
Back in March 2020, I had to stop serving Hivemind related API calls as announced here to free up disk space on my server, leaving only hived AH node with all Hivemind APIs being redirected to other public nodes through Jussi.
Now that I have performed the necessary infrastructure changes as described here and weeks of dealing with various technical issues, I can finally bring back the entire full API stack as planned, and it's now better than before.
Not your node, not your rules.
This term is commonly being used in crypto to describe the need for running a Bitcoin full node themselves and not trusting a 3rd party node. The same principle also applies to all other altcoins including Hive.
This is exactly one of the main reasons why I run and maintain Hive API nodes for my own usage as well as putting it out there as another public node that the Hive community can use. I also use my own nodes for Shawp payments and have been recommending doing this in the config file.
Current state of full nodes (Late 2020)
When I first announced techcoderx.com as a full API node exactly 1 year ago here, there were only seven fully-functioning API nodes and there was a clear need for more.
The situation is much better right now, with 19 full API nodes available for use (excluding techcoderx.com). 14 of them are mostly functional, returning little to no errors in my extensive testing (more on that below), and the others returned many more RPC related errors than the others.
While 19 API nodes seem to be quite a number, let's analyse them to have a look at the geographic and provider distribution of those nodes.
These can be found by performing a DNS lookup on the domains.
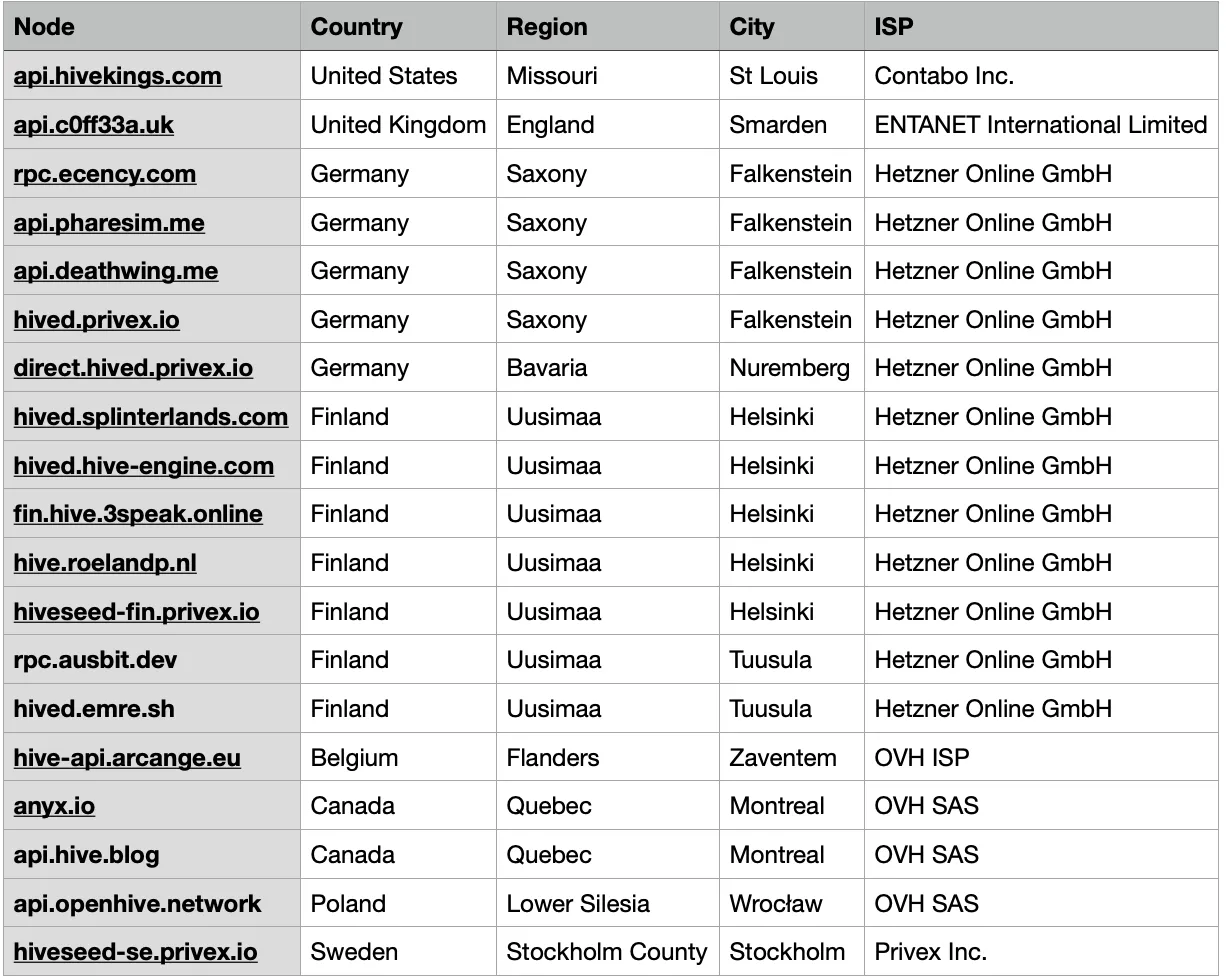
Having a look above, the public nodes are mostly geographically distributed, as they are located across 8 different countries, 5 of them are EU countries while 3 of them are not. Notice that there are many nodes in Germany and Finland.
