with_relevance_scores',
'similarity_search_with_score', 'update_document']
# 持久化数据
docsearch = Chroma.from_documents(documents, embeddings, persist_directory="./chromadb")
docsearch.persist()
# 加载数据
docsearch = Chroma(persist_directory="./chromadb", embedding_function=embeddings)
eg:
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.document_loaders import TextLoader
import os
os.environ["OPENAI_API_KEY"] = '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'
loader = TextLoader('./russia2.txt')
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=400, chunk_overlap=0)
# chunk_size=1000表示每次读取或写入数据时,数据的大小为400个字节, 约200~400个汉字
# 对于英文LangChain一般会使用RecursiveCharacterTextSplitter处理。由于中文的复杂性,会使用到jieba等处理工具预处理中文语句。
docs = text_splitter.split_documents(documents)
embedding = OpenAIEmbeddings()
vectordb = Chroma.from_documents(docs, embeddings)
query = "What did the president say about Ketanji Brown Jackson"
docs = vectordb.similarity_search(query)
print(docs[0].page_content)
# 持久化db
# 为每个分块创建嵌入,并插入Chroma矢量数据库。persist_directory参数告诉ChromaDB,当数据库被持久化时,将其存储在哪里。
persist_directory = './chromadb'
vectordb = Chroma.from_documents(documents=docs, embedding=embedding, persist_directory=persist_directory)
vectordb.persist()
# Using embedded DuckDB with persistence: data will be stored in: ./chromadb
vectordb = None
# 直接加载数据库,然后查询相似度的文本
vectordb = Chroma(persist_directory=persist_directory, embedding_function=embedding)
query = "On what date did the war between Russia and Ukraine take place?"
retriever = vectordb.as_retriever(search_type="mmr")
s = retriever.get_relevant_documents(query)[0]
print(123, s)
/////
page_content="On February 24, 2022, with President Putin's declaration of recognition of the independence of
the two autonomous republics of Ukraine, Luhansk and Donetsk, a Russian war against Ukraine broke out immediately.
By the 27th BST, the Russian-Ukrainian conflict entered its third day, with an alley battle breaking out in Kiev and
more intense fighting than ever before. On the 26th, local Ukrainian time, both Russia and Ukraine said that Kiev
refused to negotiate.\n\nOn February 25, 2022, at 6:30 p.m., Zelensky issued a national mobilization order,
ordering the recruitment of new soldiers and reservists and banning male citizens aged 18-60 from
leaving the country. at 7:00 p.m., Zelensky said: the day and night of the conflict on the 24th
resulted in 137 deaths and 316 injuries on the Ukrainian side." metadata={'source': './russia2.txt'}
# 或者
docs = vectordb.similarity_search(query)
print(docs[0].page_content)
# huggingface
import sentence_transformers
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
embedding = HuggingFaceEmbeddings(model_name='shibing624/text2vec-base-chinese')
# 较好的中文模型,需要下载包,最好有GPU资源
向量数据库和传统数据的逻辑思路基本一致,只是实现方法上有区别。把传统数据库的增删改查放到向量数据库上也是适用的。对于开发人员来说,学习成本确实不算高。唯一的难点是: 要理解文本向量的概念,在查找时也是以向量计算为依据的。好了,尝试一下不会有错的!