自从宅在家中后,养成了一个习惯:每周五全家一起在家中看一场电影。但每次在选择电影的时候都很耽误时间。于是就想到实现一个自动的程序,每周五下午的在各个影评的平台自动抓取本周热门电影,再发送消息/邮件给我,作为当晚要播放电影的参考。其实这个功能完全可以使用urllib来实现。不过下面使用Python中的爬虫框架Scrapy来实现。
安装并创建项目
首先安装Scrapy:
pip install Scrapy
接下来创建一个项目:
scrapy startproject douban
添加核心代码
items.py
首先修改items.py:
import scrapy
class DoubanItem(scrapy.Item):
name = scrapy.Field()
可以看到DoubanItem类是scrapy.Item的子类。
使用Scrapy shell获取电影标题对应的路径
要想正确获取影片路径,需要使用浏览器的调试工具和Scrapy自带的命令行工具。
在浏览器中打开"https://movie.douban.com/"这个页面,在浏览器的开发者工具中查看:
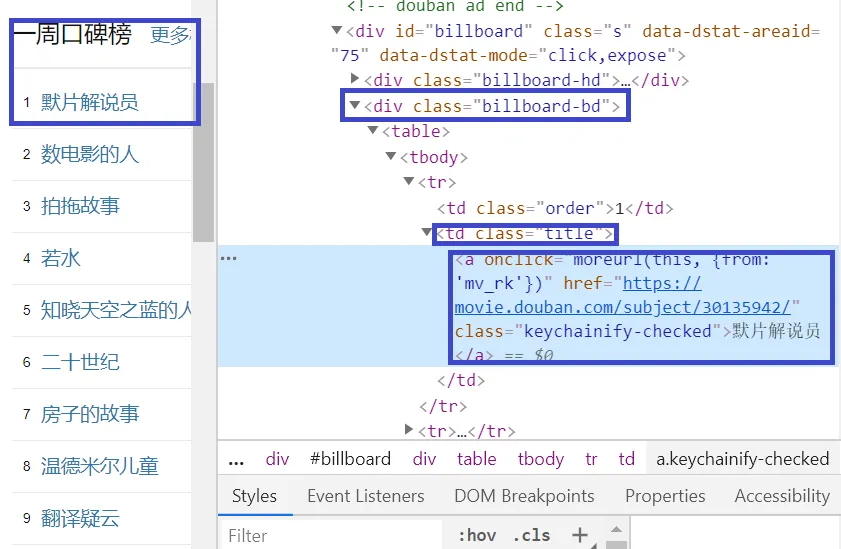
在下面的核心代码中,我们将使用
<div class="billboard-bd">
<td class="title">
<a>
标记来定位影片的标题。
DoubanSpider
接下来编辑文件douban/spiders/douban_spider.py:
import scrapy
class DoubanSpider(scrapy.Spider):
name = "douban"
allowed_domains = ["https://movie.douban.com/"]
start_urls = [
"https://movie.douban.com/"
]
def parse(self, response):
movie_list = []
for movie in response.xpath("//div[@class='billboard-bd']//td[@class='title']/a/text()").getall():
movie_list.append(movie)
print(movie_list)
filename = "/var/tmp/movielist.txt"
with open(filename, 'w') as f:
f.write(str(movie_list))
DoubanSpider类继承自scrapy.Spider这个类。在上面的实现中重写了parse方法,自定义处理逻辑。
尝试运行一下:
scrapy crawl douban
从LOG中可以看到,豆瓣返回了一个403错误。这是由于其反爬虫机制导致的。
打开douban/settings.py,添加如下行:
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:77.0) Gecko/20100101 Firefox/77.0"
再尝试一下,成功!其输出类似于:
2020-06-26 15:49:34 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2020-06-26 15:49:35 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://movie.douban.com/robots.txt> (referer: None)
2020-06-26 15:49:35 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://movie.douban.com/> (referer: None)
['默片解说员', '数电影的人', '拍拖故事', '若水', '知晓天空之蓝的人啊', '二十世纪', '房子的故事', '温德米尔儿童', '翻译疑云', '乳牙']
上面这种方式根本就没有用到前面定义的items.py,如果想要使用的话,可以把douban_spider.py更改为:
import scrapy
class DoubanSpider(scrapy.Spider):
name = "douban"
allowed_domains = ["https://movie.douban.com/"]
start_urls = [
"https://movie.douban.com/"
]
def parse(self, response):
for movie in response.xpath("//div[@class='billboard-bd']//td[@class='title']/a/text()").getall():
yield {
'name': movie
}
需要注意的是,要想输出中文,需要在settings.py中添加:
FEED_EXPORT_ENCODING = 'utf-8'
再次运行:
scrapy crawl douban -o movies.json
其输出为:
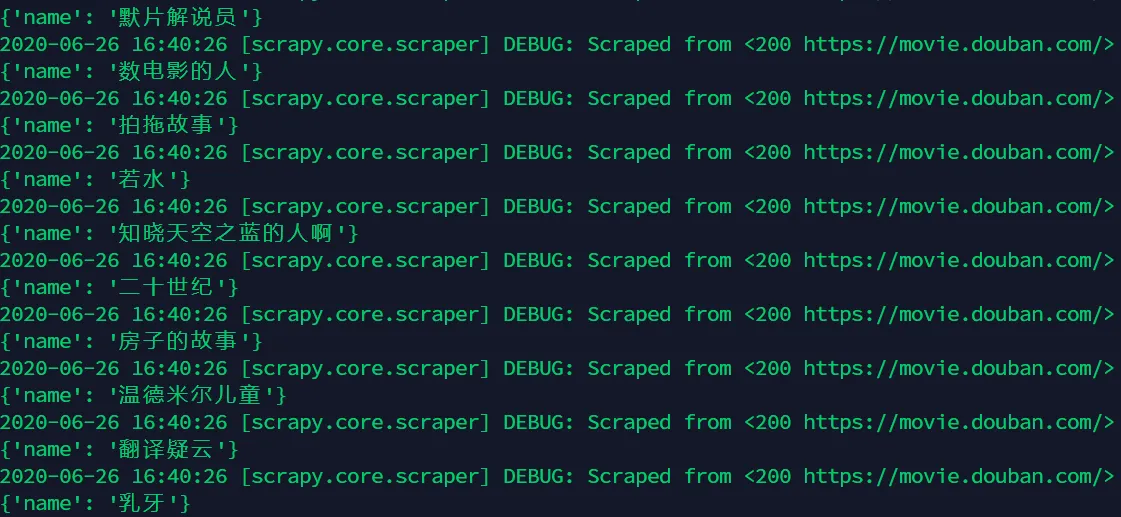
同样结果已经保存在json文件中。然后就可以把这些影片信息发送给自己了。利用同样的思路,可以获取其他影评网站的信息再汇总后一起发给自己。