When it comes to service providers, out of 19, 12 of them are hosted by Hetzner, while 4 are hosted by OVH. That means 16 out of 19 nodes are hosted by only two providers. This, in my personal opinion, is not very decentralized.
Setup
To be able to operate a Hive full API node at the lowest code possible, I have decided to host it on my home internet connection (100 Mbit download, 50 Mbit upload) instead of housing it in a datacenter like what most node operators do. This means purchasing the hardware myself and having access to it most of the time. It is also much more cost-effective when it comes to upgrades as all I have to do is purchase the necessary hardware upgrades without having to pay any extra setup fees to a server provider.

I will be using what it used to be an ETN/XMR CPU+GPU mining rig built with the purpose of doing video editing, which will not be public-facing. I had to purchase a few upgrades, which is the SSD and RAM. It is currently running on an 850VA UPS in case of power outages.
So here are the specs:
AMD Ryzen 7 1700 CPU (8C 16T, OC'ed to 3.7GHz)
ASUS Prime B350M-A Motherboard
48GB DDR4 RAM (2x16GB + 2x32GB), running at 2800 MHz C15
2TB Samsung PM981a NVMe SSD
AMD Radeon RX560 4GB GPU
Cooler Master Hyper 212 Evo
Corsair CX450M PSU
In addition to that, I have Jussi running on a separate $5/month public-facing VPS for improved security and performance, with ~5ms ping times between the two nodes. Here are the specs:
Intel Xeon unknown model, 2.6GHz
1GB DDR3(?) ECC RAM
25GB SSD
1 Gbit port, 20TB/month bandwidth
Location: Malaysia
I have put together all resources used here such as sample config files and useful tools.
Performance
With techcoderx.com node setup being very far from many public nodes, it is expected to perform the best in southeast Asia region, a slightly better-performing node in the rest of Asia Pacific, and not very well in Europe, Americas and the rest of the world (possibly the worst according to @fullnodeupdate).
I have created an extensive Hive API benchmark tool which makes 60 different API calls to each node and records the time it took to receive a response. You can find the script within the same repo here.
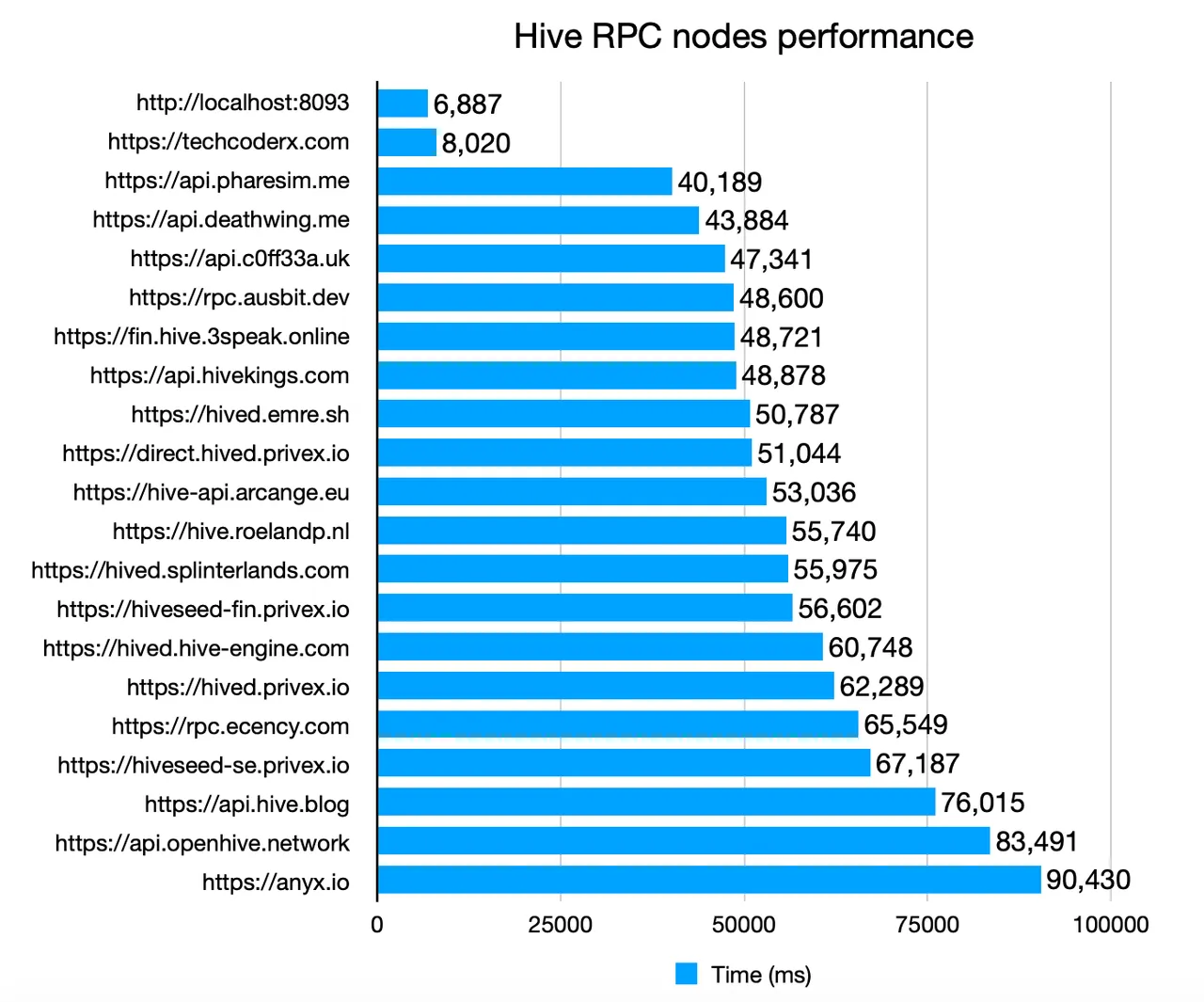
This shows the clear need of having nodes geographically distributed across multiple continents. Having too many public nodes located in Europe and North America would increase the API response times significantly.
From the graph above, there is a significant difference between techcoderx.com API and the rest of the nodes. Benchmark was performed on the same system as my hived and Hivemind node on my home internet connection, which should reflect general user experience.
As I maintain additional servers in the US and Europe, I performed the same test as well. As expected, most API nodes performed much better than the results shown above, with techcoderx.com being the worst performers. Sadly it would not be fair to show those test results here, as the benchmark results from datacenter nodes contains bias towards certain API nodes, hence it does not reflect general user experience.
Extras
In addition to core hived and Hivemind API, techcoderx.com also supports the set of PeakD Hivemind Plugin extended REST APIs.
For example, to retrieve a list badges awarded to an account:
$ curl -s https://techcoderx.com/badges/techcoderx | jq
[
{
"name": "badge-156473",
"created_at": "2020-02-20T01:41:21.000Z",
"reputation": "0",
"followers": 86,
"following": 163,
"title": "Original DTube Creators"
},
{
"name": "badge-100100",
"created_at": "2020-02-07T12:43:12.000Z",
"reputation": "0",
"followers": 55,
"following": 91,
"title": "Hive Witness - Top 100"
},
{
"name": "badge-012345",
"created_at": "2020-06-17T00:52:54.000Z",
"reputation": "288948241",
"followers": 245,
"following": 907,
"title": "DIY Award Winner"
}
]
I have also set up a condenser frontend that exclusively uses techcoderx.com API: https://portal.techcoderx.com
Maintenance
I will be taking monthly filesystem backups of both hived and Hivemind databases in case things go catastrophically wrong, all I need to do is copy everything back instead of spending weeks replaying and resyncing the database.
During those periods, there will be a performance hit as techcoderx.com traffic will be rerouted to another public node (which sadly will be very far in distance).
Witness performance
Let's see how well my witness performed lately :)
Current rank: 97th (active rank 89th)
Votes: 3,664 MVests
Voter count: 128
Producer rewards (7 days): 23.33 HP
Producer rewards (30 days): 103.79 HP
Missed blocks: 1
Server resource statistics
This section will be present in every witness update logs (if any of my nodes are online) to provide new witnesses up-to-date information about the system requirements for running a Hive node.
hived (v1.24.7, MIRA)
block_log file size: 305 GB
blockchain folder size: 739 GB
Account history RocksDB size: 423 GB
RAM usage: 4.3 GB
I know v1.24.8 is out but I can't afford another 36 hours of replay time as there will be another release that will also require another replay🤦♂️
hivemind (ef9fe6ae)
Output of SELECT pg_size_pretty( pg_database_size('hive') );
Database size: 554 GB
Hivemind RAM usage: 1.6 GB
Postgresql RAM usage (estimated): 13 GB
I'm still in the process of sorting out server monitoring so more on that in later witness update logs.
